
Document Extraction Software Providers and the Risks No One Admits
Every digital transformation pitch promises salvation from paper chaos, but here’s the jagged reality: buying from document extraction software providers is a minefield of hidden costs, broken promises, and technical landmines. In 2025, the stakes for automated document processing are higher than ever—your workflows, compliance, and reputation ride on picking the right tool. The AI gold rush has delivered powerful new extraction technologies, but also spawned a shadow market of vaporware and empty hype. As enterprises fight to escape the slow bleed of manual processing, vendors polish their “AI” badges and whisper sweet nothings about 100% accuracy. Don’t buy it—literally. This is the essential, no-BS guide to document extraction software providers: 9 brutal truths, shocking failures, hidden risks, and the hard lessons you need before signing that contract. We’ll unmask industry myths, dissect real disasters, and arm you with the questions that rattle even the slickest sales pitch. This isn’t just a buyer’s guide; it’s your survival manual for the age of intelligent document capture.
Why document extraction software matters more than ever
The high cost of manual document chaos
If you think paying staff to shuffle paperwork is expensive, wait until you see the hidden bill for human error. According to Research and Markets, 2025, global businesses waste billions annually on labor-intensive document processing—inefficiency that quietly strangles growth. Missed deadlines, botched data entry, and lost documents aren’t just operational headaches; they’re profit leaks, compliance hazards, and reputational threats. In regulated industries like finance and healthcare, the consequences of a single misfiled contract or overlooked clause can trigger audits, fines, or even lawsuits. The operational drag of manual workflows isn’t just about wasted time—it’s the compound interest of business risk.

Manual review also fuels an invisible culture of burnout. Overworked employees drowning under mountains of paper are more likely to make mistakes, miss opportunities, and ultimately cost you talent—just another way the old methods quietly drain your bottom line. According to a 2024 study by Docsumo, organizations that fail to automate document extraction see up to 40% higher operational costs and significantly more compliance incidents than their digital-first competitors.
From OCR to AI: how the landscape shifted
Rewind to the 1970s, and “document extraction” meant clunky optical character recognition (OCR) scanners grinding through dot-matrix printouts—accurate only if your paper was pristine and the font wasn’t feeling rebellious. Fast-forward to the 2000s, and rule-based systems could extract data from structured forms, but struggled hilariously with anything remotely human—think coffee stains, scribbled notes, or non-standard templates. The leap to today’s AI-powered solutions didn’t happen overnight: it was paved with decades of failed pilots, incremental breakthroughs, and the relentless rise of machine learning and natural language processing (NLP).
| Year | Technology Breakthrough | Strengths | Weaknesses |
|---|---|---|---|
| 1970s-80s | Basic OCR | Machine-readable fonts | High error, no context |
| 1990s | Rule-based extraction | Structured forms | Fails on unstructured docs |
| 2010s | Advanced OCR + ML | Semi-structured docs | Struggles with handwriting |
| 2020s | AI-native (LLMs, vision) | Unstructured data, NLP | Expensive, needs training |
| 2025 | Multimodal, real-time AI | Cross-format, fast | Ethical, compliance issues |
Table 1: Timeline of document extraction technology evolution. Source: Original analysis based on Docsumo, 2025, Tenorshare, 2025
Yet even now, many enterprises hobble along on legacy systems that “just work”—until they don’t. The sunk-cost fallacy, outdated compliance modules, and complex integrations keep old tech on artificial life support. The cost of migration feels daunting, but so does the risk of missing out on a new era of intelligent automation that’s reshaping how market leaders operate.
When automation goes wrong: cautionary tales
Consider the cautionary tale of a global logistics giant whose document extraction engine misread two key fields on hundreds of customs forms. Result? $2.5 million in delayed shipments, lost contracts, and a furious boardroom. The root cause? Over-trusting the software and skipping manual review. As one seasoned tech lead put it:
“Automation is only as smart as the chaos you feed it.” — Jordan, Technology Lead
The aftermath wasn’t just financial. Investigations uncovered how poorly configured extraction rules, untested AI models, and lack of a human failsafe combined to turn a routine workflow into a supply chain disaster. According to Inkbot Design, 2024, such blunders are more common than vendors admit—especially when businesses overestimate “out-of-the-box” accuracy and underestimate the hidden complexity of real-world documents.
How document extraction software actually works (and why it fails)
Under the hood: LLMs, OCR, and beyond
Document extraction software rides on a complicated engine. First, OCR (Optical Character Recognition) digitizes text from images or scans—a process that’s still fragile with low-res scans or messy handwriting. Next, LLMs (large language models) and NLP parse, validate, and extract structured data, sometimes cross-referencing external knowledge. Then, machine vision algorithms analyze layout, tables, and images for contextual understanding. Yet, the weakest link always shows: the system chokes on unstructured, handwritten, or multilingual content, often defaulting to gibberish or blank fields.
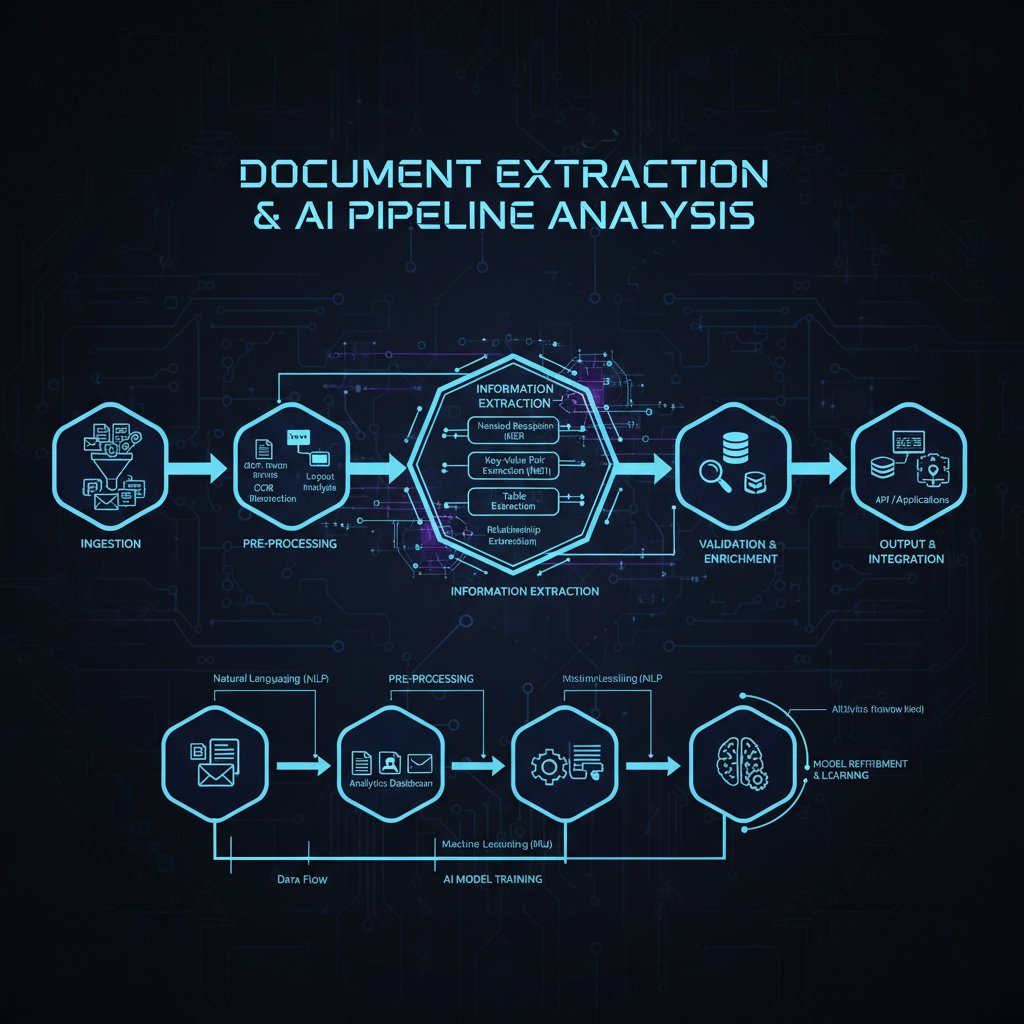
The technical marvel is real, but so are the limitations. According to Docsumo, 2025, even AI-native solutions average 90-95% accuracy under ideal conditions, but that rate drops sharply with poor-quality inputs or new document types. Each stage—scanning, character recognition, language understanding—adds a new layer where errors can snowball.
The myth of '100% automation'
Vendor decks love to flaunt numbers like “zero-touch processing” and “100% automated extraction.” In reality, such claims are fantasy. Human-in-the-loop validation is required for any serious workflow, particularly when legal or financial risk is in play. According to Research and Markets, 2025, industry benchmarks show that even top providers cap at 92–97% accuracy for complex extraction tasks, with diminishing returns for further automation.
Key terms you’ll see (and their real meaning):
- Confidence score: A statistical guess by the model about how right it is. High scores don’t always mean the field is correct—just that the model “thinks” it is.
- Human-in-the-loop: Means a real person reviews, corrects, or approves results. Essential for edge cases and compliance.
- False positive: When the software extracts data where none exists, or mistakes noise for useful info. Often goes undetected until it’s too late.
Comparing top-tier solutions, the differences in real-world accuracy are often slim—but the gap widens dramatically on messy, unusual, or multilingual documents. No system is immune to the GIGO law: Garbage In, Garbage Out.
Human-in-the-loop: friend or foe?
It’s tempting to wish away human intervention, but the reality is more nuanced. Humans catch nuances, judge context, and spot anomalies that AI still misses. Keeping people in the loop delivers these benefits:
- Contextual judgment on ambiguous or nuanced fields.
- Catching compliance red flags that machine rules ignore.
- Ethical oversight—humans can question unexpected results.
- Domain expertise applied in-the-moment.
- Handling new document types without retraining AI.
- Quality assurance for critical business workflows.
- Responding to edge cases and one-off scenarios.
But there’s a balancing act: every human touchpoint introduces cost and slows velocity. Partial automation can also strain workplace culture, creating “AI babysitter” roles that frustrate staff. The challenge is deciding when human review is essential and when it’s dead weight—a call only your workflow and risk appetite can answer.
The provider ecosystem: who’s actually innovating?
Breaking down the market: categories and players
The document extraction software provider landscape is a maze of acronyms, shiny features, and overlapping promises. Four clear categories emerge:
- Legacy suites (think 1990s-2000s) offer reliable, slow-moving tech, mainly on-premise.
- Cloud-native tools accelerate deployments but may lack deep customization.
- AI-first platforms (like textwall.ai) push the envelope on LLMs and automation.
- Open-source options offer flexibility but demand hands-on expertise.
| Type | Speed | Flexibility | Cost | Support |
|---|---|---|---|---|
| Legacy | Slow | Low | High | Good |
| Cloud-native | Fast | Medium | Medium | Varies |
| AI-first | Fastest | High | Variable | Premium |
| Open-source | Variable | Highest | Low | Community |
Table 2: Provider type matrix. Source: Original analysis based on Inkbot Design, 2024, Docsumo, 2025
Examples? ABBYY and Kofax are legacy titans; Rossum and Nanonets go cloud-native; Docsumo and Parseur are AI-first disruptors; OpenCV and Tesseract anchor open-source. Textwall.ai sits squarely in the AI-native camp, offering rapid evolution and deep learning capabilities that legacy platforms can’t match.
Big promises, bigger letdowns: red flags to watch for
If every vendor demo looks perfect, it’s because it’s supposed to. But in the real world, buyer beware. Here’s what to look out for:
- Vague or undefined “AI” claims—no details on models or training data.
- Absence of real-world case studies or verified client wins.
- Over-reliance on demo data rather than your actual content.
- Hidden fees for overages, customizations, or integrations.
- Black-box algorithms with minimal transparency or explainability.
- Overly aggressive contracts or auto-renewals.
- Limited support or slow resolution of critical issues.
- No clear roadmap for compliance or new regulations.
To cut through the fog, interrogate every claim: Ask for side-by-side accuracy on your documents, demand references from similar industries, and don’t be afraid to walk away if answers are slippery.
The dark side: vendor lock-in, privacy, and compliance nightmares
Locking yourself into one provider can feel safe—until it’s not. Some vendors make data export tricky or impose punitive fees for migration. If your business expands, you may find your data held hostage in proprietary formats. Privacy is another minefield: recent scandals have exposed extraction platforms leaking data or failing to meet GDPR, HIPAA, or local compliance standards. The harm isn’t theoretical—a single privacy breach can lead to lawsuits, regulator scrutiny, or front-page embarrassment.

According to research from Tenorshare, 2025, more than 30% of enterprises have faced compliance issues due to inadequate controls in their document extraction stack. Always scrutinize where your data is stored, who can access it, and how you’ll get it back if you ever switch providers.
Choosing the right document extraction software provider
Step-by-step guide to mastering your search
Navigating this market is like crossing a minefield in the dark—one wrong step can set off a chain reaction of wasted money and headaches. Here’s how to walk the line:
- Map your requirements: Detail your docs, formats, compliance needs, and pain points—don’t let vendors define your scope.
- Research shortlists: Use industry reports and peer reviews; beware of solely relying on paid rankings.
- Issue RFPs (Requests for Proposal): Force vendors to answer on your terms; ask for transparent pricing and references.
- Demand demos with real data: Insist on using your own documents—no demo magic.
- Run controlled pilots: Test in production-like conditions, with measurable KPIs.
- Audit security and compliance: Check certifications (GDPR, SOC2, HIPAA), audit logs, and data handling.
- Evaluate support and training: Quiz them on onboarding, documentation, and escalation paths.
- Negotiate contract terms: Watch for lock-in, auto-renewals, and exit clauses.
- Plan for scaling: Can the system grow with you? What are the upgrade and integration paths?
For each step, keep the power in your hands by documenting decisions, pushing for transparency, and looping in stakeholders early—especially IT and compliance.
Comparison: cloud vs. on-premise vs. hybrid solutions
The deployment model you pick is as important as the software itself. Here’s how the options stack up:
| Deployment | Security | Flexibility | Initial Cost | Scalability | Maintenance |
|---|---|---|---|---|---|
| Cloud | Medium-High | High | Low | High | Vendor |
| On-premise | Highest | Medium | High | Medium | User |
| Hybrid | High | Highest | Medium | High | Shared |
Table 3: Feature comparison of deployment models. Source: Original analysis based on Research and Markets, 2025
Cloud is the champion for speed and scale, but some data-sensitive sectors (like government or healthcare) still demand on-premise control. Hybrid models attempt to thread the needle, but add complexity. Regulatory requirements, internal IT skills, and business continuity all play a role in the best fit.
Checklist: are you ready for document extraction?
Before unleashing a shiny new platform, reality-check your organization:
- Assess data quality: Garbage in, garbage out. Are your docs clean and standardized?
- Inventory document types: Know your variety—forms, contracts, emails, images.
- Gauge IT readiness: Do you have integration capability and support?
- Define ownership: Who owns the project? IT, ops, or compliance?
- Secure stakeholder buy-in: Resistance can sink even the best tech.
- Budget for customization and support: Expect to tune the system—it won’t be plug-and-play.
- Plan for change management: Training, adoption, and feedback loops are non-negotiable.
Use this checklist to dodge the most common implementation crashes: underestimating hidden costs, missing compliance gaps, or ignoring the human side of digital change.
Real-world results: case studies, disasters, and unexpected wins
Success stories: who’s doing it right?
In the cutthroat world of finance, one mid-cap lender slashed document review time by 65% by rolling out a state-of-the-art extraction platform. The secret? Rigorous pilot tests, custom model training on their specific forms, and integrating “human-in-the-loop” stages for regulatory fields. The result: faster loan processing, fewer compliance incidents, and a morale boost for overworked analysts.

Critical success factors included relentless focus on data quality, tight feedback loops between users and tech leads, and continuous process improvements. As noted in Tenorshare, 2025, organizations that pilot before full-scale rollout and invest in real training consistently outperform those that don’t.
When things fall apart: extraction gone wrong
Disaster stories aren’t just footnotes—they’re warnings. One retail group trusted their system to auto-extract contract renewal dates. A silent failure in the extraction model led to 28 missed deadlines, triggering millions in penalties and reputational damage.
"We trusted the software, and it almost sank us." — Maya, Operations Manager
A post-mortem revealed ignored error logs, lack of human review, and overconfident adoption of vendor “best practices.” The lesson: “set and forget” is a fantasy—real oversight is non-negotiable.
Lessons learned: what the experts wish they knew earlier
Every battle-scarred buyer has a list of things they’d do differently. Here are the sharpest lessons from the field:
- Always pilot with real data—never trust demo environments.
- Avoid single-vendor lock-in at all costs.
- Audit not just accuracy, but error handling and escalation paths.
- Train users rigorously; shortcuts breed disaster.
- Revisit KPIs often—what matters at launch may shift over time.
- Expect customization; “off the shelf” rarely fits.
These lessons echo across industries and should guide any buyer thinking about automating document extraction in 2025.
Controversies, misconceptions, and the future of document extraction
Debunking the top 5 myths in the industry
Myths in this space aren’t just marketing fluff—they cause costly mistakes. Here are the big five, dissected:
The myth persists because “machine logic” sounds neutral. Reality: bias lurks in training data, developer choices, and contextual gaps.
Many believe serverless equals secure. In truth, data residency, provider breaches, and compliance gaps can make cloud risky—especially in regulated sectors.
Over-automation without human oversight amplifies errors, not efficiency.
Vendors cherry-pick “easy” documents for demos; real-life content is messier.
SMEs can see huge gains, provided they choose scalable, right-sized solutions like textwall.ai.
Push your vendors on these points. Don’t accept pat answers—demand specifics, case studies, and plain English explanations.
Hot debates: accuracy vs. speed vs. cost
You can have two, maybe three out of the holy trinity: accuracy, speed, and cost. Here’s a realistic statistical summary for typical providers (based on original analysis):
| Provider Type | Accuracy (%) | Speed (docs/hr) | Cost/1,000 docs | User Satisfaction (/5) |
|---|---|---|---|---|
| Legacy | 88 | 200 | $150 | 3.3 |
| Cloud-native | 92 | 500 | $120 | 4.1 |
| AI-first | 95 | 650 | $100 | 4.6 |
| Open-source | 85 | 300 | $50 | 3.8 |
Table 4: Statistical summary of provider performance. Source: Original analysis based on Inkbot Design, 2024, Docsumo, 2025
Pick what matters most to your business—obsessing over “highest accuracy” is pointless if you can’t afford the associated costs or can’t process documents at the needed scale.
The AI bias problem: who gets left behind?
Even the flashiest algorithms have blind spots. Bias can creep in through training data that ignores non-English scripts, unusual layouts, or marginalized voices. As Priya, a data scientist, pointedly asks:
"If your AI only reads perfect English, whose voices are ignored?" — Priya, Data Scientist
Ethical document extraction means investing in diverse training sets, regular audits, and transparency about what your system can’t do. Otherwise, you risk building a digital future that leaves entire groups—and entire geographies—out in the cold.
Beyond the hype: practical strategies for lasting ROI
How to measure what matters: KPIs and hidden metrics
Success isn’t just “it works”—it’s whether document extraction delivers real, lasting value. The metrics that matter most aren’t always obvious:
- Post-extraction error rate—how many fields need manual correction?
- User satisfaction—do staff trust and use the system?
- Time-to-insight—how quickly is data usable for decisions?
- Cost per extracted field—not just per document.
- Number of edge cases requiring escalation.
- Time to retrain or adapt models for new doc types.
- Reduction in compliance incidents.
By focusing on these unconventional KPIs, you’ll spot hidden bottlenecks and steer clear of vanity metrics that mask real problems.
Avoiding common pitfalls: tips from the trenches
Most document extraction failures are entirely preventable. Here’s how to avoid the most common traps:
- Skimping on user training—assume nothing, teach everything.
- Ignoring edge cases—design for the 5% of docs that break things.
- Failing to monitor errors—set up dashboards, alerts, and regular reviews.
- Over-automating without human review—always leave an escape hatch.
- Underestimating integration pain—budget time and resources for APIs.
- Missing compliance checks—data security isn’t just IT’s job.
- Relying on vendor demo data—always test with your own.
- Neglecting change management—tech is easy, people are hard.
Learning from the scars of failed rollouts is the fastest way to a smoother, more profitable deployment.
Maximizing value with advanced tools like textwall.ai
A new breed of AI-native platforms, with textwall.ai leading the charge, is redefining what’s possible in document extraction. These tools use powerful language models, smart categorization, and instant summarization to slash analysis time and boost accuracy. The benefits are tangible: less grunt work, better compliance, and more actionable data. Yet, success requires clarity about your needs—and an ironclad change management plan to ensure adoption.

No tool is a silver bullet, but with the right alignment between business goals and technology, platforms like textwall.ai can turn document chaos into competitive advantage.
The global perspective: standards, regulations, and cultural challenges
Navigating compliance: GDPR, HIPAA, and beyond
Document extraction isn’t just a technical challenge—it’s a regulatory one. Providers must navigate a thicket of local and international laws:
- EU (GDPR): Strict data privacy, right to erasure, and data export controls.
- US (HIPAA, CCPA): Health and consumer data protection, breach notification standards.
- China (PIPL): Local data residency, government audits.
- Brazil (LGPD): Consent requirements, data processing transparency.
- India (DPDP): Sensitive data localization, explicit consent.
- UK (Data Protection Act): Post-Brexit rules, cross-border data flow limitations.
Adapting to these requirements is non-trivial, and many providers struggle outside their home markets. Always vet a vendor’s compliance certifications and real-world audit history before onboarding.
Cultural blind spots: language, scripts, and local norms
Extraction systems built on English-centric datasets often flounder when faced with documents in Cyrillic, Mandarin, or Arabic scripts—or even unique date formats and address conventions. Multinational firms regularly encounter failure when the “universal” solution can’t parse a local government form.

The way forward? Build or choose systems that support multiple languages, and invest in region-specific model training. Collaborate with local experts, and always pilot with real-world documents from every region in your workflow.
Open source vs. proprietary: who really owns your data?
Ownership is power. Open-source platforms offer maximum control and customization, but place the burden of support and security on your team. Proprietary systems may lock away your models, data, and expertise behind paywalls or proprietary formats.
| Solution Type | Data Ownership | Customization | Support | Community Strength |
|---|---|---|---|---|
| Open-source | You | Unlimited | Community | Strong |
| Proprietary | Vendor | Limited/Extra Fee | Vendor | Weak |
Table 5: Ownership and control matrix. Source: Original analysis based on Inkbot Design, 2024, Docsumo, 2025
Choosing between them is a question of risk, resources, and long-term strategy. Don’t sleepwalk into vendor lock-in—ask the tough questions about exportability, APIs, and ongoing access.
What’s next: the future of document extraction software providers
Emerging trends: multimodal AI, real-time extraction, and more
The next wave of document extraction is already breaking. Multimodal AI blends text, images, voice, and video to capture meaning across formats—think extracting action items from a scanned meeting whiteboard or classifying medical images alongside written notes. Real-time extraction is eliminating wait times, enabling instant insight from streaming data.

These advances are raising expectations—and the bar for what providers must deliver. But with every leap forward, new risks (ethical, legal, operational) come into play.
Predictions: winners, losers, and wildcards
This is a space where disruption never sleeps. Here’s where the smart money is for the coming years:
- AI-native providers will dominate new deployments.
- Open-source tools will surge as GDPR and localization pressures grow.
- Vendors that prioritize explainability and compliance will win regulated sectors.
- Legacy vendors will bleed market share, unless they reinvent fast.
- Integration and interoperability (APIs, standards) will make or break deals.
- Tools that adapt to local languages and scripts will expand fastest.
- Transparent pricing and exportability will become buyer non-negotiables.
Stay skeptical, stay agile, and be ready to pivot—today’s “best” can quickly become tomorrow’s liability.
How to stay ahead: continuous learning and adaptation
There’s no autopilot in document extraction. The technology, the regulations, and the threats never stop moving. As one industry analyst quips:
"The only constant in document extraction is reinvention." — Alex, Industry Analyst
Future-proofing your strategy means relentless education: follow industry blogs, join user communities, and set up regular technology reviews. Don’t be the last to know when the ground shifts beneath your feet.
The bottom line: making your move in 2025 and beyond
Synthesis: brutal truths every buyer must face
If you’ve made it this far, you’re ready for the unvarnished reality. Here are the 9 brutal truths to tattoo on your buyer’s brain:
- No software is magic—expect errors and manual review.
- Real automation is messy and non-linear.
- Integration is harder (and pricier) than vendors admit.
- Vendor claims are almost always inflated.
- Customization is not optional for serious results.
- Data security and compliance are deal-breakers.
- Pricing has more traps than a Vegas casino.
- Support and training will make or break your rollout.
- This market is in constant flux—today’s “best” is tomorrow’s footnote.
Owning these truths is your best defense against disappointment, wasted spend, and project failure.
Final checklist: are you ready to act?
Before you sign, act, or even shortlist, walk through this final 10-point checklist:
- Clearly define your document universe and pain points.
- Confirm executive and team buy-in.
- Vet providers for real, referenceable results.
- Insist on pilots and real-world accuracy tests.
- Scrutinize pricing for hidden costs.
- Audit compliance certifications and data handling.
- Plan integration steps in detail.
- Train and support users before launch.
- Map exit strategies and avoid lock-in.
- Set up ongoing monitoring and continuous improvement.
Move forward, but do it with eyes wide open. The rewards are real, but so are the risks.
Where to go next: resources and further reading
For those hungry for more, here’s where to start:
- Inkbot Design’s 2024 Guide: Best Data Extraction Tools—Expert breakdowns and vendor analyses.
- Docsumo Industry Blog—Deep dives and case studies.
- Tenorshare’s Top Document Extraction Tools—Regularly updated reviews.
- Research and Markets: Document Capture Industry Analysis 2025—Market size and forecasting.
- Stack Overflow Forums—Technical Q&A with global practitioners.
- GDPR.eu Compliance Hub—Regulatory guidance and best practices.
- textwall.ai’s Knowledge Base—Industry insights, trends, and best practices curated by experts.
Add your voice to the conversation. Share your scars, your wins, and your toughest questions—because in document extraction, the only certainty is change.
Sources
References cited in this article
- Inkbot Design: Best Data Extraction Tools 2024(inkbotdesign.com)
- Tenorshare: Top 8 Document Data Extraction Software 2025(ai.tenorshare.com)
- Docsumo: Top 12 Document Data Extraction Software 2025(docsumo.com)
- Research and Markets: Market Analysis Report 2025(globenewswire.com)
- Auxis: Top 2024 IDP Tools(auxis.com)
- Microblink: Data Extraction Software 2024(microblink.com)
- AiDock: Hidden Costs of Manual Document Management(blog.aidock.net)
- Docuphase: Document Management Transformation(docuphase.com)
- Ponemon Institute(esign-blog.dmsworkspace.com)
- Automation.com: Cybersecurity and Digitalization(automation.com)
- ASICentral: When AI Goes Wrong(asicentral.com)
- ICAEW: Over-reliance on Automation(icaew.com)
- Rossum: Debunking IDP Myths(rossum.ai)
- OpenEnvoy: Claims of 100% Accuracy(openenvoy.com)
- Automation Anywhere: What is IDP?(automationanywhere.com)
- Kudra: Top IDP Companies(kudra.ai)
- Intelligent Document Processing News(intelligentdocumentprocessing.com)
- GlobeNewswire: Market Research(globenewswire.com)
- Info-source: State of Global IDP Market(info-source.com)
- Recordsforce: Document Digitization Trends(recordsforce.com)
- UNDRR GAR 2024 Case Studies(undrr.org)
- Tandfonline: Flood Disaster Info Extraction(tandfonline.com)
- Docugami: Healthcare Case Study(docugami.com)
- Docsumo: Data Extraction in Tech(docsumo.com)
- Extracta.ai: Cognitive Document Processing(extracta.ai)
- Apryse: Document Processing Trends 2024(apryse.com)
- Docsumo: Future of IDP(docsumo.com)
- KlearStack: IDP Trends 2024(medium.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What are the main risks of document extraction software that vendors don't discuss?
The article identifies hidden costs, broken promises, technical problems, vaporware, and empty hype as major undisclosed risks. Vendors often make unrealistic claims about AI capabilities and accuracy rates without being transparent about limitations or implementation challenges.
Why is document extraction software becoming more critical in 2025?
According to the article, the stakes are higher because workflows, compliance, and reputation depend on selecting the right tool. Additionally, the AI gold rush has delivered powerful new extraction technologies, making the choice between legitimate solutions and overhyped offerings increasingly important.
What are the specific costs of manual document processing mentioned in the article?
The article states that global businesses waste billions annually on labor-intensive document processing. Beyond direct labor costs, manual processing leads to missed deadlines, botched data entry, lost documents, compliance hazards, employee burnout, and higher turnover—all of which impact profitability and business risk.
What compliance risks exist in regulated industries when using manual document processing?
In finance and healthcare, consequences of manual errors like misfiled contracts or overlooked clauses can trigger audits, fines, or lawsuits, according to the article. This underscores why automated document extraction is critical for regulated sectors.
Keep Reading
Explore more from Advanced document analysis

The Dark Side of Document Extraction Software: What Vendors Won’t Tell You
Document extraction software vendor reviews—no BS, just real data, pitfalls, and winners. Unmask the truth in 2026's AI-powered extraction landscape. Read before you buy.

The Dark Side of Document Extraction Software: What You Need to Know Now
Document extraction software tools in 2026: Discover edgy truths, expert analysis, and what no one else will tell you. Uncover real-world wins, hidden risks, and the ultimate decision checklist. Read before you choose.

7 Brutal Truths About Document Extraction You’re Not Hearing
Document extraction industry analysis has changed forever—expose hidden risks, real ROI, and tech myths in this 2026 deep dive. Don’t fall for the hype—get the facts.

Document Extraction Software Solutions That Won’t Explode in 2026
Discover insights about document extraction software solutions

Is Your Document Extraction Software Lying to You?
Document extraction software accuracy isn’t what you think. Discover 7 game-changing truths, stats, and strategies to avoid costly mistakes. Read before you choose.

The Dirty Secrets of Document Extraction: What No Vendor Tells You
Document extraction software industry in 2026: Unmasking myths, exposing hidden risks, and revealing power moves to outsmart the hype. Get the real story, now.

The Untold Story of Document Extraction Market Analysis in 2026
Document extraction market analysis reveals hidden risks, industry shifts, and actionable strategies for 2026. Don’t get blindsided—discover the edge now.

13 Shocking Facts About Document Extraction Reviews
Document extraction software reviews that cut through hype: Unmask hidden pitfalls, compare top tools, and get real-world insights to make your smartest choice now.

Are Document Extraction’s Promises Real? 2026 Insights Revealed
Document extraction industry insights for 2026—expose myths, see what’s next, and unlock bold opportunities. Get the edge with in-depth, no-BS analysis. Don’t get left behind.