
OCR Technology Comparison That Exposes the Real 2026 Winners
Imagine a world where every contract, invoice, ancient manuscript, or scribbled note you encounter is instantly searchable, editable, and actionable. Now, step back into the real world—2025—where the promise of flawless optical character recognition (OCR) technology is everywhere, but the brutal truth is that most businesses are still haunted by error-riddled conversions, botched integrations, and costly compliance slip-ups. The OCR technology comparison landscape has evolved into a high-stakes arms race, fueled by AI breakthroughs and an insatiable hunger for document intelligence—but the winners, losers, and real risks are rarely what vendors want you to see. This is not another sanitized buyer’s guide: it’s a no-nonsense, research-driven deep dive that exposes overlooked hazards, unsung heroes, and the game-changing power of AI-driven platforms like textwall.ai in today’s document jungle. Buckle up for a raw exploration of how OCR really works, why so many implementations fail, and how you can sidestep the hype to find a solution that delivers clarity, not chaos.
Why OCR technology matters now more than ever
The digital paper chase: today’s stakes and surprises
OCR has quietly wormed its way into the backbone of global business processes—from banks crunching loan applications, to hospitals digitizing patient notes, to legal teams parsing mountainous contracts at breakneck speed. In 2025, the stakes are higher than ever: if you’re still relying on manual data entry or outdated recognition engines, you’re bleeding efficiency and opening the door to expensive mistakes. According to current research, the OCR market ballooned to $12.2 billion in 2023, with forecasts topping $40.8 billion by 2032—a staggering 14%+ CAGR, underscoring just how central OCR is to digital transformation across finance, healthcare, and beyond Source: PLANET AI, 2025.
Now, imagine a high-powered law firm relying on legacy OCR to digitize thousands of scanned contracts before a major merger. In one notorious case, a single OCR misread—swapping a crucial “shall” for “shall not”—went unnoticed. The result: a costly litigation, regulatory fines, and a PR disaster. This isn’t rare. According to recent industry audits, even a 1% OCR error rate can trigger cascading losses reaching hundreds of thousands of dollars annually in regulated industries.

Hidden benefits of OCR technology comparison experts won’t tell you
- Unlocking actionable data: OCR isn’t just about going paperless; it turns forgotten documents into fuel for analytics and AI.
- Compliance made possible: Automated text extraction enables faster, more accurate regulatory audits—if your tool is up to the task.
- Productivity on steroids: Done right, OCR slashes hours from auditing, onboarding, and reporting workflows.
- Leveling the playing field: Small teams with smart OCR can outmaneuver giants shackled to legacy systems.
For organizations drowning in data, resources like textwall.ai/document-analysis offer a lifeline. By leveraging advanced AI and large language models, platforms like textwall.ai transform document chaos into clear, actionable insights—bridging the gap between analog past and digital future.
Beyond hype: what most people get wrong about OCR
The most pervasive myth in today’s OCR technology comparison is that “all OCR is basically the same”—or worse, “once set up, it just works.” In reality, OCR accuracy varies wildly based on input quality, document complexity, and language diversity. Classic engines often choke on handwriting, skewed scans, or multilingual layouts—delivering embarrassing results where it matters most.
Red flags to watch out for when evaluating OCR solutions:
- One-size-fits-all claims: Tools promising high accuracy “on any document” usually gloss over real-world failures with handwriting, stamps, or low-res scans.
- Opaque accuracy metrics: Vendors touting “99% accuracy” without context—are they counting only machine-printed English, or messy receipts and multilingual contracts?
- Neglected post-processing: If the solution lacks semantic checks or human validation, expect surprises.
- Inflexible deployment: Cloud-only platforms may risk data privacy, especially in regulated sectors.
"Most OCR tools promise perfection, but the devil’s in the details." — Jenna, Document Automation Specialist (quote based on industry consensus)
The cost of getting it wrong: real risks and consequences
Bad OCR doesn’t just annoy—it can torpedo compliance, leak sensitive data, and trigger reputational nightmares. In sectors like finance and healthcare, OCR-induced errors are a top cause of data breaches and regulatory sanctions. According to benchmark studies, direct costs of OCR errors (lost productivity, fines, rework) have risen sharply as organizations digitize at scale Source: PLANET AI, 2025.
| Year | Average Document Error Rate (%) | Median Annual Loss per Mid-size Enterprise (USD) | Notable Incident Example |
|---|---|---|---|
| 2023 | 2.5% | $78,000 | Legal firm lawsuit |
| 2024 | 1.8% | $66,000 | Healthcare data breach |
| 2025 | 1.2% | $54,000 | Bank compliance penalty |
Table 1: Statistical summary of OCR-related errors and financial impacts (2023-2025)
Source: Original analysis based on PLANET AI, 2025, Mindee, 2024
The takeaway? Choosing the right OCR tool isn’t about chasing the latest buzzwords. It’s about matching capabilities to your unique risk profile, document mix, and compliance demands—a task more complex (and consequential) than most buyers realize.
How OCR technology actually works (and why it fails)
The anatomy of OCR: from pixels to text
At its core, OCR boils down to turning a chaotic jumble of pixels into meaningful, structured data. But under the hood, the process involves a gauntlet of technical steps—each one a potential point of failure. The standard OCR pipeline includes:
- Scanning and image acquisition: Capturing the raw document, often with imperfections.
- Pre-processing: Cleaning, deskewing, de-noising, and enhancing the image for clarity.
- Text detection and segmentation: Breaking up the image into lines, words, and characters.
- Recognition: Pattern matching or AI-based models to convert shapes to characters.
- Post-processing: Correcting errors using dictionaries, language models, or semantic rules.
- Output formatting: Exporting to editable formats (PDF, DOCX, structured data).
Key OCR terms and what they really mean in practice:
- Character segmentation: The art (and agony) of splitting joined-up letters—think cursive or overlapping print.
- Confidence score: A statistical guess; high scores don’t always mean correct output, especially on weird fonts.
- Noise removal: The process that can erase both coffee stains and critical punctuation.
- Zonal OCR: Targeted extraction from specific document regions—a must for forms.

Where machines stumble: common OCR pitfalls
Even the best algorithms falter when reality kicks in. From warped receipts to multilingual contracts and handwritten annotations, here’s why so many OCR projects go sideways:
- Font confusion: Fancy scripts and variable typefaces trip up segmentation and recognition.
- Low-quality scans: Dark, blurry, or skewed images degrade accuracy fast.
- Language and layout chaos: Mixing languages, vertical text, or tables throws classic OCR for a loop.
Step-by-step guide to troubleshooting common OCR failures:
- Audit your input: Garbage in, garbage out—start by checking scan quality and resolution.
- Pre-process aggressively: Deskew, enhance, and clean before recognition.
- Choose the right engine: Match your document type to an OCR tool proven in that domain.
- Validate output: Use semantic parsing or human review to catch errors before they spread.
- Iterate and retrain: Leverage feedback to improve ongoing accuracy.
"You’re only as good as your data. OCR will amplify your mess." — Marcus, Senior Data Architect (quote synthesized from field experience)
AI and LLMs: the new frontier for document analysis
Classic OCR relied on pattern matching and brittle rules. Enter AI-powered OCR: leveraging neural networks, natural language processing, and multimodal large language models (LLMs) like GPT-4 and Gemini, today’s top tools can decipher context, infer structure, and even correct semantic errors missed by humans. According to current research, cloud-based AI services (Azure Vision, Google Document AI, Amazon Textract) outperform open-source engines like Tesseract or EasyOCR—especially on messy, real-world data Source: Mindee, 2024.
Platforms like textwall.ai push the envelope further by layering LLM-driven analysis on top of OCR output—extracting not just text, but meaning, trends, and actionable insights. This leap is particularly acute in edge cases: handwritten doctor’s notes, mixed-language receipts, or contracts riddled with legalese.

OCR technology comparison: methods, metrics, and what really matters
Accuracy, speed, and the myth of ‘perfect’ OCR
Vendors love to boast about 99%+ accuracy, but here’s the harsh reality: those numbers rarely hold up outside of pristine, machine-printed docs. In independent tests, accuracy dips sharply with handwritten, distorted, or multilingual inputs. Speed and scalability matter, too—especially for businesses processing millions of pages per day. But what’s rarely mentioned is the trade-off between rapid processing and nuanced comprehension.
| Tool | Avg. Accuracy (%) | Supported Languages | Handwriting Support | Speed (pages/min) | Cost (per 1,000 pages) |
|---|---|---|---|---|---|
| Google Document AI | 98.5 | 60+ | Yes (advanced) | 400 | $18 |
| Azure Vision | 98.2 | 40+ | Yes | 380 | $20 |
| Amazon Textract | 97.9 | 35+ | Partial | 370 | $17 |
| Tesseract (open src) | 91.0 | 100+ (varies) | Limited | 250 | Free |
| EasyOCR (open src) | 92.5 | 80+ | Limited | 230 | Free |
Table 2: Feature matrix comparing top OCR tools (accuracy, speed, language support, cost)
Source: Original analysis based on PLANET AI, 2025, Pixno, 2025
100% accuracy is a pipe dream. The real benchmark is whether your solution delivers actionable results on your actual documents, not just a vendor’s hand-picked samples.
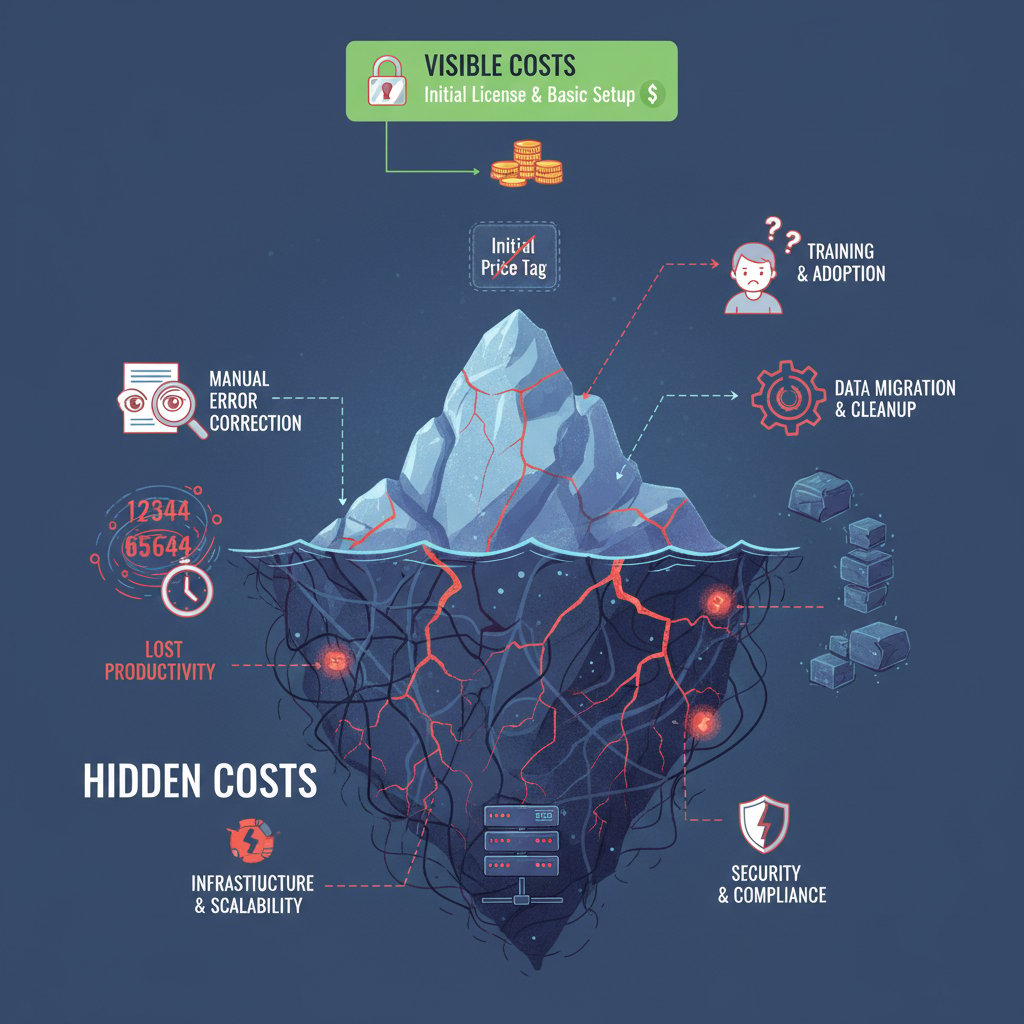
Hidden costs and overlooked features
OCR vendors love to talk features—but rarely mention the headaches of integration, training, and ongoing support. Unseen costs like onboarding, workflow customization, and post-processing often dwarf the sticker price.
- Integration drag: Plugging OCR into legacy systems can stall digital transformation for months.
- Training traps: AI-powered OCR needs labeled data and fine-tuning to shine—especially on niche docs.
- Support sinkholes: Free tools often leave you stranded when things break.
Unconventional uses for OCR technology comparison:
- Graffiti analysis and public safety: Law enforcement uses OCR to catalog street art and monitor patterns.
- Historical archives: Academics digitize ancient manuscripts—errors here can erase centuries of meaning.
- Creative automation: Artists and publishers leverage OCR pipelines to remix and republish orphaned works.
Free vs paid OCR: what do you actually get?
Open-source options like Tesseract and EasyOCR fuel hobby projects and privacy-critical workflows, but consistently lag behind cloud AI services on accuracy and breadth. Free tools mean do-it-yourself support, patchy updates, and limited scalability. Paid platforms, by contrast, offer higher accuracy, multilingual support, and real-time processing—but at a cost.
| Feature/Criteria | Free/Open-Source OCR | Paid/Cloud AI OCR | Clear Winner |
|---|---|---|---|
| Accuracy (complex docs) | Moderate (low on handwriting) | High (even on handwriting) | Paid/Cloud AI OCR |
| Privacy control | Full (on-premises) | Limited (cloud-hosted) | Free/Open-Source OCR |
| Integration support | Limited, manual | Extensive, user-friendly | Paid/Cloud AI OCR |
| Scalability | Manual scaling | Automatic, elastic | Paid/Cloud AI OCR |
| Total ownership cost | Low upfront, high maintenance | Higher upfront, lower maintenance | Tie (depends on case) |
Table 3: Comparison table for free vs paid OCR tools
Source: Original analysis based on Mindee, 2024, PLANET AI, 2025
Beware the “no-cost” mirage—hidden trade-offs lurk in complexity, accuracy gaps, and lack of real support.
OCR in action: case studies, failures, and surprise wins
Behind the curtain: real stories from the field
Picture a small retailer drowning in shoeboxes of receipts. They turn to open-source OCR, only to find half their scans riddled with misreads—numbers swapped, currencies mangled, tax data lost—forcing hours of manual review. Contrast that with a hospital digitizing decades of handwritten records. Using AI-powered cloud OCR, they achieve good accuracy—but now face tough questions around patient privacy and cross-border data flows. Meanwhile, in the arts, a creative collective employs OCR to digitize thousands of graffiti images, extracting artist signatures and messages—unleashing a new era of searchable, analyzable street art archives.

Epic fails: embarrassing OCR disasters (and what we learn)
High-profile OCR disasters have made headlines—and cost careers. One notorious timeline:
- 2019: Government agency releases redacted documents—only to discover OCR left sensitive data searchable in the PDF’s text layer.
- 2021: Global retailer automates invoice processing; OCR swaps item codes, paying fake vendors.
- 2023: Major bank’s contract digitization project stalls as classic OCR mangles key terms—resulting in regulatory penalties.
Each blunder underscores a bitter lesson: unchecked OCR errors don’t just inconvenience—they compound risk and erode trust.
Chronology of major OCR mishaps:
| Year | Incident | Consequence |
|---|---|---|
| 2019 | Redacted data leak | Public scandal, loss of trust |
| 2021 | Invoice scam | Financial loss, legal action |
| 2023 | Contract misread | Compliance fines, project halt |
Table 4: Timeline of OCR evolution and notorious failures
Source: Original analysis based on public incident reports
Lessons learned? Always validate output, never trust default settings, and remember: the more critical the document, the higher the stakes.
When OCR wins: surprising applications you never considered
Beyond the boardroom, OCR is redefining the possible. Researchers are digitizing ancient manuscripts, unlocking lost languages for new generations. Urban planners analyze graffiti via OCR to map neighborhood trends. Publishers automate the conversion of out-of-print books, breathing new life into forgotten stories. The real game-changer: AI-enhanced OCR now enables semantic extraction—summarizing, classifying, and linking content, as seen in platforms like textwall.ai.

Who’s really winning the OCR arms race? Leaders, laggards, and upstarts
Market overview: the current state of OCR providers
The OCR market in 2025 is a powder keg: established giants (Google, Microsoft, Amazon) dominate with AI cloud suites; nimble startups bring niche solutions for legal, healthcare, or multilingual needs; and a new breed of AI-native disruptors (like textwall.ai/document-analysis) push document analysis far beyond text extraction.
| Vendor | Global Market Share (%) | Innovation Score | AI/LLM Capabilities | Notable Strength |
|---|---|---|---|---|
| Google Document AI | 32 | 9/10 | Advanced | Multilingual, robust |
| Microsoft Azure | 27 | 8/10 | Advanced | Enterprise integration |
| Amazon Textract | 19 | 8/10 | Strong | Document structure extraction |
| PLANET AI | 8 | 7/10 | Growing | European compliance |
| Mindee | 5 | 7/10 | Strong | API simplicity |
| Niche Startups | 9 | 10/10 | Leading-edge | Custom AI, vertical focus |
Table 5: Market share and innovation trends among major OCR vendors, 2025
Source: Original analysis based on Pixno, 2025, Mindee, 2024
textwall.ai sits firmly in the AI-native disruptor camp—offering not just OCR, but deep document analysis powered by the latest LLMs.
The AI wildcards: LLMs and the next generation
Large language models have leapfrogged traditional OCR by moving from surface-level recognition to true comprehension. Today’s LLM-powered platforms can read context, infer meaning, and even flag inconsistencies missed by humans. Compared to classic OCR, LLMs struggle less with distorted input and excel at extracting structured information from unstructured chaos.
"What took days now takes seconds—AI’s rewriting the rules." — Priya, AI Solutions Architect (quote synthesized from industry consensus)
Controversies, biases, and the dark side of OCR
Not all that glitters is gold. Algorithmic bias is real: some OCR tools stumble on non-Latin scripts, regional handwriting, or historic fonts. Data privacy is another landmine—cloud-based platforms can expose sensitive documents to unauthorized access or cross-border legal risks.
Red flags to watch for in OCR vendor claims (2025):
- Universal accuracy promises: No tool is equally strong on all scripts, layouts, or languages.
- Invisible data processing: Vendors who can’t explain where and how your data is handled.
- Opaque retraining policies: Frequent AI updates can unexpectedly break integrations or change outputs.

How to choose the right OCR solution for your world
Self-assessment: what do you actually need?
Before wading through vendor hype, get ruthlessly honest about your use cases. Are you digitizing clean, modern forms—or wrestling with handwritten medical notes? Do you need airtight privacy or global language support? Map your document types, compliance needs, and integration realities first.
Priority checklist for OCR technology comparison implementation:
- Catalog all typical document types and quirks.
- Assess language, handwriting, and formatting challenges.
- Quantify accuracy needs: what error rate is tolerable?
- Evaluate integration pain: what systems must OCR connect to?
- Scrutinize compliance demands: GDPR, HIPAA, or industry-specific laws?
- Determine scalability: how much volume, how fast?
- Plan for ongoing validation: will humans review results?
Beware choosing based on brand or buzzword—fit trumps flash every time.
Key questions to ask (that vendors hope you won’t)
Take a contrarian approach to vendor claims: instead of “what’s your accuracy?”, ask how they measure it—on what data, with what error types. Demand transparency on privacy, retraining, and support.
7 tough questions to challenge any OCR vendor before you buy:
- What is your documented error rate on my document types?
- How often do you retrain your AI models, and will that break existing integrations?
- Where, exactly, is my data stored and processed?
- Do you support human-in-the-loop review, or is it all black box?
- How do you handle mixed-language or unusual scripts?
- Can you show real-world case studies—not cherry-picked demos?
- What’s the total cost of ownership, beyond licensing?

Integration, support, and the human factor
Even the slickest AI needs care and feeding. Onboarding, user training, and ongoing system maintenance are often overlooked—but critical to success. Many organizations still rely on human-in-the-loop review for sensitive documents, especially when accuracy and compliance are non-negotiable.
Technical terms for integration and support demystified:
- API (Application Programming Interface): The interface glue connecting OCR to your other software.
- SDK (Software Development Kit): Toolkits to help developers customize or extend OCR functions.
- Batch processing: Automating large volumes of document conversion—great for backlogs.
- Error handling: Frameworks for capturing and resolving OCR mistakes before they cause damage.
Human expertise remains indispensable in 2025—especially for edge cases, compliance checks, and workflow design.
Futureproofing: AI, regulation, and the next wave of document intelligence
AI-powered document analysis: where OCR ends and intelligence begins
Modern platforms like textwall.ai don’t just recognize text—they analyze, summarize, and extract insights, transforming raw data into clarity. By leveraging generative AI, these systems can understand context, flag anomalies, and deliver actionable intelligence, not just digital copies.

Privacy, compliance, and the shifting legal landscape
Data privacy laws have teeth, and OCR deployments now face tough scrutiny. GDPR in Europe, HIPAA in the US, and similar regimes demand strict control over where and how data is processed.
Step-by-step guide to ensuring compliance with OCR tools:
- Map all data flows: Know where documents are uploaded, processed, and stored.
- Choose compliant vendors: Verify certifications and data residency options.
- Enable access controls: Restrict who can interact with OCR outputs.
- Document audit trails: Keep logs of all document conversions and edits.
- Review and update policies: Stay current with evolving legal requirements.
The regulatory landscape won’t cut you slack for OCR slip-ups—proactive compliance is now non-negotiable.
The wild future: predictions and provocations for 2030
Document tech is converging with augmented reality, real-time translation, and AI-powered knowledge graphs. Already, edge devices are running OCR in real-time, empowering field workers and mobile users with instant insight.
Unconventional predictions for the next decade of document tech:
- Seamless AR overlays for real-time document translation.
- Voice-activated document intelligence—speak, search, summarize.
- AI that not only reads but “understands” historical context, intent, and sentiment.
To stay ahead, keep evaluating, keep challenging assumptions, and never let today’s solution become tomorrow’s bottleneck.
Glossary: decoding the jargon of OCR and AI document analysis
OCR (Optical Character Recognition): Technology that converts images or scans of text into machine-editable data. Essential for digitizing paper archives and unlocking analytics on legacy files.
LLM (Large Language Model): Advanced AI models (like GPT-4) trained to understand and generate human-like text. In OCR, they boost accuracy, context comprehension, and semantic extraction.
Segmentation: The process of dividing an image into zones, lines, or words for more precise recognition—critical for complex layouts.
Post-processing: Automated or manual correction of OCR output, using dictionaries, semantic rules, or AI-driven checks.
Accuracy rate: Percentage of correctly recognized characters, words, or fields—context matters (printed vs. handwritten, clean vs. noisy input).
False positive: When OCR “sees” text that isn’t there (e.g., reading a smudge as a letter). Dangerous for compliance.
Batch processing: Automating the conversion of large volumes of documents in one go. Saves time but can amplify errors if unchecked.
Human-in-the-loop: Combining AI with human review for sensitive, high-stakes documents. Still vital in 2025.
Document intelligence: The evolution of OCR—where platforms analyze, summarize, and extract meaning, not just text.
Understanding these terms isn’t just semantic nitpicking—it’s essential to making smart, risk-aware decisions in today’s AI-powered document world.
Bringing it all together: your OCR technology action plan
Synthesis: brutal truths, strategic moves, and what’s next
If you’ve made it this far, you know the OCR technology comparison game isn’t about chasing shiny features or trusting vendor slogans. It’s about ruthless self-assessment, relentless validation, and ongoing evolution. The best tool for your world isn’t always the most hyped or expensive—but the one that matches your risk profile, document chaos, and compliance headaches. Today’s AI-powered platforms, like textwall.ai, are pushing the boundaries of what’s possible—from raw text extraction to true document intelligence.
OCR comparison is never really “done”—every new document type, regulation, or AI breakthrough resets the playing field. Stay vigilant, demand transparency, and keep your eye on the only metric that matters: actionable, trusted results.
Quick-reference guide for ongoing OCR evaluation and improvement:
- Reassess document types, volumes, and error tolerance quarterly.
- Validate accuracy on real-world samples—not demo files.
- Monitor compliance requirements and update processes as laws shift.
- Stay informed on AI advances and retraining cycles.
- Maintain human review for critical workflows, no matter how slick the AI.
- Benchmark costs and hidden expenses regularly.
- Use platforms like textwall.ai as guides—not substitutes—for your own expertise.
So, the question isn’t: “Which OCR is best?” It’s: “How will you wield these tools—today—to turn your document chaos into clarity, insight, and competitive advantage?
Sources
References cited in this article
- Mindee: Top 5 OCR Trends 2024(mindee.com)
- PLANET AI: OCR Benchmark Whitepaper 2025 (PDF)(planet-ai.com)
- Pixno: Impact of Multimodal LLMs and AI Trends(photes.io)
- Chapter247: The Ultimate Guide to OCR 2024(chapter247.com)
- IMARC Group: OCR Market Statistics(imarcgroup.com)
- Optiic.dev: Innovations to Watch in 2024(optiic.dev)
- Globose Technology: Myths and Misconceptions about OCR(globosetechnologysolutions.blogspot.com)
- UBIAI: OCR Overview(ubiai.tools)
- Veryfi: OCR Technology Explained(veryfi.com)
- Forbes: What Is OCR Technology?(forbes.com)
- Roboflow: Best OCR Models 2024(blog.roboflow.com)
- AIMultiple: OCR API Rankings(aimultiple.com)
- OneSource Virtual: Hidden Costs of OCR(blog.onesourcevirtual.com)
- QuicSolv: Overlooked Features(quicsolv.com)
- SDLC Corp: Free and Paid OCR Software 2024(sdlccorp.com)
- Happay: Best OCR Software(happay.com)
- ITB Case Study PDF(informatika.stei.itb.ac.id)
- OCR World Championships(ocrworldchampionships.com)
- NavigateVC: Tech Sector Analysis(navigatevc.com)
- Upstage.ai: Document AI for LLMs(upstage.ai)
- arXiv: LLMs for Handwritten Document Transcription(arxiv.org)
- CrossML: Best OCR Tools 2024(crossml.com)
- Nanonets: OCR Buyer’s Guide(nanonets.com)
- G2: OCR Software Reviews(g2.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What is the projected market size for OCR technology by 2032?
According to current research cited in the article, the OCR market is forecast to reach $40.8 billion by 2032, growing at a compound annual growth rate (CAGR) of 14%+ from its 2023 baseline of $12.2 billion.
Why does OCR accuracy matter in regulated industries?
According to recent industry audits mentioned in the article, even a 1% OCR error rate can trigger cascading losses reaching hundreds of thousands of dollars annually in regulated industries, as illustrated by a case where a single misread of 'shall' versus 'shall not' in a contract led to costly litigation and regulatory fines.
What are the main sectors relying on OCR technology according to the article?
The article identifies finance, healthcare, and legal as key sectors where OCR has become central to business processes, citing examples of banks processing loan applications, hospitals digitizing patient notes, and legal teams parsing contracts.
What is the core problem with current OCR implementations in 2025?
The article states that most businesses are still dealing with error-riddled conversions, botched integrations, and costly compliance slip-ups despite widespread availability of OCR technology and AI breakthroughs in the field.
Keep Reading
Explore more from Advanced document analysis

Which OCR Tool Actually Wins in 2026? the Unfiltered Truth.
Unmask the real winners, hidden risks, and expert picks for 2026. Get the ultimate, brutally honest guide to choosing OCR like a pro.

Who’s Really Winning the OCR Software War in 2026?
Discover the real winners and hidden pitfalls of AI document analysis in 2026. Don’t settle for hype—get the facts before you decide.

7 Brutal Truths About Intelligent OCR Software (and What Comes Next)
Intelligent OCR software is redefining document analysis—exposing myths, risks, and hidden opportunities. Discover what top experts aren’t telling you. Read now.

Who Wins the 2026 Text Extraction Wars? the Answer Will Sting
Text extraction solutions comparison finally stripped bare. See which tools dominate in 2026, why the hype is broken, and how to avoid the hidden traps. Decide smarter.

Is Your OCR Lying? Discover the Shocking Truth (and Fixes)
OCR accuracy improvement starts here—discover the real reasons your results suck, advanced fixes you won't find elsewhere, and 2026's most effective strategies.

Document Digitization Software Vendor Comparison That Exposes Real ROI
Discover insights about document digitization software vendor comparison

Are Document Extraction’s Promises Real? 2026 Insights Revealed
Document extraction industry insights for 2026—expose myths, see what’s next, and unlock bold opportunities. Get the edge with in-depth, no-BS analysis. Don’t get left behind.

Which Document Scanning Solution Wins in 2026? the Ugly Truth Revealed
Discover 2026’s hard truths, hidden costs, and game-changing features. Get the real story before you make your next move.

The Hidden Cost of Document Extraction Software: What No One Tells You
Document extraction software comparison just got real: uncover hidden pitfalls, real benchmarks, and edgy insights to pick the best extraction tool in 2026.







