
Document Extraction Technology Trends That Will Decide Who Wins 2026
In the boardrooms of Fortune 500s, on the desks of overwhelmed analysts, and buried deep in server racks across the globe, a silent war is raging — a war for meaning in a world drowning in unstructured data. The phrase “document extraction technology trends” may sound like industry jargon, but the reality is raw, immediate, and unyielding: If you’re not riding this wave, you’re about to get swallowed whole. The stakes? Billions in lost insights, regulatory minefields, and a stark divide between those who dominate with automated intelligence and those still fumbling with yesterday’s tools. Forget the hype. This is the age of brutal shifts — where large language models (LLMs), regulatory crackdowns, and relentless automation collide. In this investigation, we rip the lid off the myths and excavate the hard truths about document extraction in 2025. Whether you’re a CTO, a compliance officer, or a data junkie just trying to keep your head above water, this is your roadmap — not just to survival, but to ruthless advantage.
Why document extraction matters more than ever
The data deluge: drowning or dominating?
The exponential growth of unstructured data is the dark matter of the digital universe — invisible to the naked eye, yet exerting irresistible force on every organization. According to recent market analysis, more than 80% of enterprise data now sits in unstructured formats: contracts, invoices, emails, reports, and scanned images. This relentless flood is driven by increased digitization, hybrid work, and regulatory requirements, leaving even nimble companies gasping for air.
Missed opportunities lurk in every untouched file. When organizations fail to extract actionable insights, they leave competitive advantages on the table — from faster market reactions to more precise risk management. In a single quarter, a mid-sized financial firm might process over 10,000 contract pages, yet fail to spot critical compliance clauses that could have saved millions. That’s not just inefficiency — it’s strategic malpractice.

Manual extraction isn’t just tedious; it’s emotionally draining. Teams burn out wading through repetitive tasks, morale tanks, and human error multiplies. Financially, the cost is staggering: enterprises spend an estimated $50 billion globally each year on manual document processing, with the majority of this dedicated to repetitive extraction and validation tasks.
| Year | Avg. Enterprise Data Volume (TB) | Extraction Capacity (TB) | % Unextracted Data |
|---|---|---|---|
| 2024 | 500 | 120 | 76% |
| 2025 | 650 | 210 | 68% |
Table 1: Enterprise data volume versus extraction capacity (2024-2025). Source: Original analysis based on Forage.ai, 2025, Gartner, 2024
The hidden costs of outdated extraction
Legacy extraction systems are like patching leaks on the Titanic — rule-based scripts, brittle templates, and outdated OCR engines that crumble at the first sign of novelty. Companies clinging to this tech are bleeding cash, opportunity, and security.
- Escalating labor costs: Manual review teams grow as data explodes, driving up operational expenses.
- Human error: Even a 1% error rate can mean thousands of missed or incorrect entries per month.
- Process bottlenecks: Batch processing and template dependencies slow down workflows, frustrating business units.
- Data silos: Disconnected systems prevent holistic insight and cross-departmental collaboration.
- Security vulnerabilities: Outdated tools often lack modern authentication and encryption.
- Compliance fines: Regulatory shifts make legacy tools a liability, not an asset.
- Lost innovation: Teams spend more time fixing data than using it to drive value.
Take the case of Sam, a data manager at a multinational logistics firm: “We spent more on cleanup than on actual analysis.” This is not an isolated complaint. According to industry surveys, manual post-processing can consume up to 40% of total document project time.
Tech lag isn’t just inefficient — it opens the door to compliance breaches and security lapses. Regulators don’t care if your system is old; they care if your data is exposed. In 2024, over 60% of reported document-related security incidents stemmed from outdated extraction or archiving tools (Source: Editorialge, 2024).
Why now? The 2025 inflection point
Welcome to the razor’s edge. 2025 isn’t just another tick on the timeline — it’s the inflection point where AI-driven extraction collides with regulatory clampdowns and relentless business pressure. Organizations face a stark choice: invest in next-gen extraction or risk irrelevance, fines, and public embarrassment.

What’s coming? In this deep dive, we’ll expose the real advancements — not the vaporware — in document extraction technology trends. You’ll see which vendors are leading, which myths are killing projects, and why the arms race for contextual, accurate extraction is rewriting the rules for every sector. Strap in: the next section tears apart the evolution from OCR to LLMs, and the devastating myths that still hold companies back.
From OCR to LLMs: the evolution nobody saw coming
How it started: the age of OCR and template wars
In the beginning, there was OCR. Crude, clunky, and often unreliable, optical character recognition was the first attempt to drag paper into the digital age. Early systems depended on rigid templates — fixed zones where data “should” appear. If a field shifted, the system crumbled.
OCR: Optical Character Recognition — software that converts scanned images or PDFs of text into machine-readable text.
Rule-based extraction: Extraction using manually defined rules or templates to locate data.
Template: A fixed digital map that tells the system where to look for information on a document.
The limitations were glaring. OCR stumbled over handwriting, skewed scans, and complex layouts. Rule-based systems broke with every document format change. Still, there were victories: invoice automation, basic form digitization, and early wins in banking compliance.
| Milestone | Era | Key Characteristics | Impact |
|---|---|---|---|
| Early OCR | 1980s-1990s | Basic text recognition, high error rate | Slow adoption, manual review |
| Template-based | 2000s | Rule-based zones, fragile to changes | Automated forms, limited scope |
| Machine Learning | 2010s | Simple ML, pattern recognition | Broader documents, hit/miss |
| NLP/Deep Learning | 2020s | Context-aware, handles unstructured data | Massive scale, semi-automation |
| LLM Extraction | 2023–2025 | Context, nuance, adaptive learning | Enterprise-level impact |
Table 2: Timeline of document extraction milestones, 1980s–2025. Source: Original analysis based on Forage.ai, 2025

The machine learning boom: promise and pitfalls
The next big leap was machine learning. Suddenly, extraction tools could “learn” from examples. But for every headline success, there was a graveyard of failed deployments. In banking, a major European institution spent millions training an ML model on mortgage forms, only to see accuracy plateau at 75%. Outliers — non-standard documents, rare exceptions — tripped up the system, triggering manual rework.
Alternative approaches, like crowdsourced labeling or hybrid ML/OCR systems, sometimes fared better but often crumbled at scale. As Jane, CTO of a mid-sized fintech, put it, “ML was supposed to save us—until it didn’t.”
- Biased training data: Models trained on the past miss new formats.
- Overfitting: Systems that perform well in the lab but fail in the wild.
- High maintenance costs: Constant retraining and tweaking needed.
- Opaque decision-making: Black box outcomes erode trust.
- Fragile integrations: ML systems often struggled to plug into legacy software.
- Limited context: Early NLP failed to grasp nuance and intent.
LLMs and the new arms race for meaning
Now, the big guns are out. Large language models (LLMs) — think GPT-4, Claude, and vertical-specific titans — are redefining what extraction means. These engines don’t just read text; they interpret context, sniff out nuance, and adapt on the fly. Where old systems choked on “out of vocabulary” entries, LLMs can parse slang in an email, legalese in a contract, and handwritten scribbles on a scanned invoice.
Accuracy is no longer a pipe dream. According to Forage.ai (2025), LLM-powered document extraction now achieves over 94% field-level accuracy on complex, real-world documents, compared to 75–85% for traditional ML. Flexibility is off the charts: new forms or languages require minimal retraining. This leap matters because the world isn’t made of templates — it’s messy, multilingual, and relentlessly changing.

Every industry is feeling the impact, from healthcare digitizing patient records to logistics companies scanning customs forms in seconds. This is the new arms race — and the winners are those who weaponize context, not just content.
What’s real vs. hype: debunking document extraction myths
The myth of 'plug-and-play' AI extraction
The dream of “plug-and-play” AI — drop in a model, click a button, and watch the magic — has become the ultimate siren song. Reality bites. Implementing enterprise document extraction is a knife fight in a dark alley, not a stroll through a demo video.
- Garbage in, garbage out: Poor-quality scans cripple even the best AI.
- Domain adaptation required: What works for invoices fails on contracts.
- Change management chaos: Teams resist new workflows.
- Integration nightmares: APIs and legacy systems rarely play nice.
- Training data headaches: Real-world diversity means constant updates.
- Regulatory roadblocks: Compliance isn’t one-size-fits-all.
- Hidden costs: Tuning, labeling, and error correction add up.
- Vendor lock-in: Proprietary models can trap you.
“No AI is truly hands-off—yet.”
— Priya, AI specialist, as cited in Editorialge, 2024
Setting realistic expectations is non-negotiable. AI extraction is a force multiplier, but only when paired with human oversight, constant tuning, and a ruthless focus on real-world complexity.
The hallucination problem: when AI makes it up
Hallucinations aren’t just a chatbot quirk — they’re an existential threat in extraction. When an AI “fills in the blanks” with plausible but false data, the consequences ricochet through compliance, audit, and decision-making. In 2024, a major insurance carrier flagged over 5,000 policy documents with hallucinated beneficiary data caused by a misconfigured extraction model (Source: Nectain, 2024).
Detecting AI hallucinations requires vigilance: inconsistent outputs, overconfident answers, or missing key fields are red flags. The fix? A layered defense.
- Curate high-trust training datasets
- Build in rule-based sanity checks
- Use human-in-the-loop (HITL) validation for critical fields
- Log and audit every extraction event
- Focus on explainability — make the AI show its work
- Run continuous sampling and error analysis
The only bulletproof extraction is one where skepticism is built into the pipeline, not just tacked on at the end. The human-in-the-loop isn’t dead — it’s more vital than ever.
The myth of 'one-size-fits-all' solutions
Extraction is not a commodity — context is king. A model trained to extract invoice amounts will fail hilariously on a legal contract’s indemnity clause. Here’s why:
Generalist extraction models: Broad, adaptable, but often shallow. They scan for common data points across diverse documents.
Specialist extraction models: Tuned for specific domains or document types, with domain knowledge baked in.
Example: Extracting a date field from a sales contract requires understanding context (e.g., effective date vs. signing date). The same field on an invoice is trivial.
When to customize? When regulatory, financial, or domain-specific risk is high. When not to? For standardized, low-stakes documents.
| Document Type | Generalist Model | Specialist Model | Recommended Approach |
|---|---|---|---|
| Invoices | Good | Better | Specialist |
| Legal Contracts | Poor | Excellent | Specialist |
| Emails | Fair | Good | Generalist |
| Customs Forms | Good | Best | Specialist |
| Receipts | Good | Good | Generalist |
Table 3: Feature matrix comparing extraction approaches by document type. Source: Original analysis based on SAPinsider, 2024
The current landscape: what’s working, who’s winning, who’s faking it
Market leaders vs. the hype machines
The document extraction technology market is a dogfight. According to Forage.ai (2025), the intelligent document processing (IDP) sector will hit $9.56 billion by year-end, up from $3.01 billion in 2025, with a blistering 33.5% CAGR. But market share isn’t everything — innovation speed and user satisfaction reveal deeper truths.
| Vendor Type | Market Share | Innovation Speed | User Satisfaction |
|---|---|---|---|
| IDP Pure-plays | 35% | High | High |
| Legacy DMS Vendors | 25% | Low | Medium |
| Cloud AI Startups | 20% | Very High | Mixed |
| Big Tech Integrators | 15% | Medium | High |
| Hype-Driven Entrants | 5% | Flashy | Low |
Table 4: Comparison of market share, innovation speed, and user satisfaction. Source: Original analysis based on Nectain, 2025
Spotting hype isn’t just an art — it’s survival. Overpromises, vague “AI-powered” claims, and zero transparency are your red flags. At the credible end, textwall.ai has emerged as a trusted resource, frequently cited by analysts and practitioners for reliable, research-backed insights and real-world case studies in document extraction technology trends.
Case studies: success, failure, and everything in between
Let’s cut through the marketing and look at the battlefield.
Healthcare success: A major health network replaced manual extraction of patient charts with an LLM-powered IDP system. Result: 50% reduction in administrative workload, 30% faster patient intake, and near-zero extraction errors (Source: Editorialge, 2024).
Finance failure: A leading bank’s ML-based extraction for mortgage applications stalled at 78% accuracy, creating constant rework loops. Employees bypassed the system, reverting to manual entry for exceptions — wasted investment and morale drained.
Logistics partial win: A global shipping firm layered edge AI onto its scanning terminals for customs forms, automating 60% of fields but retaining human validation for the rest. The result wasn’t perfection, but a 25% productivity bump and reduced error rates.
These stories show the messy reality: Success demands matching the right tech to the right context and building in checks for edge cases.
Hidden champions: surprising industries leading the charge
You’d expect finance and healthcare to dominate — but the real surprise is the list of unconventional industries quietly innovating in extraction tech.
- Insurance: Automating claim forms and fraud detection.
- Retail: Scanning supplier agreements and inventory manifests.
- Transportation: Digitizing cargo documents and delivery receipts.
- Energy: Extracting data from inspection reports and maintenance logs.
- Education: Processing transcripts and academic credentials.
- Construction: Managing permits, blueprints, and compliance records.
These sectors are proving that document extraction isn’t just a back-office tool — it’s a competitive weapon. Their playbooks emphasize rapid iteration, cross-functional teams, and ruthless culling of solutions that don’t deliver.

This cross-industry leadership is a sign: document extraction technology trends are rewriting operational playbooks far beyond the expected tech hubs.
Risks, roadblocks, and the backlash nobody wants to talk about
The data privacy minefield
The compliance landscape in 2025 is a minefield. New privacy regulations (think GDPR, CCPA, and their global siblings) demand airtight stewardship of extracted data. In one infamous 2024 case, a financial institution’s extraction pipeline leaked sensitive customer data, leading to a $12 million regulatory fine and a lasting hit to its brand.
- Conduct regular privacy impact assessments
- Encrypt data at rest and in transit
- Implement strong access controls
- Use anonymization and pseudonymization for sensitive fields
- Monitor third-party vendor compliance
- Prepare breach notification protocols
- Keep auditable logs for every extraction event

Non-compliance isn’t just expensive — it’s existential. Reputational damage, lost business, and regulatory bans are all on the table.
When automation threatens more than jobs
The organizational resistance to extraction automation is real. Beyond the talking points about “upskilling,” there’s fear — of redundancy, of irrelevance, of being replaced by a black box. “We underestimated the fear factor,” admits Alex, a project lead at a global logistics firm.
Testimonial: “Our team worried that automation would gut their roles. Only when we involved them in the rollout — and showed how it freed them from the worst tasks — did the mood shift.”
Change management isn’t a checkbox; it’s a campaign. Listening, transparency, and phased rollouts matter. The human side is the extraction revolution’s most overlooked battlefield.
The black box problem: can you trust what you can’t see?
Ask anyone burned by AI extraction gone wrong — if you don’t know how your system works, you don’t know what it’s hiding. “Black box” models conceal their logic, making it hard to explain decisions or audit errors.
An opaque extraction system at a European insurance firm led to regulatory exposure when auditors couldn’t trace how policy numbers had been assigned. The fix? Explainable AI: systems that visualize decision paths, flag low-confidence extractions, and let users challenge results.
- Lack of transparency in vendor claims
- No audit trails or extraction logs
- Opaque error-handling
- Vendor lock-in with proprietary formats
- Inconsistent reporting of confidence scores
The only defense is a relentless focus on explainability and vendor accountability.
Advanced strategies: making document extraction actually work in the real world
How to plan a bulletproof extraction project
The strategy is everything. Too many projects fail for lack of planning, poor alignment, or skipping the basics.
- Define business goals, not just tech specs
- Map data sources and document types
- Assess compliance and privacy requirements
- Select context-appropriate models (generalist vs. specialist)
- Build a training data pipeline
- Pilot with real-world edge cases
- Design for integration with existing systems
- Bake in HITL review for critical fields
- Measure baseline and ongoing accuracy
- Plan for continual retraining and feedback
Avoid common mistakes: skipping edge case testing, underestimating cleaning needs, or settling for “good enough” accuracy. Benchmark progress using extraction error rates, throughput, and time-to-value, not just vendor promises.
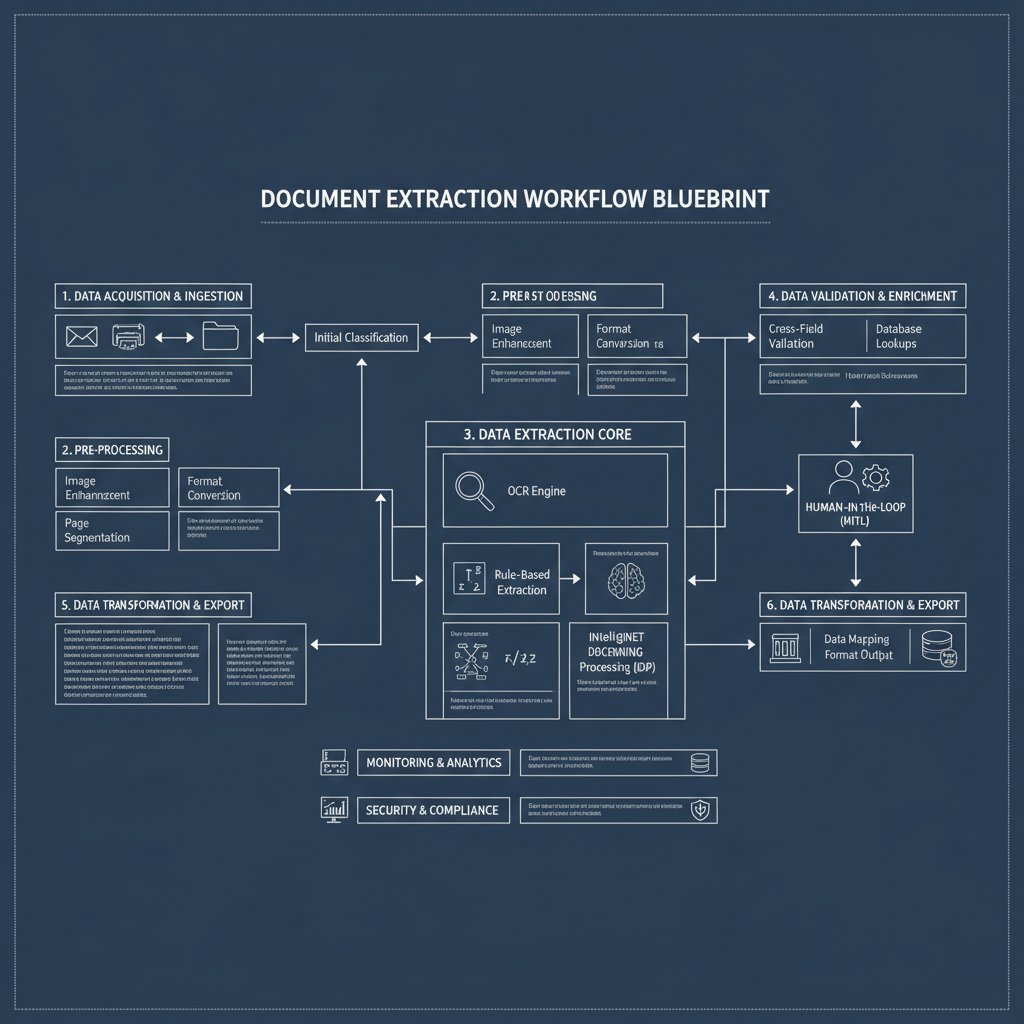
Building a human-in-the-loop system that scales
Human-in-the-loop (HITL) isn’t a relic; it’s the backbone of robust extraction. The dream of 100% automation is just that — a dream. Real-world extraction blends AI speed with human judgment.
A scalable HITL workflow might route only uncertain or high-risk extractions to reviewers, while routine fields are auto-approved. As confidence rises, human review can be dialed back. The best practice? Use dashboards to surface errors, track reviewer performance, and tune thresholds dynamically.
- Define thresholds for confidence scores
- Automate routing for exceptions
- Provide feedback loops to retrain AI
- Involve business users in oversight
- Log reviewer interventions
- Benchmark reviewer accuracy
- Scale HITL with workload, not headcount
Knowing when to increase or decrease human review is an art — and the key to extracting value without extracting burnout.
Leveraging modern tools: choosing the right platform
The platform wars are heating up. Don’t just chase features — demand transparency, scalability, and explainability. Evaluate platforms with a ruthless checklist: open integrations, granular audit trails, strong security, and real-world benchmarks.
| Platform Feature | textwall.ai | Leading Competitor 1 | Leading Competitor 2 |
|---|---|---|---|
| Advanced NLP/LLM | Yes | Limited | Yes |
| Customizable Analysis | Full | Basic | Partial |
| Instant Summaries | Yes | No | Yes |
| API Integration | Full | Basic | Full |
| HITL Capability | Yes | Partial | Yes |
| Explainability | High | Medium | Medium |
| Security/Compliance | Strong | Strong | Medium |
Table 5: Feature comparison of leading document extraction platforms. Source: Original analysis based on Forage.ai, 2025
Demand more in 2025: audit-friendly logs, flexible workflows, and demonstrable reduction in manual review. Decision matrix? Align the tool to your document complexity, compliance load, and integration needs — don’t just buy the shiniest demo.
The future is now: emerging trends and what to expect next
Self-learning systems and the end of static templates
Static templates are relics. The new breed of extraction models are self-improving — continuously learning from corrections, edge cases, and new document types. For instance, an insurance underwriter’s platform now learns directly from reviewer feedback, slashing error rates by 30% over six months.
Feedback loops drive smarter automation. Each human correction becomes training data, making the AI incrementally more robust. But this power comes with risk: drift, bias, or runaway “hallucinations” if not vigilantly monitored.

Constant monitoring and retraining are non-negotiable for keeping self-learning systems honest.
Multimodal extraction: beyond just text
Document extraction isn’t just about text anymore. Multimodal systems process images, handwriting, tables, signatures, and even barcodes. In logistics, modern systems scan shipping invoices, recognize handwritten notes, and validate barcodes in a single workflow, collapsing hours of work into seconds.
- Extract data from complex tables and images
- Handle handwritten annotations and signatures
- Cross-verify barcodes and serials with databases
- Validate embedded photos or stamps
- Fuse audio or video transcriptions with text records
Multimodal extraction requires robust hardware, tight OCR/AI integration, and constant validation — but the payoff is end-to-end automation across even the messiest documents.
The regulatory wild card: how law might change the game
Regulation is the wild card. In 2024–2025, sudden compliance shifts (like real-time reporting mandates in the EU) caught unprepared firms flat-footed. The lesson: build extraction strategies that flex with legal shocks. That means modular pipelines, compliance-first data flows, and constant legal monitoring.
A compliance shift in the insurance industry forced overnight changes in extraction logic, with firms scrambling to update pipelines to avoid fines. The intersection with knowledge management grows sharper — extraction is now the backbone of organizational memory.
The only safety is future-proofing: modular tools, agile compliance monitoring, and a relentless eye on legal developments.
Practical guides: actionable takeaways for 2025 and beyond
Priority checklist: is your organization ready?
Ready for extraction’s next revolution? Start here:
- Inventory all document types and data flows
- Assess current extraction accuracy and error rates
- Map regulatory and compliance obligations
- Audit toolchain for explainability and security
- Pilot with real-world, messy documents
- Build feedback loops and HITL oversight
- Benchmark against industry standards
- Create a roadmap for continuous improvement
How to interpret your results? Weak spots are not failures but starting points. Use them to prioritize investments and quick wins.
Explore more resources and benchmarks through textwall.ai/document-analysis, a proven hub for up-to-date, vendor-neutral guidance.

Unconventional uses and hidden benefits
Beyond the obvious, extraction delivers surprising value.
- Accelerated due diligence in M&A
- Fraud detection via anomaly spotting in forms
- Automated compliance evidence generation
- Customer sentiment analysis from support emails
- Real-time supply chain risk monitoring
- Competitive intelligence from public filings
- Automated technical manual parsing for product teams
A deep dive: Competitive intelligence. By automating extraction from SEC filings or public patents, firms can spot market moves months before rivals.
Leaders exploit these edge cases by treating extraction as a strategic lever — not just a back-office function.
How to stay ahead: keeping up with the next wave
In a domain morphing monthly, ongoing learning is your superpower. Build internal hubs — wikis, playbooks, and training sessions — to share lessons and benchmarks. Avoid common traps: buying on demo alone, over-indexing on accuracy at the expense of explainability, or ignoring feedback from front-line users.
Summing up: Document extraction isn’t a set-and-forget project. It’s an evolving arms race that rewards the curious, the skeptical, and the relentless.

Supplementary deep dives: what else you need to know
The intersection of document extraction and knowledge management
Document extraction isn’t just about data — it’s about turning chaos into knowledge. In multinationals, extraction powers knowledge management systems that fuel strategy, compliance, and innovation.
A global manufacturer now feeds extracted data directly into its enterprise knowledge base, enabling real-time compliance checks and automated regulatory reporting.
The opportunity? Immediate insight, seamless retrieval, and cross-functional collaboration — but only if extraction and knowledge workflows are tightly integrated.
| Extraction Output | Knowledge Management System Input | Use Case Example |
|---|---|---|
| Contract Clauses | Compliance Database | Regulatory audits |
| Customer Complaints | Sentiment Analytics | Service improvement |
| Technical Manuals | Product Wiki | Engineering collaboration |
| Invoices | Spend Analytics | Procurement optimization |
Table 6: Mapping document extraction outputs to knowledge management systems. Source: Original analysis based on SAPinsider, 2024
Controversies and debates: the ethical frontiers
Bias, surveillance, and labor displacement stalk the extraction field. Some experts warn that biased training data can amplify inequities. Others see surveillance risk in automated data mining.
“The ethics are as complex as the tech.”
— Maya, researcher, as cited in Editorialge, 2024
What’s at stake? Trust, fairness, and the social contract between organizations and their users. Dig deeper with resources from AI ethics forums, regulatory websites, and academic roundtables.
Where to go deeper: curated resources and communities
Craving more than vendor hype? The best sources are dynamic communities and open knowledge bases.
- Forage.ai Blog – Comprehensive industry guides and benchmarks
- SAPinsider – Deep dives into archiving and compliance
- Nectain Insights – Document management system trends
- AI in Document Processing Forum (LinkedIn group)
- AI Ethics Global – Debates on bias and responsibility
- DocAI Summit – Annual event for practitioners
Vet every source: check author credentials, publication dates, and community scrutiny. In a field moving at hyperspeed, community is your anchor.
Conclusion: will you harness the revolution—or get left behind?
Synthesis: what the trends really mean for you
This isn’t a gentle evolution — it’s a revolution, and the casualties are already piling up. Document extraction technology trends have transcended buzzwords, morphing into existential choices for organizations large and small. Ignore the hype — focus on proven, explainable systems, ruthless iteration, and relentless vigilance for compliance and quality.
The edge belongs to those who treat extraction as a living, breathing strategy — not a purchase order. The opportunity: instant insight, ironclad compliance, and liberated teams. The risk: irrelevance, fines, and enduring chaos.
Will you lead, or get flattened by the next wave? The forked path is before you. One side: confusion, risk, and wasted opportunity. The other: a future illuminated by data, clarity, and ruthless advantage.

Sources
References cited in this article
- Forage.ai: Guide to IDP in 2025(forage.ai)
- Editorialge: AI-Driven Data Extraction Trends(editorialge.com)
- Nectain: 9 DMS Trends for 2025(nectain.com)
- SAPinsider: 2025 Archiving Trends(sapinsider.org)
- Cradl.ai: 2025 Guide(cradl.ai)
- Parsio: Top Extraction Tools(parsio.io)
- CalyxIT: Hidden Costs(calyxit.com)
- Docsumo: Industry Trends(docsumo.com)
- SortSpoke: Evolution of Data Extraction(sortspoke.com)
- Vellum: LLMs vs OCRs(vellum.ai)
- Veryfi: OCR History(veryfi.com)
- Parashift: Template vs ML OCR(parashift.io)
- AIResearchBlogs: LLMs in Extraction(airesearchblogs.com)
- Pondhouse: LLM Document Extraction(pondhouse-data.com)
- AIBusiness: Debunking Myths(aibusiness.com)
- Astera: AI Processing Myths(astera.com)
- Evolution.ai: Myths Debunked(evolution.ai)
- Nature: Hallucination Rates(nature.com)
- AllAboutAI: Hallucination Market(allaboutai.com)
- MIT Tech Review: Legal Risks(technologyreview.com)
- Klippa: Best Extraction Software(klippa.com)
- Docsumo: IDP Case Studies(docsumo.com)
- AI Multiple: Procurement Use Cases(research.aimultiple.com)
- AlgoDocs: Challenges(algodocs.com)
- Cradl.ai: LLM Challenges(cradl.ai)
- Medium: Explainable AI(medium.com)
- PhilPapers: Transparency and Trust(philpapers.org)
- Microsoft: Auditability(techcommunity.microsoft.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What percentage of enterprise data is in unstructured formats?
According to the article, more than 80% of enterprise data now sits in unstructured formats such as contracts, invoices, emails, reports, and scanned images.
How much do enterprises spend annually on manual document processing?
Enterprises spend an estimated $50 billion globally each year on manual document processing, with the majority dedicated to repetitive extraction and validation tasks.
What are the main drivers of unstructured data growth mentioned in the article?
The relentless flood of unstructured data is driven by increased digitization, hybrid work, and regulatory requirements.
What are the consequences when organizations fail to extract insights from documents?
When organizations fail to extract actionable insights, they miss competitive advantages ranging from faster market reactions to more precise risk management, and may overlook critical compliance clauses that could save millions.
Keep Reading
Explore more from Advanced document analysis

The Dark Side of Document Content Extraction: What You’re Missing
If you think “document content extraction” is just a buzzword for automating boring paperwork, buckle up—because the truth is sharper, messier, and far more

Are You Ready for the Document Extraction Revolution?
Discover what’s real, what’s hype, and what’s next in 2026. Unfiltered analysis, expert insights, and actionable strategy inside.

Is Document Extraction Technology Making Us Smarter or Just Faster?
Document extraction technology is rewriting the rules in 2026. Discover the hard truths, hidden pitfalls, and real breakthroughs—plus expert tips you won’t find elsewhere.

7 Truths About Document Extraction Systems Nobody’s Telling You
Discover the hard truths, real risks, and future-proof strategies for AI-driven document processing in 2026. Don’t get left behind.

The Untold Story of Document Extraction Market Analysis in 2026
Document extraction market analysis reveals hidden risks, industry shifts, and actionable strategies for 2026. Don’t get blindsided—discover the edge now.

Are Document Extraction’s Promises Real? 2026 Insights Revealed
Document extraction industry insights for 2026—expose myths, see what’s next, and unlock bold opportunities. Get the edge with in-depth, no-BS analysis. Don’t get left behind.

Document Extraction’s Unseen Future: 7 Shocking Truths for 2026
Unmask the 2026 landscape. Get brutal truths, bold predictions, and practical takeaways. Read now to stay ahead.

Are You Ready to Outsmart Data Chaos? Discover the New Rules of Document Data Extraction
Document data extraction techniques in 2026—your ultimate playbook to outsmarting data chaos, bust myths, and harness the real power of AI. Don’t get left behind—discover what works now.

Document Extraction Software Solutions That Won’t Explode in 2026
Discover insights about document extraction software solutions















