
Automated Summarization of Scholarly Articles: Power and Hidden Risks
If you think the automated summarization of scholarly articles is just another fleeting tech trend, you’re already behind. Today, the academic world is drowning—no, suffocating—in data. Every week, tens of thousands of new papers flood digital libraries, each promising to contain the next big breakthrough. Scholars, professionals, and analysts are gasping for air in this knowledge deluge, and AI-powered summarization tools have been thrown to them like lifebuoys. But here’s the inconvenient truth: these tools aren’t magic bullets. They can both rescue and mislead, democratize knowledge or deepen divides, accelerate insight or amplify blind spots. This article rips the shiny veneer off machine-generated summaries, exposing the brutal truths, hidden pitfalls, and transformative possibilities lurking beneath. If you want to navigate the chaos and harness AI for real research advantage, read on—the stakes have never been higher.
Drowning in data: why automated summarization is now a necessity
The exponential rise of academic publishing
Every serious researcher has felt it: the creeping dread that no matter how many hours you spend reading, you’re only skimming the surface. The numbers are relentless. According to a 2024 report by STM Global Brief, more than 3.5 million scholarly articles are published annually across the sciences, social sciences, and humanities. That’s nearly 10,000 fresh papers per day, each demanding attention, analysis, and critical appraisal.
This relentless expansion has transformed once-manageable literature reviews into Sisyphean tasks. Traditional methods—manually reading, annotating, and synthesizing dozens or even hundreds of papers—are now unsustainable for anyone without a small army of assistants. Researchers who once prided themselves on “knowing the field” now admit defeat in the face of tidal waves of new findings.

| Decade | Estimated Annual Publications | Notable Trends |
|---|---|---|
| 1980s | ~400,000 | Print journals dominate, slow access |
| 1990s | ~700,000 | Rise of digital archives, but still fragmented |
| 2000s | ~1,200,000 | Open access movement begins |
| 2010s | ~2,100,000 | Digital explosion, interdisciplinary growth |
| 2020s (2024) | ~3,500,000 | AI tools emerge, information overload peaks |
Table 1: Growth in annual scholarly article publication rates by decade
Source: Original analysis based on STM Global Brief 2024, Statista, 2024
As Ava, a postdoc in neuroscience, puts it:
"Every week, the pile gets higher. Without help, we’re just treading water."
— Ava, Neuroscience Postdoc
The psychological toll of keeping up
It’s not just about being overwhelmed by sheer volume. The emotional and cognitive impact of this relentless torrent is real—and brutal. Researchers are reporting unprecedented rates of burnout, decision paralysis, and a creeping sense that they’re missing critical insights hidden in the noise.
Burnout doesn’t just mean exhaustion; it means missed connections, overlooked discoveries, and research that’s increasingly reactive instead of innovative. According to a recent survey by Nature, 2023, over 67% of academics feel they “cannot keep up” with new literature in their field. The hidden costs ripple outward: grant deadlines missed, innovative ideas suffocated before they can breathe, and academic careers quietly derailed by information fatigue.
Hidden benefits of automated summarization of scholarly articles experts won’t tell you:
- Silent time savings: Automated summarizers can carve hours out of the most mind-numbing part of research—scanning abstracts and introductions—giving you back time for real thinking.
- Unbiased first pass: Machine summaries aren’t influenced by your academic rivalries or disciplinary dogmas, potentially surfacing unexpected studies you’d otherwise skip.
- Reduced cognitive overload: By distilling 30-page papers into digestible insights, well-designed tools can prevent analysis paralysis before it starts.
- Democratization of expertise: Non-native speakers and interdisciplinary teams can break into new fields faster, leveling the academic playing field.
- Spotting trends at scale: Automated summaries can surface meta-patterns across hundreds of papers—trends no human could mentally juggle.
Yet, with every promise of relief, a new anxiety emerges: What if the summary misses the one crucial nuance? What if you trust the algorithm too much, and it lets you down?
A brief history of failed shortcuts
Desperation breeds invention. Long before transformer-based AI, academics sought shortcuts: keyword extractors, rudimentary “intelligent” highlighters, and template-driven summary bots. The early days were littered with failures. Tools that could spit out lists of keywords or “important” sentences were easy to trick, and hilariously bad at surfacing real insights.
| Year | Method/Tool | Milestone/Setback |
|---|---|---|
| 1999 | TF-IDF keyword extractors | Early attempts—surface-level, miss deep context |
| 2006 | Rule-based summarizers | Couldn’t adapt to dense academic jargon |
| 2012 | Early neural models | Struggled with coherence, high error rates |
| 2018 | BERT, transformer models | Huge leap in relevance and readability |
| 2023 | LLM hybrids (GPT-4) | Summaries readable, but nuance still elusive |
| 2024 | Hybrid extractive-abstractive tools | AI summaries now process 200,000+ word docs, but require oversight |
Table 2: Timeline of automated summarization of scholarly articles evolution, with highlights and setbacks
Source: Original analysis based on ScienceDirect, 2024; SciSummary.com data, 2024
Modern AI diverges by leveraging large language models that “understand” context, not just word frequency. But as anyone who’s cross-checked an LLM summary knows, the specter of missed nuance and algorithmic bias lingers—summaries have gotten slicker, but not infallible.
How does automated summarization of scholarly articles actually work?
From extractive to abstractive: decoding the tech
For the uninitiated, not all AI summaries are created equal. There’s a world of difference between extractive and abstractive approaches—a difference that will make or break your research.
Extractive summarization is the blunt instrument: it lifts sentences verbatim from the source, stringing together what the algorithm guesses are “key” sentences. The result can be choppy, sometimes incoherent, and often misses the thread of an argument. Abstractive summarization, on the other hand, aims for something closer to what a human would write—a condensed paraphrase that synthesizes the core ideas in new language. This demands a much deeper contextual understanding.
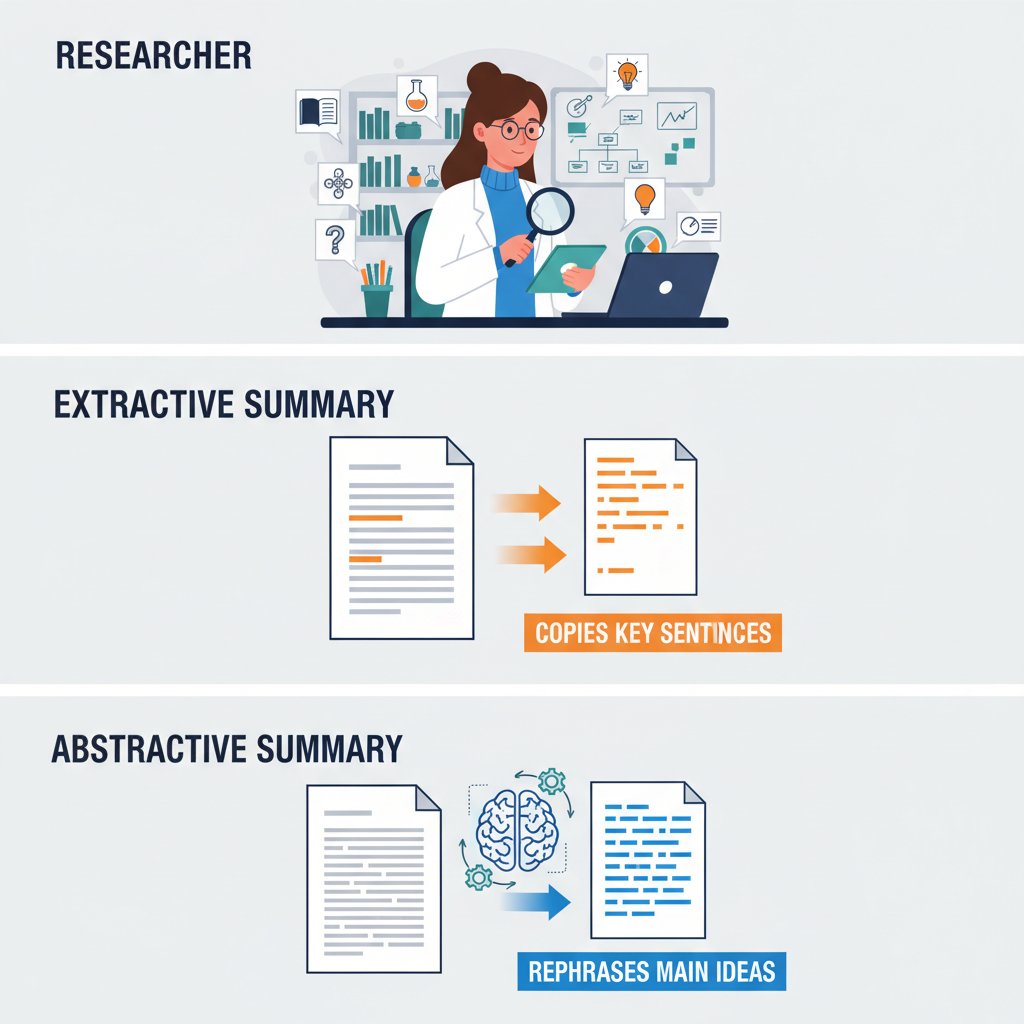
Key terms in automated summarization:
Selects and concatenates sentences or phrases directly from the source text. Fast but risks losing the argument’s flow or missing nuance. Example: "The study found X. The method was Y."—robotic, sometimes incoherent.
Paraphrases the text, generating novel sentences that capture the core meaning. Demands deeper language understanding. Example: "Researchers concluded X using method Y, highlighting Z."
AI trained on massive text corpora to understand, generate, and condense language. Think GPT-4 or BERT—state of the art, but prone to hallucination under pressure.
Combines both methods—uses extractive for structure, abstractive for paraphrase. Current gold standard, especially for lengthy, jargon-rich documents.
The arrival of LLMs wasn’t a mere incremental upgrade—it was a redefinition of what’s possible. Suddenly, summarizers could handle 200,000+ word documents, integrate citation context, and output readable prose. Yet, as ScienceDirect, 2024 notes, even the most advanced models regularly struggle with nuanced arguments, tables, and complex data. The tech is powerful, but not invulnerable.
Inside the black box: how LLMs analyze academic texts
When an LLM tackles a scholarly article, it’s not “reading” as you or I would. It parses every sentence, weighs the relevance of each section, and attempts to discern not only what’s important, but what can be safely omitted. Transformer models split the paper into “tokens,” capturing contextual relationships across immense stretches of text. But the process is never neutral.
| Approach | Strengths | Weaknesses | Typical Use Case |
|---|---|---|---|
| LLM-based (abstractive) | Coherent, human-like summaries; adaptable | Can hallucinate, miss jargon, opaque | Complex research papers |
| Rule-based | Transparent, fast, easy to audit | Rigid, misses nuance, brittle | Simple technical manuals |
| Hybrid | Balances coherence and transparency | Complexity, still needs oversight | Interdisciplinary reviews |
| Human-in-the-loop | Most accurate, context-rich | Slow, costly, scalability issues | High-stakes grant reviews |
Table 3: Comparative feature matrix of automated summarization approaches
Source: Original analysis based on ScienceDirect, 2024; SciSummary, 2024
Most users misunderstand one core fact about these models: The AI is not passively reflecting the “truth” of the article. It’s making decisions—sometimes unconscious, sometimes biased—about what matters and what can be ignored. Style, tone, and even implicit argument can shift in the process.
"Summarization is never neutral. Every algorithm leaves fingerprints." — Ben, Computational Linguist
Common misconceptions and their consequences
Let’s debunk some stubborn myths. The first: “AI summaries are objective.” False. LLMs are trained on human-written data, steeped in prevailing biases. The second: “Summaries catch every important detail.” Also false. Dense jargon, non-standard formats, and complex tables stump even the best models.
Red flags to watch out for when relying on automated summaries:
- Absent limitations: Did the summary mention what the study couldn’t prove, or just its headline findings?
- Perfectly smooth prose: If the summary reads too perfectly, check for missing nuance—LLMs sometimes “smooth over” controversy.
- Citation inflation: Are references or numbers included, or did the summary gloss over details?
- No context for methods: A good summary always explains at least the basics of how results were obtained.
Failure to recognize these flaws is no small thing. According to SciSummary, 2024, error rates on benchmark datasets still hover at 10-15%. For a high-stakes literature review, that’s the difference between a breakthrough and a blunder.
When automated summaries go right—and when they go dangerously wrong
Case study: A university’s experiment with auto-summarization
Consider the multi-semester pilot at a large research university in 2023. Faculty deployed AI-powered summarizers in undergraduate and graduate seminars, asking students to digest dozens of articles per semester using machine-generated summaries. The time savings were immediate—students reported spending 40% less time on readings. But cracks soon emerged.

Faculty discovered a troubling pattern in student essays: nuanced counterarguments and limitations mentioned in the original papers were often absent. Misinterpretations snowballed, with students citing summaries instead of actual results.
| Metric | Human Summary | AI Extractive | LLM Abstractive | Hybrid (Human+AI) |
|---|---|---|---|---|
| Factual accuracy (%) | 96 | 82 | 89 | 93 |
| Missed limitations (%) | 2 | 12 | 8 | 4 |
| Omitted methods (%) | 1 | 18 | 7 | 3 |
| Overstated conclusions (%) | 1 | 8 | 6 | 2 |
Table 4: Accuracy rates and error types in various summarization approaches
Source: Original analysis based on SciSummary benchmarks, 2024; ScienceDirect, 2024
Success stories: Where AI summaries delivered
But it’s not all cautionary tales. In 2024, an interdisciplinary research team at a major European university used automated summarization to scan over 1,000 COVID-19 modeling papers in a matter of days—a process that would have consumed months. The result: a rapid synthesis that informed real-time policy decisions, with human experts spot-checking for accuracy.
Elsewhere, humanities scholars leveraged AI summaries to jump language barriers, comparing cross-cultural studies at unprecedented speed. Policy analysts in NGOs have used LLM-powered summarization to digest massive regulatory changes, enabling agile responses to shifting legal landscapes. In each case, the key was using AI as an accelerator—not a replacement—for critical thinking.
Horror stories: When nuance got lost in translation
And yet, for every win, there’s a horror story. In one high-profile grant application, a researcher relied on a machine summary that omitted a methodological flaw in a foundational paper. The result? Months of wasted lab work chasing a dead end.

The most common failure points are painfully predictable: limitations and caveats omitted, subtle methodological distinctions glossed over, and bias—present in the underlying training data—amplified by the summarizer’s eagerness to please.
Step-by-step guide to spotting unreliable automated summaries:
- Check for limitations: Is there any mention of what the study can’t prove?
- Verify methods: Are the core methods and sample sizes included, or glossed over?
- Scan for specific numbers: Are results quantified, or replaced with vague claims?
- Cross-check references: Do the cited studies actually exist in the original?
- Test against the original: Randomly sample a section; did the summary capture its essence?
The art of reading between the lines: validating and using summaries responsibly
Checklist: Is your summary trustworthy?
Quality control isn’t optional—it’s existential. Every automated summary is a hypothesis, not a verdict. Before acting on a machine-generated précis, run it through a rigorous sniff test.
Priority checklist for automated summarization of scholarly articles implementation:
- Spot-check for limitations, not just results
- Cross-reference at least two summaries for the same article
- Randomly review full sections of the source text
- Ensure citations and statistics are present and accurate
- Engage colleagues—crowdsource potential blind spots
Manual spot-checks and cross-referencing remain your best defense against algorithmic oversights. In high-stakes work, invest the time; your reputation depends on it.

Common mistakes and how to avoid them
Frequent user errors abound, especially among those new to AI tools. Chief among them: over-reliance, neglecting to contextualize results, and underestimating the frequency of omissions.
Common pitfalls in using automated summarization tools:
- Blind trust in summaries: Failing to spot-check against originals or peer-reviewed reviews.
- Ignoring tool limitations: Assuming all content types (tables, figures, pseudocode) are equally summarized.
- Neglecting context: Missing discipline-specific jargon or statistical caveats.
- Overlooking updates: Using out-of-date AI models or failing to retrain for new fields.
Practical tips from expert interviews:
- Summaries are a starting line, not a finish.
- Combine tools—use both extractive and abstractive when possible.
- Integrate human expertise at all critical junctures.
How to use summaries for deeper, not lazier, research
Used wisely, summaries can catalyze better research—not just quicker reading. Power users employ them for hypothesis generation, rapid triage of reading lists, and as conversation starters in collaborative annotation platforms.
"Summaries are a launchpad, not a shortcut." — Ava, Neuroscience Postdoc
Team workflows, from group annotation in Google Docs to shared Zotero libraries, thrive when everyone starts from the same condensed baseline—but only when the full text remains on hand for deep dives.
Beyond academia: unexpected applications and cultural shifts
Cross-industry breakthroughs: law, journalism, and beyond
Legal professionals now deploy AI summarization to process thousands of discovery documents, surfacing relevant case law in record time. Journalists, drowning in government filings and scientific preprints, use summarizers to quickly separate signal from noise—fact-checking with ruthless efficiency.

Time-saving case studies abound: market researchers distilling 400-page reports in hours, activists summarizing regulatory proposals for public campaigns, and healthcare administrators extracting patient data trends from mountains of medical notes.
Unconventional uses for automated summarization of scholarly articles:
- Rapid grant application reviews in research administration
- Summarizing stakeholder feedback in large public projects
- Digesting technical manuals for non-expert staff training
- Identifying emerging trends in patent literature
The rise of 'summary culture' and its consequences
The proliferation of AI-generated summaries isn’t just a workflow shift—it’s a cultural change. As machine-generated synopses become the norm, the societal value placed on deep reading versus rapid scanning is in flux.
Surface-level understanding is increasingly the default. As Pew Research, 2023 notes, over 54% of young adults now prefer summarized or “explainer” content over original sources. The risk? Echo chambers, information bubbles, and a decline in critical reading skills.
| Reading Type | Avg. Frequency (per month) | % Reporting Higher Satisfaction | Most Common Use Case |
|---|---|---|---|
| Full article | 7 | 68% | Major projects, thesis work |
| AI summaries | 25 | 49% | Triage, daily updates, quick reviews |
| Abstracts only | 15 | 34% | Initial screening |
Table 5: In-depth reading vs. summary consumption statistics
Source: Original analysis based on Pew Research, 2023; Nature, 2023
Automated summarization and the democratization of knowledge
It’s not all doom and gloom. High-quality summaries have cracked open the ivory tower, granting unprecedented access to students, non-native speakers, independent scholars, and the public. The playing field is leveling—at least for those with access to robust summarization tools.
Yet, equity concerns persist. Premium summarization platforms often sit behind paywalls, while free models can lag in accuracy. Who gets access to the “best” summaries, and what does it mean for global knowledge equity? Services like textwall.ai are reshaping expectations, but the question of universal access remains live.
Current debates and future frontiers in automated summarization
Do AI summaries perpetuate or challenge academic bias?
This is the debate roiling editorial boards and tech conferences alike. On one hand, AI can amplify prevailing biases—over-representing established fields, under-representing minority viewpoints, and smoothing over controversy in the name of clarity. On the other, new research shows LLM-powered summarizers can expose under-cited works, challenging the canon.

Real-world examples abound. Summaries of gender or race studies often miss critical context, while mainstream scientific papers get “clean” summaries that reinforce consensus. It’s a remix, not a replica.
"Every summary is a remix—and a reflection of its creator." — Ben, Computational Linguist
Ethical dilemmas and the myth of neutrality
Authorship, credit, and accountability: When an AI summarizes a paper, who owns the synopsis? What if the summary misleads and someone acts on it?
Definitions:
The appearance of impartiality, often claimed by algorithm designers, but inevitably shaped by training data and design choices. There is no “view from nowhere.”
The pursuit of accuracy and fairness. In AI summarization, this means surfacing limitations, avoiding cherry-picking, and making biases visible—not pretending they don’t exist.
Auditing and transparency efforts are underway. Benchmark datasets, open-source code audits, and “explainability” dashboards are growing in popularity. But as recent controversies show, vigilance is non-negotiable.
The next wave: multimodal and real-time summarization
Today’s frontier isn’t just text. Researchers in AI labs are training models to summarize images, tables, and even embedded videos within scholarly articles. Multimodal summarization is the new holy grail.
| Feature Type | Mainstream Tools | Advanced Tools (2024) | Real-Time Capability | Collaborative Editing |
|---|---|---|---|---|
| Text-only | Yes | Yes | Yes | Yes |
| Tables | Limited | Yes | Yes | Yes |
| Images | No | Yes | No | Limited |
| Video | No | Limited | No | Planned |
Table 6: Market analysis of advanced summarization features in 2024
Source: Original analysis based on ScienceDirect, 2024; product reviews
Expect real-time collaborative summarization—think shared docs where summaries update as you annotate—to become commonplace for teams managing huge literature sets.
How to choose the right automated summarization tool for your needs
Comparing top platforms and approaches
Not every summarizer is created equal. When the stakes are high, don’t just chase the newest LLM. Prioritize proven accuracy, transparent decision-making, robust integration, and real cost-benefit analysis. For research, prioritizing tools that support citation context, thorough quality checks, and customization is key.
| Feature / Platform | Platform A | Platform B | Platform C | Platform D |
|---|---|---|---|---|
| Text + Table Summaries | Yes | Yes | Limited | Yes |
| Citation Integration | Yes | Limited | No | Yes |
| Transparency Reports | No | Yes | No | Yes |
| Customization Options | Yes | Limited | Yes | Yes |
| Cost | $$ | $ | Free | $$$ |
| API Integration | Yes | No | Yes | Yes |
Table 7: Feature comparison of leading automated summarization platforms
Source: Original analysis based on public product documentation, 2024
Trade-offs matter. Graduate students may favor free, open tools; professionals in regulated industries require audit trails and high accuracy; interdisciplinary teams need robust integration. There is no universal winner.
Checklist: What to look for (and what to avoid)
Step-by-step guide to mastering automated summarization of scholarly articles:
- Define your core needs: Is it speed, depth, or citation accuracy?
- Vet tool transparency: Can you see how decisions are made?
- Demand integration abilities: Will it fit your workflow (Zotero, EndNote, etc.)?
- Check quality assurance: Is there a human-in-the-loop or audit feature?
- Beware of black boxes: Avoid tools that don’t explain their process or cite sources.
- Insist on regular updates: Ensure the tool is maintained and improves over time.
Warning signs: over-promised accuracy, vague claims of “AI magic,” lack of peer reviews, or no human oversight.
Why 'one size fits all' is a myth
Universal solutions rarely deliver for everyone. The demands of a legal researcher, a biomedical scientist, and a market analyst differ radically. Hybrid approaches—mixing AI speed with human judgment—deliver the most robust outcomes. Personalized summarization, tuned to your field and preferences, is the new gold standard and where platforms like textwall.ai excel.
Adjacent revolutions: automation in peer review and knowledge curation
How AI is changing peer review forever
Peer review—the backbone of academic publishing—is being upended by automation. Tools that flag duplicate text, surface statistical anomalies, and summarize reviewer comments are now embedded in editorial workflows.

Benefits are clear: faster turnaround, less drudgery, and more consistent quality. But backlash is real—some fear “robotic” reviews, overlooked nuance, and reviewer deskilling. The interplay between summarization and peer review automation is rapidly evolving, putting pressure on journals to clarify standards.
The evolving landscape of academic knowledge curation
Automation now underpins not just discovery, but curation. Literature databases use AI to build knowledge maps, citation networks, and even suggest reading lists. Librarians and editors must master new skills—data analysis, algorithm auditing, and hybrid curation.
New skills researchers need to thrive in an automated analysis era:
- Algorithmic literacy: Understanding model limits and strengths
- Data auditing: Spotting anomalies and biases in outputs
- Collaborative annotation: Integrating summaries into team workflows
- Critical synthesis: Moving from summary to original insight
What’s next: The future of research workflows
From end-to-end pipeline automation to full integration with project management tools, research workflows are in flux. Services like textwall.ai are embedding summarization into literature reviews, grant writing, and real-time collaboration. The holy grail remains: making sense of the global knowledge explosion without sacrificing depth, rigor, or originality.
Conclusion: mastering the machine—staying sharp in the age of automated summaries
Automated summarization of scholarly articles is a double-edged sword. Used wisely, it’s a superpower—saving time, surfacing hidden gems, and making expertise more accessible than ever. Abused, it’s a shortcut to shallow thinking, missed nuance, and the perpetuation of bias.
Core principles for using automated summarization without losing your edge:
- Always validate—machine summaries are starting points, not finish lines.
- Demand transparency—know how your tools work, and their limits.
- Stay skeptical—cross-check summaries, especially for high-stakes work.
- Collaborate—use summaries to spark discussion, not end it.
- Keep reading full texts—nothing replaces engaged, critical human analysis.
Apply these in your daily research routines, and you’ll stay ahead of the AI curve—critical, creative, and always curious.
"Stay curious, stay critical—the future belongs to those who ask better questions." — Ava, Neuroscience Postdoc
The journey isn’t about replacing human insight with machine outputs. It’s about mastering both—using automation to cut through the noise, while sharpening your own analytic edge. In a world awash with information, discernment is your greatest asset. Don’t just keep up. Lead.
Sources
References cited in this article
- ScienceDirect(sciencedirect.com)
- SciSummary(scisummary.com)
- Noiz.io(noiz.io)
- TAMU(tamu.libguides.com)
- Springer(link.springer.com)
- Research.com(research.com)
- OSTI(osti.gov)
- Neurocomputing(dl.acm.org)
- PMC(ncbi.nlm.nih.gov)
- OuvrirLaScience(ouvrirlascience.fr)
- Council.Science(council.science)
- Dynamic Ecology(dynamicecology.wordpress.com)
- ArXiv(arxiv.org)
- Iris.ai(iris.ai)
- arXiv(arxiv.org)
- Nature Medicine(nature.com)
- arXiv(arxiv.org)
- JAMA(jamanetwork.com)
- Nature(nature.com)
- Scholarcy(scholarcy.com)
- DocHub(dochub.com)
- SciSpace(scispace.com)
- Proof-Reading-Service(proof-reading-service.com)
- COPE(publicationethics.org)
- Frontiers(frontiersin.org)
- Springer(link.springer.com)
- Cambridge Core(cambridge.org)
- Acorn.io(acorn.io)
- ACM(dl.acm.org)
- Frontiers(frontiersin.org)
- ACL Anthology(aclanthology.org)
- Ithy.com(ithy.com)
- PMC(pmc.ncbi.nlm.nih.gov)
- Johns Hopkins Library(guides.library.jhu.edu)
- Enago(enago.com)
- SciSummary(scisummary.com)
- arXiv(arxiv.org)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
How many scholarly articles are published annually according to the article?
According to a 2024 STM Global Brief report cited in the article, more than 3.5 million scholarly articles are published annually across the sciences, social sciences, and humanities, which equals nearly 10,000 fresh papers per day.
Why does the article say automated summarization has become a necessity?
The article argues that automated summarization is necessary because the exponential rise in academic publishing—over 3.5 million articles per year—has made traditional manual methods of reading, annotating, and synthesizing papers unsustainable for researchers without large support teams.
What is the main warning the article gives about AI-powered summarization tools?
The article warns that AI-powered summarization tools are not 'magic bullets' and can both rescue and mislead users; they can democratize knowledge or deepen divides, and accelerate insight or amplify blind spots.
What does the article mean by researchers being 'drowning' or 'suffocating' in data?
The article uses this metaphor to describe how scholars are overwhelmed by the sheer volume of new papers flooding digital libraries—tens of thousands weekly—making it impossible to keep up with the entire field through traditional reading methods.
Keep Reading
Explore more from Advanced document analysis

Academic Literature Summarizer Tools: Time-Saver or Truth-Risk?
Discover insights about academic literature summarizer tool

Document Summarization for Academics When You Can’t Trust AI
Discover insights about document summarization for academics

Are AI Summaries Making Us Smarter or Just Lazy?
Discover the real impact of AI-powered summaries, hidden pitfalls, and how to harness them. Get ahead with expert insights now.

Think You Know Advanced Summarization Tools? Think Again.
Advanced summarization tools in 2026: Discover the real power, risks, and unexpected benefits that AI-driven document analysis brings. Don’t get left behind—unlock actionable insights now.

Why Most Document Summarizers Fail Researchers (and What to Do About It)
Expose hidden pitfalls, unlock research breakthroughs, and outsmart AI hype in 2026. Discover what top minds won't tell you.

Automated Report Summarization: Speed, Risk and Who to Trust
Discover insights about automated report summarization

The Hidden Costs of Academic Summarization Tools Nobody Talks About
Get the raw reality, hidden risks, and new hacks to supercharge your research workflow. Don’t let AI shortcuts wreck your edge—read before you click.

Automate Lengthy Document Summarization Without Losing Context
Discover insights about automate lengthy document summarization

Summarizing Scholarly Articles: Why You’re Probably Doing It Wrong
How to summarize scholarly articles—demystified. Discover brutal truths, expert hacks, and the new rules of research in 2026. Nail your next summary today.









