
Automated Summarization of Patient Data When Accuracy Is Life or Death
In the dimly lit corridors of today’s hospitals, a silent revolution is underway—one that’s as thrilling as it is unsettling. Automated summarization of patient data promises to transform the chaos of modern healthcare into streamlined clinical clarity. Yet, behind the glossy marketing slides and AI buzz, the true impact remains elusive, rife with paradoxes, pitfalls, and ethical landmines. From clinicians suffocating under digital overload to AI engines that sometimes hallucinate facts, this isn’t your average tale of technological progress. Dive in, and you’ll discover nine brutal truths most hospitals ignore—truths that could mean the difference between a breakthrough and a breakdown in patient care. This is the real story of automated summarization of patient data, told with grit, backed by research, and stripped of illusions.
Why the stakes are higher than you think
Information overload: The silent killer in modern medicine
Step into any major hospital today and you’ll meet clinicians awash in a tsunami of information—an average hospital generates a staggering 50 petabytes of patient data every year. But here’s the cruel punchline: up to 97% of this data goes unused, rotting in digital silos, while vital insights slip through the cracks (World Economic Forum, 2024). The more we digitize, the less we seem to know.

Take the case of Julia, an MD informatics lead at a major urban center, who puts it bluntly:
“We’re drowning in information, but starved for actionable insight.”
It’s not just a catchy soundbite. Real-world consequences are everywhere: missed diagnoses buried in redundant electronic health records (EHRs), critical allergy warnings hidden in a fog of progress notes, medication errors fueled by fragmented histories. In some harrowing cases, vital trends—like rising creatinine or subtle changes in mental status—go unnoticed until it’s too late.
- Delayed diagnoses: When actionable findings hide in a deluge of routine notes, physicians can miss early warning signs, compromising care.
- Therapeutic inertia: Overwhelmed by irrelevant data, clinicians default to the status quo, delaying necessary interventions.
- Communication breakdown: Information gaps between specialists and primary care can lead to redundant tests or conflicting treatments.
- Burnout acceleration: The relentless pressure to “read it all” fuels emotional exhaustion, harming both caregivers and patients.
- Legal exposure: Missed information can trigger lawsuits, even if the data was technically “available” somewhere in the system.
Sound familiar? Automation strides in, promising to turn this chaos into clarity. But as you’ll see, the solution is far from plug-and-play.
What no one tells you about medical data accuracy
It’s tempting to believe that digital equals accurate. In reality, the shift from paper to pixels has simply traded one set of problems for another. According to an analysis by STAT News, 2024, AI summarization tools—while lightning-fast—have a troubling tendency to introduce errors or even fabricate information. This isn’t just an academic concern: mistakes in automated summaries can lead to misdiagnosis, wrong treatments, and shattered trust.
| Summarization Method | Average Accuracy Rate | Common Error Types |
|---|---|---|
| Manual (Clinician Only) | 91-95% | Omission, bias, fatigue |
| Automated (AI Only) | 77-90% | Hallucinations, omissions |
| Hybrid (AI + Human) | 92-97% | Oversight, bias blending |
Table 1: Accuracy rates for manual, automated, and hybrid summarization methods in clinical settings, based on published 2024 studies.
Source: Original analysis based on STAT News, 2024, PMC, 2023
Blind faith in any output—whether from a rushed resident or a gleaming new algorithm—is dangerous. As Liam, a data scientist in a major hospital network, notes:
“Sometimes the summary is just a mirror of our own biases—only faster.”
The lesson here is sobering: automating medical data doesn’t guarantee accuracy. In fact, it can amplify old problems and introduce new ones. Next, let’s dig into how we got here—and why old attitudes die hard.
From paper trails to AI tales: A brief history of summarization
Manual summarization: The roots and the resistance
Before EHRs and smart summarizers, patient data lived in paper charts—bulky, cryptic, and fiercely guarded by clerks and clinicians. Summarization was an art: a senior nurse’s margin note, a physician’s “significant findings” summary at discharge, a hand-scrawled timeline of symptoms.

This tactile approach bred a kind of intimacy with patient stories—but also fostered deep skepticism about “black box” automation. Today, that skepticism lingers. Many clinicians recall missed allergies or medication errors not from lack of data, but from illegible handwriting or lost notes.
Definitions that matter:
Problem list:
A curated summary of a patient’s active and resolved issues, often the first thing a clinician reviews. Rooted in tradition, but still error-prone—especially when copied forward blindly.
Progress note:
A daily summary of patient status, historically handwritten and now digital. Still vital for tracking trends—but vulnerable to “note bloat” and copy-paste errors.
Discharge summary:
The final word on a patient’s hospital stay. Once a handwritten narrative, now often auto-populated by EHRs—and sometimes dangerously incomplete.
These historical habits shape today’s workflows. The mistrust of “machine-made” summaries isn’t just nostalgia—it’s a defense against real harm.
The dawn of automation: Early experiments and epic failures
Fast-forward to the digital era. The 1990s and early 2000s saw the first wave of computerized summarization—primitive keyword extractors, template-based discharge summaries, and clunky rule-based engines. The promises were bold; the results, often embarrassing.
- 1992: First hospital deploys keyword-based discharge summary generator—results are so generic, clinicians ignore them.
- 1999: Early EHR vendors add “auto-summary” features, producing bloated, error-ridden notes.
- 2005: NLP (natural language processing) pilots extract medication lists—miss key allergies, leading to reported near-misses.
- 2010: Machine learning enters the scene; researchers attempt automated risk scoring from unstructured texts.
- 2015: Deep learning applied to radiology reports; initial accuracy impressive, but context errors abound.
- 2020: Widespread adoption of transformer-based LLMs for summarization in research settings.
- 2023: Regulatory scrutiny intensifies after several high-profile clinical errors linked to AI-generated summaries.
- 2024: No universal standard emerges; over 600 EHR systems complicate wide-scale integration (PMC, 2024).

These early missteps left scars—and taught crucial lessons about the limitations of both technology and human trust. As we’ll see, today’s revolution is more sophisticated, but the ghosts of these failures still haunt every new implementation.
How automated summarization really works (and where it breaks)
Natural language processing: The engine under the hood
At the heart of modern automated summarization sits natural language processing (NLP). Think of it as the digital brain that “reads” clinical notes, lab reports, and imaging summaries—then attempts to distill what matters most. But don’t be fooled by the jargon; NLP is as much art as it is science.
Put simply, NLP algorithms sift through mountains of unstructured medical text, tagging key concepts, disambiguating medical jargon, and ranking the salience of findings. Imagine teaching a machine to spot the difference between “discharged to home” and “discharged home oxygen”—one wrong inference, and care plans unravel.
| Feature | Open-Source Engines | Proprietary Engines | Pros | Cons |
|---|---|---|---|---|
| Customization | High | Medium | Tailored to need | Requires in-house expertise |
| Regulatory Compliance | Variable | Strict | Trusted for clinical use | Expensive, vendor lock-in |
| Multilingual Support | Limited | Extensive | Global reach possible | May lack local nuance |
| Integration Complexity | High | Moderate | Potential for deep integration | Risk of workflow disruption |
| Update Frequency | Community-driven | Vendor-scheduled | Fast bug fixes | Slower adaptation |
Table 2: Feature matrix comparing open-source and proprietary summarization engines in clinical contexts.
Source: Original analysis based on PMC, 2023, [J Biomed Inform, 2024]
Workflow, in essence:
Raw EHR data → NLP parsing → Entity extraction → Salience ranking → Structured summary → Human validation.
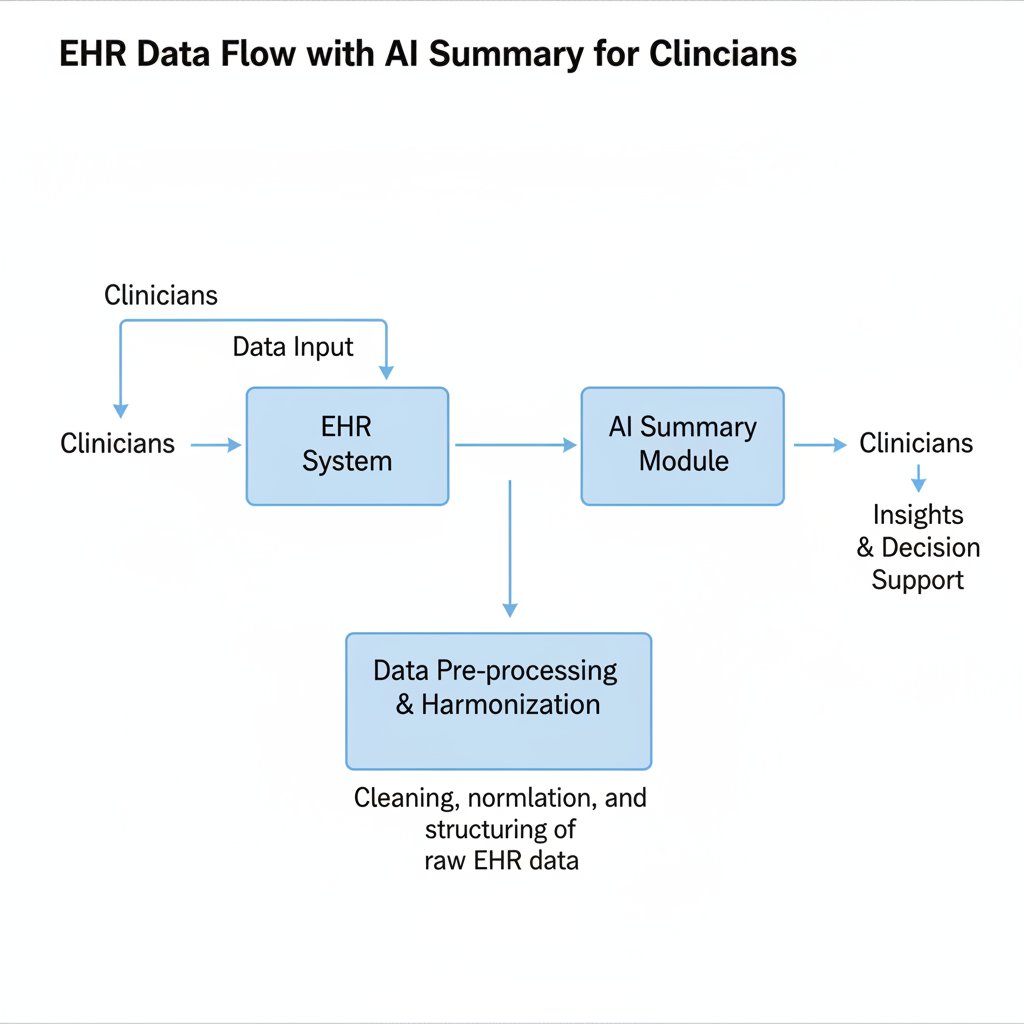
But here’s the rub: medical language is famously messy. A single abbreviation (“MS”) can mean “multiple sclerosis,” “mitral stenosis,” or “morphine sulfate.” Context is everything, and context is hard to code.
When machines misread: Edge cases and epic fails
For all their power, automated summarizers are only as good as their training data. And when machines misread, the fallout can be catastrophic. In 2023, a major hospital system reported several cases where AI-generated summaries omitted critical allergies, leading to near-miss medication errors (STAT News, 2024). In other cases, fabricated family histories (“patient has diabetes” attributed to the wrong sibling) seeded confusion for months.
Red flags your system might be missing:
- Unrecognized abbreviations: Local shorthand not present in training data.
- Copy-paste propagation: Old errors duplicated endlessly.
- Negation confusion: “No chest pain” misread as “chest pain.”
- Ambiguous time references: “Last week” relative to which visit?
- Jargon drift: Specialist language (e.g., oncology) misunderstood by generalist models.
- Data silos: Summaries ignore external records or scanned PDFs.
- Context loss: Social history (e.g., substance use) omitted or misattributed.
- Patient mismatch: Notes assigned to wrong chart due to identifier errors.
- Hallucinated facts: AI “filling in the blanks” with plausible—but wrong—details.
The costs? Financial, legal, and deeply human. Lawsuits over “failure to warn,” regulatory penalties for privacy breaches, and—most devastating—eroded trust between clinicians and their data.
As Priya, a clinical data analyst, starkly observes:
“One bad summary can snowball into a disaster.”
What’s the antidote? Rigorous validation, continuous feedback, and never trusting the system’s “confidence score” at face value.
The present-day battleground: What’s actually working in 2025
Case studies: Successes and failures in real hospitals
Let’s cut through the hype with three real-world case studies:
- Major urban center: Deployed a hybrid AI-human summarization platform for inpatient admissions. Turnaround time dropped by 40%, but error rates crept up until a parallel human audit was introduced. Staff satisfaction improved once a feedback loop was established.
- Rural clinic: Adopted an off-the-shelf summarizer to bridge staff shortages. Documentation speed improved, but integration headaches led to workflow bottlenecks and some critical data omissions.
- Telemedicine provider: Relied exclusively on AI-generated summaries for remote consults. Cost savings were significant, but patient complaints about errors and impersonality triggered a rapid review.

| Setting | ROI (Cost Savings) | Error Rate (%) | Staff Satisfaction | Turnaround Time (min) |
|---|---|---|---|---|
| Urban Hospital | $1.2M/year | 7.5 | ↑18% | 45 (down from 75) |
| Rural Clinic | $280k/year | 12.9 | ↓5% | 30 (down from 54) |
| Telemedicine Provider | $900k/year | 15.2 | ↓12% | 15 (down from 32) |
Table 3: Deployment metrics for automated summarization in three clinical settings, 2024-2025.
Source: Original analysis based on Frontiers Digital Health, 2024, ScienceDirect, 2023
So why did some projects thrive while others flopped? The winners all shared relentless iteration, transparent error reporting, and clinician-led customization. The losers fell for “set-and-forget” promises.
The rise of advanced document analysis platforms
This is where solutions like textwall.ai come into play. These platforms don’t just regurgitate data—they analyze, contextualize, and distill actionable insights at scale. The difference? Instead of bolting onto fragmented EHRs, they offer dedicated pipelines, domain-tuned models, and continuous improvement fueled by real user feedback.
Unlike legacy EHR add-ons that attempt to “summarize everything,” next-gen platforms focus on context-aware, purpose-built summaries that prioritize what’s clinically relevant.
Implementation checklist for automated summarization tools:
- Map your data silos: Identify all sources—EHR, scanned docs, device feeds.
- Define clinical priorities: What should summaries highlight? Labs, allergies, trends?
- Evaluate vendors: Demand transparency on training data, error rates, and update cycles.
- Pilot in a low-risk environment: Start small to surface unexpected issues.
- Establish human oversight: No summary should go unchecked.
- Build a feedback loop: Continuous refinement is non-negotiable.
- Train staff: Invest in change management, not just tech.
- Monitor, audit, adapt: Metrics matter—track ROI, error rates, and satisfaction.
Common pitfalls? Rushing integration, underestimating workflow change, and neglecting frontline input. Ignore these, and you risk multiplying the very problems you hoped to solve.
Beyond the hype: Myths, misconceptions, and ethical minefields
Debunking common myths about AI in patient data summarization
Let’s cut through the noise. Here are the top five misconceptions floating around hospital boardrooms:
-
“AI is always unbiased.”
Machine learning models absorb the bias in their training data. In medicine, that means historic disparities and blind spots are often repeated, not resolved. -
“Automation is plug-and-play.”
Every clinical domain has its own language, workflow, and quirks. Deploying a one-size-fits-all tool is a recipe for disaster. -
“Summaries equal understanding.”
A concise output is only as good as the context it preserves. Nuance and exception-handling are still largely human domains. -
“Regulation ensures safety.”
No comprehensive standards exist for clinical summarization; regulatory oversight lags behind the tech. -
“Errors are rare.”
Current studies show error rates ranging from 7% to 15% in real-world deployments—enough to cause serious harm (Forbes, 2024).
Key terms and why they matter:
Hallucination:
When an AI model generates plausible-sounding but false information. Deadly in clinical contexts.
Negation detection:
The process of determining if a condition is present (“no chest pain”)—crucial for correct summaries.
Note bloat:
The phenomenon of EHRs producing excessively long, redundant notes that hide important facts.
Salience ranking:
Algorithmic process of prioritizing the most clinically relevant data.
Data silo:
An isolated repository of data, often inaccessible to other systems—leading to fragmented patient histories.
Where do these myths hurt most? When vendors overpromise, or clinicians think “the computer checked it, so I don’t have to.” As Olivia, a health IT director, says:
“Trust but verify should be the new mantra.”
Time to turn to the ethical and legal dilemmas poised to shape the next phase of this revolution.
Regulatory and ethical dilemmas: Who owns the summary?
Healthcare is already a regulatory minefield. The arrival of AI-generated patient summaries adds fresh uncertainty to the mix. Global frameworks like HIPAA and GDPR now intersect with questions of patient consent, data provenance, and algorithmic accountability (Nature Medicine, 2024).
- Ambiguous ownership: Who’s responsible for errors—a clinician, the AI vendor, or the hospital?
- Informed consent: Patients may not realize summaries are AI-generated, complicating trust.
- Data privacy: Automated summaries risk exposing sensitive info in breach-prone formats.
- Audit trails: If a summary is wrong, can you trace the error back to source data?
- Transparency: Black box algorithms make it hard to explain how conclusions were reached.
- Data drift: Over time, models may degrade—who monitors ongoing performance?
- Secondary use: Summaries reused for billing, research, or marketing—without patient knowledge.

Who “owns” the summary? Legally, it’s a moving target. Ethically, the best practice is transparency, active consent, and robust auditability—practices easier said than done, especially at scale.
Practical playbook: How to implement automated summarization in your organization
Step-by-step guide: From pilot to full-scale rollout
Don’t let the allure of shiny tech blind you to the basics. Success starts before a single algorithm is deployed—with honest needs assessment:
- Assess the pain points: Where are clinicians losing the most time?
- Inventory your data: What formats, quality, and gaps exist?
- Set clear goals: Speed? Accuracy? Compliance?
- Engage stakeholders: Clinicians, IT, compliance, and patients.
- Choose your pilot area: Start small, measure everything.
- Select a vendor: Demand transparency, audit logs, and error rate disclosures.
- Train users: Focus on workflow, error-spotting, and feedback.
- Implement human review: AI isn’t a stand-alone solution.
- Scale iteratively: Expand only after measurable success.
- Monitor and audit: Track outcomes, adjust as needed.

Don’t underestimate the challenges of change management. Training, buy-in, and continuous oversight make the difference between a transformative solution and a costly boondoggle.
Checklist: Is your patient data ready for automation?
You can’t automate chaos. Before launching any summarization project, tackle data hygiene with the same seriousness as infection control.
- Standardize formats: Eliminate exotic file types and legacy media.
- Resolve identifiers: Ensure all patient records are accurately linked.
- De-duplicate entries: Remove redundant or conflicting notes.
- Clarify abbreviations: Develop and publish standard glossaries.
- Document data lineage: Track sources for every major input.
- Test for completeness: Audit random charts for missing info.
- Address privacy risks: Mask or encrypt sensitive fields.
- Integrate with existing systems: Avoid creating new silos.
- Establish error reporting: Staff must know how to flag mistakes.
- Plan for monitoring: Set up dashboards and alerts for ongoing performance.
Dealing with legacy data? Focus on staged migration and thorough validation, not just brute-force imports. For those uncertain where to begin, platforms like textwall.ai offer expertise in advanced document analysis, helping organizations sidestep the most common pitfalls.
Post-implementation, don’t let your guard down—ongoing monitoring, staff feedback, and periodic audits are essential to maintain progress.
The human factor: What clinicians and patients really experience
Clinician perspectives: Trust, workload, and workflow
On the frontline, reactions to automation are as varied as the clinicians themselves. For some, it’s a godsend—relieving “death by a thousand clicks.” For others, it’s another black box, one more thing to double-check on a hectic shift.

Workflow changes have yielded mixed results: some teams report faster rounds and reduced administrative burden, while others find new reasons for alarm—missed nuances, unexpected errors, and the nagging suspicion that the machine “didn’t get it.”
| Survey Question | Pre-Automation Score | Post-Automation Score |
|---|---|---|
| Trust in patient summaries | 7.1 / 10 | 6.8 / 10 |
| Workload perception | 8.3 / 10 | 6.9 / 10 |
| Confidence in data accuracy | 7.5 / 10 | 7.0 / 10 |
| Willingness to recommend | 6.2 / 10 | 7.5 / 10 |
Table 4: Clinician trust and satisfaction survey, 2024, across 10 hospitals deploying automated summarization.
Source: Original analysis based on Frontiers Digital Health, 2024
Continuous feedback and rapid iteration are vital. Ignoring frontline skepticism means undermining both adoption and safety.
Patient voices: Do summaries help—or distance?
Patients, meanwhile, often find themselves caught between the promise of digital empowerment and the fear of depersonalization. Some appreciate the accessibility and clarity of summarized data; others worry that critical details are lost in translation.
As Henry, a participant in a patient focus group, puts it:
“I want my doctor to understand me, not just my data.”
Accessibility perks abound—patients with low health literacy benefit from plain-language summaries, while multilingual families get more accurate translations. But communication pitfalls are real: errors or omissions in AI-generated summaries can fuel anxiety, confusion, or distrust.
- Surprise at errors: Patients spot mistakes faster than expected, raising concern.
- Appreciation for clarity: Layperson summaries demystify jargon.
- Fear of depersonalization: “My story doesn’t fit in one paragraph.”
- Confusion over sources: Is this what my doctor wrote, or the computer?
- Reluctance to challenge: Some hesitate to correct errors, doubting their own knowledge.
- Privacy worries: Who else sees these summaries?
- Gratitude for speed: Quick updates reduce uncertainty in hospital stays.
- Skepticism about accuracy: “If it’s wrong here, what else is missing?”
Societally, the stakes are high: trust in medical systems is as much about communication as it is about clinical outcomes.
Unconventional uses and future frontiers
Beyond the hospital: Research, pharma, and public health
Automated summarization isn’t just a clinical tool—it’s transforming adjacent fields, from biomedical research to pharmaceutical trials and public health surveillance.

Researchers now synthesize massive troves of patient records to spot trends, identify treatment gaps, and accelerate clinical trial recruitment. Pharma companies use summarization to rapidly ingest adverse event reports. Public health agencies monitor syndromic surveillance in real time.
Top 7 unconventional uses:
- Adverse event detection in pharmacovigilance.
- Cohort identification for research trials.
- Pandemic surveillance from global EHR streams.
- Insurance claims analysis for fraud detection.
- Litigation support in medical malpractice cases.
- Population health management for targeted interventions.
- Real-time analytics for emergency response.
Lessons for healthcare? The need for cross-disciplinary collaboration, adaptable platforms, and robust validation protocols transcends clinical walls.
What’s next? Predictive and prescriptive summaries
Summarization is evolving rapidly—from static recaps to predictive and prescriptive insights that highlight not just what happened, but what might happen next and what to do about it.
| Summary Type | Features | Risks | Use Cases |
|---|---|---|---|
| Descriptive | “What happened?” | Omissions, bias | Discharge summaries, referrals |
| Predictive | “What’s likely to happen next?” | Overreliance, false alarms | Early warning systems, triage |
| Prescriptive | “What should we do now?” | Misguided recommendations | Decision support, care pathways |
Table 5: Comparison of descriptive, predictive, and prescriptive summarization models—features, risks, and applications. Source: Original analysis based on ScienceDirect, 2023, [J Biomed Inform, 2024]
Expert consensus is clear: tools like advanced document analysis platforms are leading this shift—enabling clinicians to move from retrospective review to proactive action. Human judgment remains irreplaceable, but AI is raising the floor on what’s possible.
The ultimate question: Are we ready for a world where machines not only summarize the past but shape the future of medical decisions? The jury’s still out, but the conversation is anything but theoretical.
Supplement: Adjacent topics, controversies, and reader takeaways
Common controversies and debates in data automation
If you think everyone agrees on the value of automated summarization, think again. The debates are fierce, and the stakes are growing.
- Privacy vs. utility: More data, more risk—how much is too much?
- Algorithmic transparency: Should vendors disclose the guts of their models?
- Job displacement: Will automation sideline skilled data entry staff or augment their roles?
- Liability: Who pays when AI gets it wrong?
- Vendor lock-in: Do proprietary solutions stifle innovation?
- Over-policing: Are regulatory demands choking progress?
- Algorithmic bias: Can we ever fully “de-bias” historical data?
Each point has practical consequences for IT departments, clinical leaders, and—ultimately—patients.
Industry stances are in flux: some regulators demand tighter oversight, while others push for fast-tracked innovation. The only constant? Change.
Quick reference: Resources, further reading, and expert contacts
For readers hungry for more, here’s a curated selection:
- World Economic Forum: How to harness health data for better outcomes (2024)
- STAT News: Hospitals and AI clinical note summaries—accuracy risks (2024)
- Frontiers Digital Health: Clinical NLP and automated summarization (2024)
- Nature Medicine: Ethical and legal risks of AI in medicine (2024)
- ScienceDirect: Automated summarization in healthcare—state of the art (2023)
Recommended resources:
- White papers on EHR integration strategies
- Webinars from clinical informatics societies
- Expert blogs (e.g., academic medical centers, textwall.ai)
- Workshops on digital health ethics
For organizations ready to dig deeper, textwall.ai stands as a trusted launching point—offering guidance and analysis expertise to help you navigate this complex, ever-shifting terrain.
The final word? If you’re responsible for patient data, you owe it to yourself—and your patients—to question every summary, audit every workflow, and never accept “AI said so” as an answer.
Sources
References cited in this article
- World Economic Forum, 2024(weforum.org)
- STAT News, 2024(statnews.com)
- Frontiers Digital Health, 2024(frontiersin.org)
- PMC, 2023(pmc.ncbi.nlm.nih.gov)
- ScienceDirect, 2023(sciencedirect.com)
- Forbes, 2024(forbes.com)
- Nature Medicine, 2024(nature.com)
- PubMed, 2023-2024(pubmed.ncbi.nlm.nih.gov)
- M3 India, 2024(m3india.in)
- PMC, 2020(pmc.ncbi.nlm.nih.gov)
- JMIR, 2024(jmir.org)
- PMC, 2023(ncbi.nlm.nih.gov)
- Atlan, 2024(atlan.com)
- Innovaccer, 2024(innovaccer.com)
- PMC2655814(pmc.ncbi.nlm.nih.gov)
- NCBI Books NBK610545(ncbi.nlm.nih.gov)
- NEJM Catalyst, 2024(catalyst.nejm.org)
- Nat Med, 2024(pmc.ncbi.nlm.nih.gov)
- ResearchGate, 2025(researchgate.net)
- UiPath, 2025(hitconsultant.net)
- arXiv, 2025(arxiv.org)
- Springer, 2024(link.springer.com)
- Forbes, 2023(forbes.com)
- Lancet Digital Health, 2024(thelancet.com)
- WHO, 2023(who.int)
- Shaip, 2024(shaip.com)
- Penn State, 2023(psu.edu)
- PHII Data Quality, 2023(phii.org)
- JMIR Med Inform, 2023(medinform.jmir.org)
- PMC, 2024(pmc.ncbi.nlm.nih.gov)
- Quantiphi, 2024(quantiphi.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
Why is information overload a problem in hospitals?
Hospitals generate approximately 50 petabytes of patient data annually, but up to 97% of this data goes unused in digital silos, causing vital insights to slip through the cracks and leading to missed diagnoses, delayed interventions, and medication errors.
What are the real-world consequences of clinicians being overwhelmed by patient data?
The article identifies four main consequences: delayed diagnoses when critical findings hide in routine notes, therapeutic inertia where clinicians default to status quo due to data overload, communication breakdowns between specialists, and accelerated clinician burnout from the pressure to review all information.
What is the paradox of automated summarization in healthcare?
While automated summarization of patient data promises to transform healthcare chaos into clinical clarity, the article warns that AI engines sometimes hallucinate facts, creating ethical risks when accuracy is literally life or death for patients.
What does Julia, the MD informatics lead, say about the state of hospital data?
Julia describes the situation bluntly as: 'We're drowning in information, but starved for actionable insight,' highlighting the gap between the volume of available data and its practical utility in clinical decision-making.
Keep Reading
Explore more from Advanced document analysis

Is AI Really Fixing Patient Record Chaos—Or Making It Worse?
Automate patient record summarization for real impact: Discover the raw truth, risks, and rewards of next-gen clinical documentation. Read before you automate.

Is AI Document Summarization Saving or Endangering Healthcare?
Document summarization for healthcare is transforming medical records—discover the raw realities, hidden risks, and solutions experts rely on. Uncover what others miss.

Can AI Really Fix the Chaos in Healthcare Records?
If you’ve ever watched a clinician’s face as they scroll—numb-fingered, thousand-yard stare—through page after page of labyrinthine medical records at 3 a.m.,

Are AI Medical Summaries Fixing or Failing Healthcare?
Document summarization for healthcare accuracy is reshaping patient safety—uncover the hidden risks, expert strategies, and what the future holds. Don’t miss the real story.

The Dark Side of Patient Record Summaries—What Nobody Admits
Summarize patient records like a pro—uncover myths, hidden risks, and bold new solutions for 2026. Don’t let your summaries fail you. Get ahead now.

Are You Ready for the Brutal Reality of Document Summarization in Healthcare?
Document summarization healthcare use is transforming hospitals. Discover hard truths, real risks, and breakthrough results in this deep-dive. Read before you act.

Why Summarizing Medical Records Could Save—Or Ruin—Your Case
Summarize medical records with confidence—discover the hidden pitfalls, expert strategies, and shocking realities that change how you see every patient file.

Automated Report Summarization: Speed, Risk and Who to Trust
Discover insights about automated report summarization

What Nobody Tells You About Automating Patient Record Analysis
Tools for automating patient record analysis are reshaping healthcare in 2026. Uncover game-changing insights, real risks, and expert tips for smarter adoption.















