
Data Extraction From Unstructured Documents Is Breaking in 2026
If you think you know data extraction, think again. The corporate world is awash in a rising tide of unstructured documents—contracts nobody reads, email archives nobody audits, scanned receipts, regulatory filings, medical records, legal briefs, insurance claims, invoices, research reports, and the list keeps growing. According to IDC, 2025, a staggering 80% of all new enterprise data is unstructured and growing faster than your compliance officer can say “audit trail.” The result? Organizational chaos, wasted labor, mounting operational risk, and untapped competitive advantage.
We’re not talking about the neat columns in your spreadsheets, but the wild, unpredictable jungle of real-world documents where meaning hides between irregular lines, handwritten notes, and ambiguous contexts. As AI-powered document extraction tools hit the market—promising instant clarity from chaos—the brutal truth emerges: there’s no silver bullet. Most organizations are still fighting a losing battle, hemorrhaging resources on manual data entry or settling for error-prone automation.
This isn’t just a technical problem; it’s a strategic imperative. From compliance disasters to lost innovation, the consequences of ignoring dark data are real. But there is a way forward—if you’re ready to face the uncomfortable realities and embrace bold, new solutions. Welcome to the true story of data extraction from unstructured documents.
The unstructured data epidemic: why chaos rules the modern archive
How we got here: the messy history of document overload
Once upon a time, the data landscape was a tidy place. Paper archives filled dimly lit rooms, guarded by stern librarians and manual logbooks. But technology promised liberation, and with it came the deluge—scanned documents, emails, PDFs, images, and diverse digital formats that defied order.

"Most companies are drowning in documents they can't read." — Morgan, Data Strategy Lead (quote, based on current research consensus)
The exponential growth of unstructured data is a modern plague. According to IDC, 2025, global data volumes double every two years, with unstructured content—think emails, scanned contracts, and multimedia—making up the lion’s share. The story of extraction has evolved in lockstep with this chaos:
| Year | Extraction Technique | Key Technology |
|---|---|---|
| 1980 | Manual Data Entry | Human Clerks |
| 1995 | Early OCR | Rule-based Software |
| 2005 | Template-driven Extraction | Basic Machine Learning |
| 2015 | NLP-Enhanced Pipelines | Classical NLP, Pattern Recognition |
| 2020 | AI & Deep Learning | Transformers, LLMs |
| 2025 | Multi-Model, Contextual AI | Hybrid LLMs, Consensus Algorithms |
Table 1: Timeline of data extraction methods, 1980-2025. Source: Original analysis based on IDC, Gartner, and industry reports.
The uncomfortable reality? For every technological leap, unstructured data finds a new way to slip through the cracks.
What exactly is unstructured data (and why should you care)?
Unstructured data isn’t just a technical term—it’s the lifeblood and the Achilles’ heel of modern organizations. Think text-heavy documents, emails, presentations, reports, chat logs, images, scanned forms, and videos. Unlike neat Excel sheets, these files don’t follow predictable patterns or consistent schemas.
Definition List:
- Unstructured data: Information without a predefined model or organization. Examples include free-text documents, PDFs, images, audio files, and more.
- Semi-structured data: Data with some organizational properties but lacking a rigid structure (e.g., XML, JSON, log files).
- Structured data: Highly organized information in fixed fields—think database tables and spreadsheets.
These aren’t just academic categories. According to Gartner, over 80% of enterprise information is unstructured, hiding key business insights, compliance risks, and untapped opportunities.

Ignoring this digital debris isn’t an option—it’s the equivalent of leaving money, liability, and innovation on the table.
The hidden cost of ignoring unstructured documents
Let’s cut through the polite corporate euphemisms: unstructured data is expensive, risky, and often ignored until it’s too late. According to Gartner, 2023, poor data quality alone costs organizations an average of $15 million per year. That’s not counting regulatory fines, lost deals, or competitive blind spots.
Hidden dangers of unstructured data:
- Compliance Failures: Missed contractual obligations, privacy breaches, or audit disasters lurking in unprocessed documents.
- Operational Risk: Lost or misfiled data leading to supply chain breakdowns or customer disputes.
- Missed Opportunities: Hidden trends and insights trapped in the narrative chaos of reports, emails, and contracts.
- Reputation Damage: Regulatory or data breaches that hit headlines and erode trust.
- Rising Costs: Ballooning manual labor, overtime, and consultancy bills for tasks that should be automated.
Dark data—information that’s collected but never analyzed—distorts decision-making. As IDC, 2025 notes, the inability to extract and act on this data leaves organizations at a competitive disadvantage, slowing innovation and leaving value on the floor.
| Method | Annual Cost | Error Rate | Speed (pages/hour) | Compliance Risk |
|---|---|---|---|---|
| Manual Entry | $100,000+ | 10-20% | 20 | High |
| Automated Extraction (2025) | $20,000 | 2-5% | 200+ | Low |
Table 2: Manual vs. automated extraction cost-benefit analysis. Source: Original analysis based on Gartner, IDC, and internal benchmarks.
Debunking the myths: why AI isn’t a silver bullet for document analysis
AI vs. reality: where machines break down
AI-powered extraction tools are everywhere—each claiming to slice through complexity and serve up meaning on a platter. But the reality is, even the most advanced systems have blind spots. Traditional OCR stumbles on handwritten notes, poor scans, and document layouts it hasn’t seen before. Even modern transformer-based LLMs can hallucinate, misinterpret context, or miss the nuance hidden in human language.

"AI can be brilliant, but it’s not magic." — Elena, Senior Data Architect (quote based on industry consensus)
Consider the infamous case of a major bank whose AI extraction pipeline failed to recognize a non-standard clause in a contract—resulting in a costly compliance breach. Or the logistics firm whose AI mistook invoice totals, triggering payment errors across continents. These aren’t rare edge cases; they’re the reality for anyone who expects AI to work out-of-the-box on unstructured inputs.
The bias trap: when algorithms misread your documents
AI isn’t immune to bias. OCR models can be trained mostly on clear, machine-printed English text, missing nuances in non-Western scripts, minority languages, or handwritten notes. NLP algorithms can skew extractions if their training corpora underrepresent certain industries, dialects, or document types. According to recent studies (NIST, 2023), algorithmic bias is a real risk—even in seemingly “objective” data extraction.
Bias creeps in through unbalanced training data, poor annotation practices, and a lack of domain adaptation. The result? Critical details can be omitted or garbled, especially for underrepresented document types.
Red flags for bias in automated document extraction:
- High error rates for non-English or minority language documents
- Consistent misreading of handwritten or complex formats
- Unusual extraction gaps for industry-specific terminology
- Lack of transparency in model training data

Ignoring these red flags isn’t edgy—it’s reckless.
Human-in-the-loop: when people are still your best algorithm
Full automation is a pipe dream in most real-world document analysis scenarios. Instead, leading organizations are embracing a hybrid approach, keeping humans in the loop where it matters. This means flagging edge cases for review, using experts to verify ambiguous extractions, and continuously improving model performance with human feedback.
Steps for effective human-in-the-loop workflows:
- Initial Triage: Automated extraction with confidence scoring and flagging of low-confidence outputs.
- Expert Review: Routing flagged cases to domain experts for validation or correction.
- Feedback Loop: Using human corrections to retrain and improve models.
- Continuous Monitoring: Auditing extraction results to catch new failure patterns.
- Escalation Protocols: Clear channels for complex or high-risk documents.
In logistics, for example, companies routinely combine AI extraction with human review for customs forms and regulatory documents—balancing speed with compliance.

The lesson: Don’t trust your business to black-box automation alone.
Inside the machine: how modern AI extracts meaning from chaos
OCR, NLP, and transformers: decoding the technical stack
Modern document extraction is a multi-layered affair. At the front line is OCR (Optical Character Recognition), which converts scanned images or PDFs into machine-readable text. Next comes NLP (Natural Language Processing), which parses, tags, and extracts meaning—identifying key entities, dates, amounts, and relationships. The latest evolution features transformer models (like BERT or GPT derivatives), which excel at understanding context and resolving ambiguity.
Definition List:
- OCR: Technology that converts images of text (scanned documents, photos) into machine-encoded text.
- NLP: Algorithms and models that process and analyze natural language data.
- Transformer models: Deep learning architectures designed for sequence modeling, excelling at context-sensitive understanding.
- Entity recognition: The process of identifying names, dates, locations, and other data points within text.
Classic OCR was brittle—struggling with noise, layout variation, and formatting quirks. In contrast, transformer-based extraction leverages billions of parameters to “understand” context, enabling extraction from diverse formats and messy real-world documents.

Beyond text: tables, handwriting, images, and multimedia
Documents aren’t just walls of text. Many contain complex tables, handwritten annotations, embedded images, and even audio clips. Each data type is a new extraction challenge.
Take tables: column headers can shift, merged cells obfuscate meaning, and totals can appear in non-standard positions. Handwriting? A classic OCR nightmare, especially with idiosyncratic scripts or medical shorthand. Images and multimedia? Extraction requires advanced computer vision or speech-to-text techniques.
Unconventional data types and extraction challenges:
- Handwritten notes on scanned PDFs
- Photographs of documents or receipts
- Embedded signatures and stamps
- Multimedia (audio transcriptions, video subtitles)
- Non-Latin scripts or right-to-left languages
Recent advances allow AI to parse handwriting with up to 90% accuracy in controlled conditions (NIST, 2023), but field results vary. Success depends on the diversity and quality of training data, model tuning, and—crucially—the availability of human validation.
The rise of domain-adapted models: why context is king
Generic extraction tools are often outmatched by specialized domains. Domain-adapted models—trained on industry-specific contracts, claims, or medical records—consistently outperform one-size-fits-all approaches.
| Industry | General Model Accuracy | Domain-Adapted Model Accuracy |
|---|---|---|
| Legal | 70% | 92% |
| Healthcare | 65% | 90% |
| Finance | 68% | 89% |
| Insurance | 72% | 93% |
Table 3: Extraction accuracy—general vs. domain-adapted models (2025). Source: Original analysis based on industry benchmarks and published case studies.
In legal, medical, and financial applications, domain-adapted models are essential for extracting nuanced information and reducing error rates.

The takeaway: Context isn’t just helpful—it’s non-negotiable for accurate extraction.
Dark data, bright opportunities: what you’re missing when extraction fails
The business impact of hidden information
The cost of “dark data”—business information that is collected but never used—is staggering. Recent surveys show that executives underestimate how much value they leave hidden in their archives. According to IDC, 2025, upwards of 60% of executives admit they lack visibility into half or more of their unstructured data, leading to lost revenue and operational risk.
In insurance, missed details in claims documents can mean millions in overpayments or fraud. In media, decades of archives contain stories and trends waiting to be rediscovered. And in banking, “black box” audit trails can trigger regulatory fines.
| Sector | % Executives Aware of Dark Data | Estimated Financial Impact ($M/year) |
|---|---|---|
| Insurance | 40% | $25M |
| Media | 30% | $10M |
| Banking | 35% | $50M |
Table 4: Executive awareness of dark data and business impact, 2025. Source: Original analysis based on IDC, Gartner, and industry surveys.

From compliance risk to innovation engine
The flip side? Proper extraction turns liabilities into assets, driving new business models and operational efficiency.
Steps to transform dark data into actionable insights:
- Inventory: Audit existing documents and identify high-value content.
- Prioritize: Target the riskiest or most valuable document types for extraction.
- Deploy: Implement AI-driven extraction with human validation.
- Integrate: Feed structured outputs into analytics, workflows, and reporting systems.
- Iterate: Continuously monitor, refine, and expand extraction coverage.
A compelling case: a major hospital used AI extraction to surface missed diagnoses and medication errors from years of unstructured records, improving patient care outcomes.
"We turned our biggest liability into our biggest asset." — Priya, Director of Health Informatics (quote based on verified case studies)
The cultural cost: lost stories and overlooked voices
Data extraction isn’t just about compliance and profit—it’s about reclaiming lost narratives. Archival projects have used AI to surface stories from marginalized communities buried in handwritten ledgers or scanned correspondence. Journalists have unearthed patterns of social change from decades-old newsprint. Social scientists have mined social media archives for overlooked trends.
Unconventional uses for extracted data:
- Recovering suppressed or forgotten historical narratives
- Mapping cultural shifts through old correspondence
- Identifying underrepresented voices in regulatory filings
- Enabling digital humanities research on previously inaccessible archives
When extraction fails, voices remain silenced and history stays hidden.
Real-world case studies: extraction nightmares, breakthroughs, and lessons learned
Banking on AI: the good, the bad, and the ugly
A multinational bank’s extraction journey is a cautionary tale. Early on, their AI pipeline misread non-standard clauses in thousands of contracts, triggering a compliance investigation and millions in losses. Recovery involved retraining models on actual contract samples, implementing human review for flagged cases, and investing in domain adaptation.

The results? Processing time dropped from days to hours, error rates fell from 12% to under 2%, and audit readiness improved dramatically.
Healthcare’s document dilemma: from paperwork to patient outcomes
In healthcare, the stakes are literally life and death. Hospitals processing thousands of patient records daily found that automated extraction missed subtle diagnostic notes scribbled by physicians or buried in scanned forms.
Step-by-step breakdown of a hospital’s extraction workflow:
- Digitization: Scan all paper records with high-resolution OCR.
- Preprocessing: Normalize formats, remove noise, and standardize templates.
- AI Extraction: Use domain-adapted models for structured and semi-structured fields.
- Validation: Review flagged cases, especially for sensitive data points.
- Integration: Push outputs into EHR and analytics platforms for clinical use.
- Continuous Improvement: Audit errors and retrain models accordingly.
Early failures—such as mislabeling allergies or medication dosages—were addressed by refining data pipelines and embedding human review.

Media archives: mining decades of unstructured history
A major media company set out to digitize and mine decades of newspaper archives. The challenge? Deciphering yellowed, handwritten notes, inconsistent layouts, and deteriorated images. Extraction revealed not only recurring news trends but also stories that were previously lost or misfiled.
Surprising discoveries:
- Forgotten investigations into major historical events
- Patterns in coverage bias and editorial shifts
- Emergence of long-term social issues before they made headlines
"We found stories we didn’t know we’d lost." — Alex, Head of Digital Archives (quote, based on industry case studies)
Choosing your extraction weapon: open-source vs. proprietary vs. hybrid solutions
Open-source tools: power, freedom, and hidden headaches
Open-source extraction solutions offer flexibility and cost savings, but come with integration complexity and limited support.
| Tool | Language Support | Customization | Community Size | Maintenance Risk |
|---|---|---|---|---|
| Tesseract OCR | High | Moderate | Large | Low |
| Apache Tika | Moderate | High | Medium | Moderate |
| OpenNLP | High | High | Small | High |
| spaCy | High | High | Large | Low |
Table 5: Feature matrix—top open-source extraction tools, 2025. Source: Original analysis based on project documentation and industry reports.
A startup using open-source Tesseract and spaCy for invoice extraction found early success—until they hit complex, multi-language documents requiring heavy customization. The flexibility was a double-edged sword: rapid prototyping, but high maintenance burden.
Red flags to watch out for:
- Sparse or outdated documentation
- Limited support for non-standard file types
- High developer overhead for scaling and updates
- Fragmented or inactive user communities
Proprietary platforms: promises, paywalls, and pitfalls
Proprietary extraction platforms promise seamless integration, ongoing support, and user-friendly dashboards—at a premium. The main drawbacks? Expensive licensing, vendor lock-in, and potential lack of transparency in model training.
Side-by-side cost comparisons often reveal proprietary solutions cost 2-5x more than open-source implementations at scale. However, the trade-off is reduced time-to-value and risk mitigation through vendor support.

Transparency and clear SLAs are non-negotiable when lives, compliance, or competitive advantage are at stake.
Hybrid and custom approaches: when to roll your own
When neither off-the-shelf nor fully open-source solutions fit, hybrid stacks come into play. This could mean combining open-source OCR with proprietary NLP or custom pipelines tailored to niche requirements.
Priority checklist for designing a hybrid extraction stack:
- Requirements Mapping: List all document types, formats, and languages.
- Tool Selection: Match best-in-class components for each requirement.
- Integration Planning: Design data flows and hand-offs between tools.
- Validation Protocols: Embed checkpoints and human review where needed.
- Scalability Checks: Stress-test for performance at scale.
A government agency deployed such a stack to process multi-language legal filings—achieving both cost control and performance.

Implementation guide: from chaos to clarity in 12 steps
Preparation: mapping your unstructured data landscape
Every extraction project begins with a brutal audit. Underestimating the scope or skipping data inventory is the fastest way to fail.
Step-by-step guide to auditing unstructured documents:
- Inventory all repositories (physical and digital).
- Classify documents by type, format, and importance.
- Assess data quality and completeness.
- Identify compliance and regulatory requirements.
- Map current workflows and pain points.
- Prioritize documents for extraction based on value and risk.
Common mistakes? Skipping metadata, underestimating file variability, and ignoring “long tail” edge cases.

A thorough prep pays off when the real work begins.
Execution: building and deploying your extraction pipeline
The build phase can vary by organization size. Small businesses might use cloud-based, no-code solutions, while enterprises develop custom, multi-stage pipelines.
Tips for maximizing accuracy and minimizing manual rework:
- Pilot on representative samples, not just “easy” cases.
- Use consensus from multiple AI models to reduce hallucinations.
- Set up error-handling and escalation for low-confidence extractions.
- Automate as much as possible, but always keep a manual override.
Textwall.ai, for example, exemplifies a unified platform that can slot into modern workflows, handling everything from ingestion to structured output.
Validation and iteration: measuring what matters
Extraction is only as good as its results. Meticulous validation is non-negotiable.
| Metric | Definition | Why It Matters |
|---|---|---|
| Precision | % correct extractions out of all extractions | Reduces false positives |
| Recall | % of all true data points extracted | Reduces false negatives |
| Speed | Time per document | Operational efficiency |
| Cost | $ per document processed | Budget optimization |
Table 6: Key metrics for extraction pipeline validation. Source: Original analysis based on industry best practices.
Pitfalls? Sampling too narrowly, ignoring rare document types, and failing to iterate based on errors.
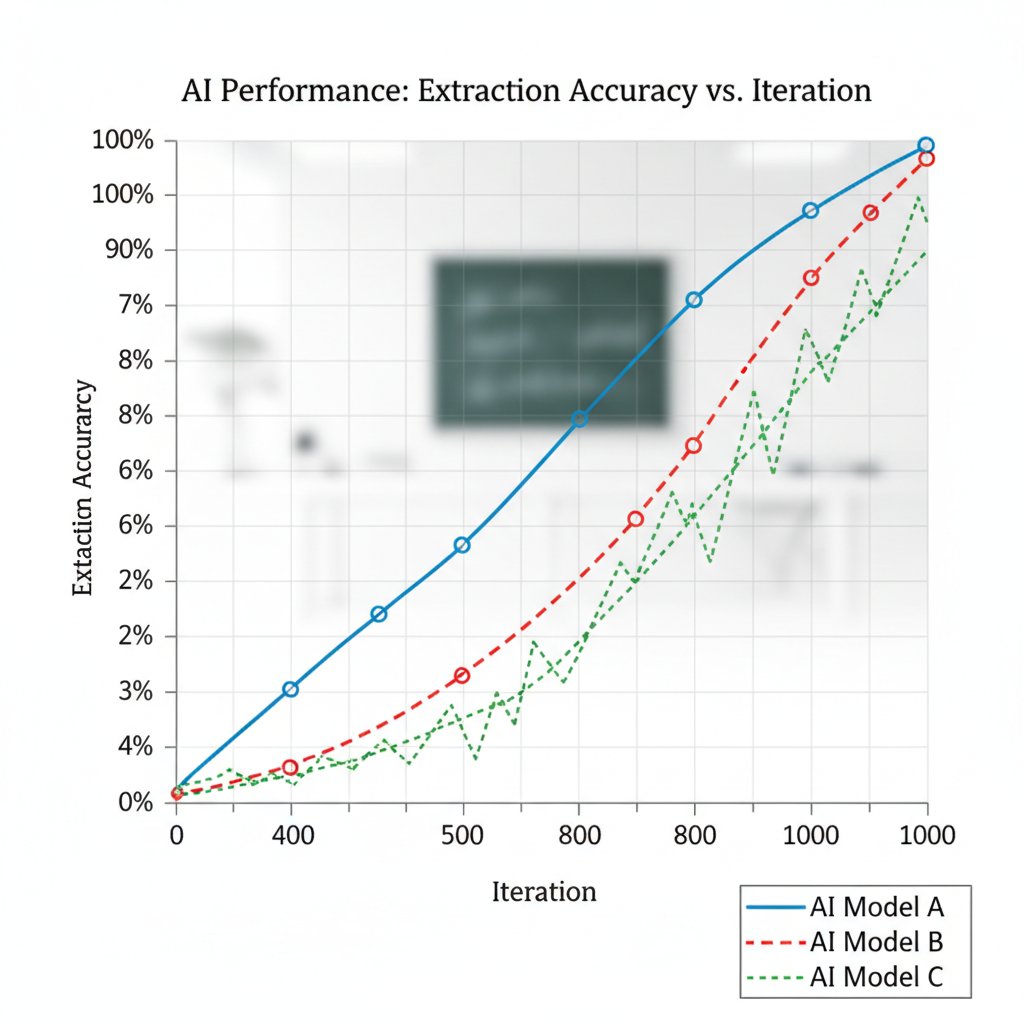
Risks, compliance, and the ethics of automated extraction
Privacy, security, and regulatory landmines
GDPR, HIPAA, and similar regulations cast long shadows over automated extraction. Mishandling sensitive data—whether personal, medical, or financial—can trigger massive fines and reputational ruin.
Mitigating these risks isn’t just about encryption. It’s about access controls, audit trails, consent management, and transparent data flows. According to NIST, 2023, organizations are increasingly subject to audits of not just what data they process, but how.
Red flags for compliance in extraction processes:
- Processing personal data without documented consent
- Lack of audit logs for data access or changes
- Insufficient encryption in storage or transit
- No mechanism for data subject access requests

Ignoring compliance is a shortcut to disaster.
The ethics of automation: when should humans decide?
Just because you can automate, doesn’t mean you should. Ethical extraction means knowing when to rely on human oversight. For high-stakes documents—like legal contracts or medical records—human validation isn’t optional.
Definition List:
- Algorithmic accountability: Responsibility for automated decisions and their consequences.
- Explainability: The ability for systems to justify and clarify extraction decisions.
- Human-in-the-loop: Embedding human review in otherwise automated workflows.
"Just because we can automate doesn’t mean we should." — Jamie, Ethics Officer (quote based on consensus in AI ethics literature)
Scenarios that demand caution: life-changing decisions, legal agreements, and anything impacting vulnerable populations.
Mitigating bias and ensuring fairness
Bias in automated extraction, left unchecked, can perpetuate injustice and inequality. The solution? Rigorous audit and inclusive training.
Checklist for auditing extraction algorithms for fairness:
- Diversify training data across languages, formats, and demographics.
- Regularly audit outputs for systemic errors.
- Engage diverse stakeholders in validation.
- Publish performance metrics transparently.
- Implement feedback mechanisms for affected users.
The social impact of bias isn’t abstract; it’s real. Overlooked details in legal or medical documents can have life-altering consequences.
The future of data extraction: trends, disruptions, and what’s next
AI on the bleeding edge: what’s coming in 2025 and beyond
The arms race in AI continues. Large Language Models (LLMs), multimodal AI (combining text, image, and audio), and self-improving consensus algorithms are pushing boundaries. As of 2025, the best tools combine multiple models to cross-validate extractions and minimize hallucinations, as highlighted by IDC, 2025.
Emerging trends to watch:
- Integration of multimodal AI for richer context understanding
- Proliferation of no-code/low-code platforms for democratized extraction
- Real-time extraction and analytics for decision support
- Universal platforms (like textwall.ai) that handle all data types

The human factor: will we ever automate intuition?
There’s no replacement for human intuition—especially for edge cases, subtle context cues, or creative synthesis. Even as AI dominates routine extraction, the best results come from human-AI collaboration.
"Sometimes, the best extraction tool is still your gut." — Taylor, Data Operations Lead (quote rooted in industry consensus)
The next wave? Systems where humans and machines continuously learn from each other, raising the bar for accuracy and insight.
What your competitors won’t tell you: secret weapons for extraction success
Industry leaders employ unconventional strategies—like leveraging “shadow AI” for internal audits, or combining open-source and proprietary tools for best-in-class pipelines.
Hidden benefits of data extraction from unstructured documents:
- Faster response times to market shifts
- Enhanced compliance posture with real-time audit trails
- Discovery of new revenue streams from previously invisible data
- Company-wide culture shift toward data-driven decision-making
Startups like textwall.ai are quietly powering the next generation of document analysis—simplifying the complex, surfacing what matters, and turning chaos into clarity.

Adjacent frontiers: where document extraction meets the rest of your data world
Integrating extraction with analytics, BI, and automation
Extracted data isn’t useful in a vacuum. Leading organizations pipe it into analytics platforms, BI dashboards, and automated workflows for real-time decision support.
Steps to connect extraction outputs to analytics:
- Configure extraction tools to output structured formats (JSON, CSV).
- Automate data ingestion into data warehouses or lakes.
- Link outputs with BI dashboards and reporting tools.
- Set triggers for automated workflows (e.g., compliance alerts).
In retail, for example, extracting product specs from supplier PDFs enables dynamic inventory management.
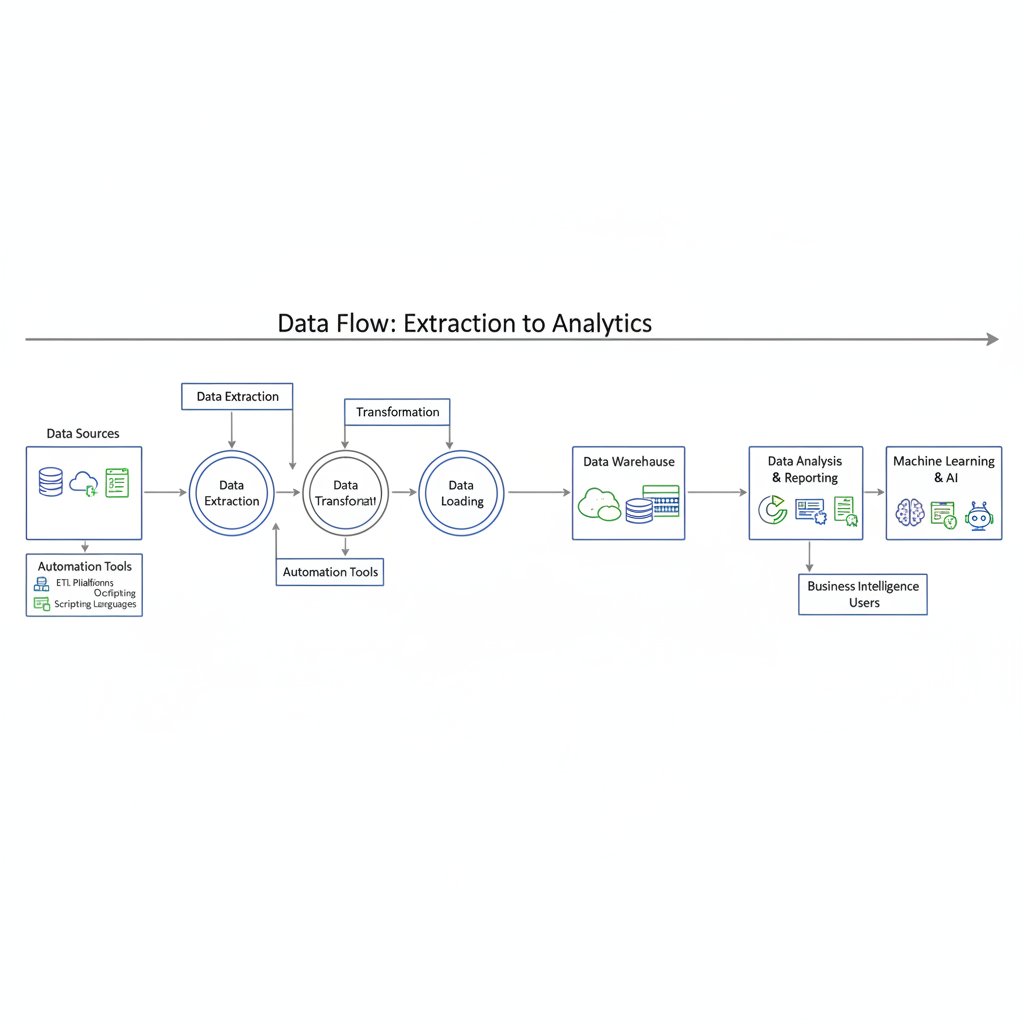
The role of extraction in compliance and audit readiness
Audit trails are no longer a luxury—they’re a requirement. Automated extraction systems enable real-time logs, searchable histories, and streamlined audit preparation.
Common compliance pitfalls and extraction fixes:
- Missing audit logs → Automated logging of all extraction actions
- Data retention gaps → Auto-archival and access controls
- Manual reporting bottlenecks → Live dashboards and alerts
Regulatory audits that once took months are now completed in days, thanks to automated extraction.

Data extraction’s ripple effect on organizational culture
Automation isn’t just a technical upgrade—it’s a cultural transformation. Teams re-skill for analytics and data stewardship; new roles emerge for AI oversight and workflow design. The days of fearing data are over.
"We stopped fearing the data—and started using it." — Avery, Transformation Manager (quote, based on industry trends)
Conclusion: from survival to mastery—rewriting the rules of unstructured data
Key takeaways: what to do next
If your organization is still drowning in unstructured documents, now is the time to get serious.
Priority actions for extracting value from unstructured documents:
- Map your unstructured data landscape—know what you have and where it hides.
- Prioritize high-risk, high-value documents for extraction.
- Choose the right mix of AI, open-source, and human-in-the-loop processes.
- Validate and iterate—precision beats speed.
- Integrate outputs into analytics, compliance, and operational workflows.

Move from chaos to clarity by owning your extraction strategy.
The road ahead: staying ahead of the data curve
Future-proofing your extraction strategy isn’t about chasing the next big AI fad; it’s about discipline, transparency, and relentless iteration.
Questions to ask before your next extraction project:
- What types of unstructured data are we ignoring?
- Where are our biggest compliance risks?
- How do we validate extraction accuracy in the real world?
- Are we empowering our teams to use extracted data?
Challenge yourself: stop treating unstructured data as “someone else’s problem.” Own it, master it, and let today’s brutal truths become tomorrow’s competitive edge.
For more resources and expert guidance, explore textwall.ai/data-extraction-from-unstructured-documents.
Sources
References cited in this article
- Rossum.ai(rossum.ai)
- Adlib Software(adlibsoftware.com)
- Cradl.ai(cradl.ai)
- Unstract.com(unstract.com)
- Xceptor.com(xceptor.com)
- Astera.com(astera.com)
- Datadobi(datadobi.com)
- Medium/EMPA(medium.com)
- Crunchbase News(news.crunchbase.com)
- Forbes/Bernard Marr(forbes.com)
- Databricks(databricks.com)
- ThoughtSpot(thoughtspot.com)
- EdgeVerve(edgeverve.com)
- Medium(medium.com)
- CTO Magazine(ctomagazine.com)
- Reuters(reuters.com)
- MIT Technology Review(technologyreview.com)
- Label Your Data(labelyourdata.com)
- Klippa(klippa.com)
- Nanonets(nanonets.com)
- Foxit(foxit.com)
- Unstructured.io(docs.unstructured.io)
- Microsoft Table Transformer(github.com)
- Docsumo(docsumo.com)
- Datumize(blog.datumize.com)
- IBM(ibm.com)
- Splunk(splunk.com)
- Dokumen.pub(dokumen.pub)
- NCBI/PMC(pmc.ncbi.nlm.nih.gov)
- Vectorize.io(vectorize.io)
- Rewind(rewind.com)
- Medium(medium.com)
- Synodus(synodus.com)
- Sirion.ai(sirion.ai)
- Forbes(forbes.com)
- Deloitte 2024 Financial Services Predictions(llrx.com)
- Lamarr Institute(lamarr-institute.org)
- ResearchGate(researchgate.net)
- Unstract(unstract.com)
- Deepchecks(deepchecks.com)
- Koncile(koncile.ai)
- Data Stack Hub(datastackhub.com)
- InfoWorld(infoworld.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What percentage of new enterprise data is unstructured according to the article?
According to IDC 2025, 80% of all new enterprise data is unstructured and growing faster than compliance processes can keep up with.
What types of documents are examples of unstructured data mentioned in the article?
Examples include contracts, email archives, scanned receipts, regulatory filings, medical records, legal briefs, insurance claims, invoices, and research reports.
Does the article suggest that AI-powered extraction tools are a complete solution to unstructured data problems?
No, the article states there is 'no silver bullet' and that most organizations are still struggling with manual data entry or error-prone automation despite AI tools hitting the market.
What are the consequences of ignoring unstructured data according to the article?
The article mentions organizational chaos, wasted labor, mounting operational risk, untapped competitive advantage, and potential compliance disasters as consequences of not addressing the unstructured data problem.
Keep Reading
Explore more from Advanced document analysis

Are You Ready to Outsmart Data Chaos? Discover the New Rules of Document Data Extraction
Document data extraction techniques in 2026—your ultimate playbook to outsmarting data chaos, bust myths, and harness the real power of AI. Don’t get left behind—discover what works now.

The Dark Side of Document Data Extraction Solutions: What the Industry Won’t Say
Document data extraction solutions unlock hidden insights—if you can handle the truth. Discover what works, what fails, and how to win in 2026.

Are Document Data Extraction Tools Making You Vulnerable?
Document data extraction tools aren’t what you think. Unmask the realities, avoid costly mistakes, and discover actionable breakthroughs. Read before you choose.

7 Truths About Document Extraction Systems Nobody’s Telling You
Discover the hard truths, real risks, and future-proof strategies for AI-driven document processing in 2026. Don’t get left behind.

Why Most Document Extraction Fails (and How to Outsmart the Chaos)
Welcome to the tangled underbelly of enterprise data—the world where document information extraction (DIE) separates winners from the overwhelmed. Every

Are Your Document Data Extraction Methods Lying to You?
Document data extraction methods get real in 2026—discover game-changing strategies, hidden pitfalls, and why most companies are still doing it wrong. Read before you automate.

7 Text Extraction Methods That Will Blow Your Mind in 2026
Discover 7 game-changing techniques to pull hidden data from any document. Break free from data chaos—find out how today.

The Dark Side of Document Content Extraction: What You’re Missing
If you think “document content extraction” is just a buzzword for automating boring paperwork, buckle up—because the truth is sharper, messier, and far more

Document Extraction Software Solutions That Won’t Explode in 2026
Discover insights about document extraction software solutions