
Automated Document Recognition in 2026: What Breaks and What Wins
Imagine your desk groaning under the weight of documents. Contracts. Invoices. Reports marked “urgent” with a highlighter that’s seen better days. Now zoom out: your business isn’t alone. Across industries, organizations are suffocating under mountains of paperwork—digital and physical. Automated document recognition promises salvation, but the reality? It’s far messier, more expensive, and more transformative than the buzzword-laden sales pitches admit. This isn’t just another “how AI saves the world” story. Here, we rip into the brutal truths, expose the unseen costs, and unpack how automated document recognition (ADR) is disrupting workflows, profits, and even the definition of trust. If you think a scanner and a fancy acronym will solve your document chaos, buckle up. The AI revolution has teeth—and it’s coming for your files.
Why your business still drowns in documents (and what that really costs you)
The staggering scale of manual document chaos
The world is producing data at an eye-watering pace. IDC estimates that by the end of 2025, global data will reach 175 zettabytes, much of it unstructured and document-based. Yet, nearly 80% of enterprise information remains trapped in documents, emails, and forms, according to Gartner, 2024. Manual handling is still the norm for critical tasks, from processing invoices to onboarding clients. The fallout? An army of knowledge workers burning hours copying, pasting, and rechecking information—while the clock (and payroll) ticks mercilessly on.

Hidden costs spiral far beyond payroll. Manual document management is a breeding ground for human error: think misfiled contracts, lost receipts, or “just one” typo that nukes a quarterly report. Compliance fines lurk around every corner, as regulators show zero sympathy for missing paperwork. And then there’s the speed penalty—manual tasks can drag critical processes from hours into days, bleeding competitiveness.
| Processing Type | Labor (Annual) | Error Rate (%) | Compliance Risk | Avg. Speed (Per Doc) | Total Annual Cost |
|---|---|---|---|---|---|
| Manual (Paper & Digital) | $85,000 | 3.2 | High | 12 min | $125,000 |
| Automated (ADR + QA) | $38,000 | 0.8 | Low | 1.8 min | $48,000 |
Table 1: Manual vs. Automated Processing—Hidden Costs Breakdown. Source: Original analysis based on Gartner, 2024, AIIM, 2024.
Real-world horror stories: When document overload ruins lives
Consider this: a major healthcare provider in the US lost track of 1,500 patient test results due to a manual filing error. The fallout? Missed diagnoses, regulatory penalties, and irreparable reputational damage. Or take the mid-sized finance firm that misplaced a single invoice in a mountain of paperwork—only to be blindsided by a $120,000 loss months later.
"One missed invoice cost us six figures—nobody saw it coming." — Alex, Operations Lead, Finance Sector (Illustrative)
These aren’t isolated flukes. Manual document chaos has a domino effect: one error leads to days of detective work, missed deadlines, and, too often, compliance nightmares. The cost isn’t just money—it’s trust, credibility, and even lives in sectors like healthcare or logistics. The paperless office remains a myth for many, not because of a lack of will, but because the tools and habits haven’t caught up with the data deluge.
The myth of 'just going digital'—why scanning isn’t enough
Here’s the hard truth: scanning documents into PDFs is not automation. It’s archiving on life support. Without intelligent extraction and tagging, digital files become just as invisible as paper—only harder to lose behind the couch.
- Pitfall 1: "Searchable PDFs are enough." In reality, OCR-only files are often error-ridden and lack real metadata, making retrieval and compliance audits a nightmare.
- Pitfall 2: "Scanning solves compliance." Auditors want structured, traceable records, not a directory of cryptic file names and fuzzy text.
- Pitfall 3: "Digital = Secure." A digitized mess is still a mess—only now a breach exposes every mistake instantly.
- Pitfall 4: "Manual checks will catch errors." Over-reliance on human review in large digital archives is wishful thinking. Errors hide in plain sight.
- Pitfall 5: "Once digitized, always accessible." Without robust indexing and classification, finding the right file is searching for a pixel in a haystack.
Merely “going digital” is the equivalent of moving your clutter from the garage to the attic—out of sight, out of mind, but just as dangerous.
Automated document recognition, decoded: more than just OCR
From typewriters to transformers: The wild evolution of document tech
Automated document recognition has roots stretching back to the earliest days of business bureaucracy. Typewriters gave way to word processors; then came early OCR (Optical Character Recognition) in the 1980s, promising to “read” printed text. But real transformation exploded only in the last decade, as machine learning and large language models (LLMs) began devouring messy, complex documents by the billion.
| Decade | Key Innovation | Impact |
|---|---|---|
| 1950s | Typewriters, Carbon Copies | Standardized document creation |
| 1980s | Early OCR | Basic machine reading of printed text |
| 2000s | Rule-Based Extraction | First attempts at automated data capture |
| 2010s | Machine Learning OCR | Handwriting and complex layouts possible |
| 2020s | LLMs, Generative AI | Deep understanding, multi-language, real-time |
Table 2: Timeline of Document Recognition Technology. Source: G2 OCR Software Reviews 2025.

The leap from rule-based extraction to transformer-powered AI has been as disruptive as the jump from rotary phones to smartphones: not only can machines now “read,” but they can also understand, categorize, and summarize—even for documents that look like a bomb went off in an archive.
How today’s AI cracks the code on complex documents
Forget the black-box mystique: at its core, AI-driven document recognition uses layers of algorithms—neural networks, LLMs, and natural language processing (NLP)—to map pixels to meaning. Picture an army of digital analysts swarming each page, segmenting text, tables, logos, signatures, and even doodles, before assembling a structured output.
If traditional OCR is a robot reading out a shopping list, AI-powered ADR is a multilingual detective, cross-checking context, intent, and even sentiment. Modern systems don’t just “see” words—they infer relationships, spot anomalies, and flag oddities that would trip up both junior interns and legacy software.
For the technical crowd: think convolutional neural networks (CNNs) for visual parsing, transformers for language context, and entity recognition for extracting the juicy details. For everyone else: imagine a team that never gets tired, never skips lunch, and never misfiles page 12.
Beyond text: Recognizing handwriting, stamps, and chaos
Real-world documents rarely play by the rules. They come scrawled in ballpoint pen, stamped with approval seals, splattered with coffee, or written in three languages on the same page. Here’s how state-of-the-art automated document recognition tackles a “problem child” invoice:
- Image Preprocessing: Cleans, deskews, and enhances the scanned file for maximum clarity.
- Segmentation: Identifies blocks—text, tables, images, signatures—using computer vision.
- Language Detection: Recognizes all languages present, prepping for multi-lingual OCR.
- Handwriting Recognition: Applies specialized neural nets to handwritten notes and signatures.
- Stamp & Seal Extraction: Flags official stamps or marks as separate entities.
- Table Parsing: Reads structured tables, even across merged or irregular cells.
- Named Entity Recognition (NER): Pulls out companies, dates, amounts, and other context.
- Validation & Postprocessing: Cross-references extracted data against business rules and flag anomalies.
Every step is a digital wrestling match with entropy, but the win is clear: usable, trustworthy data where chaos once reigned.
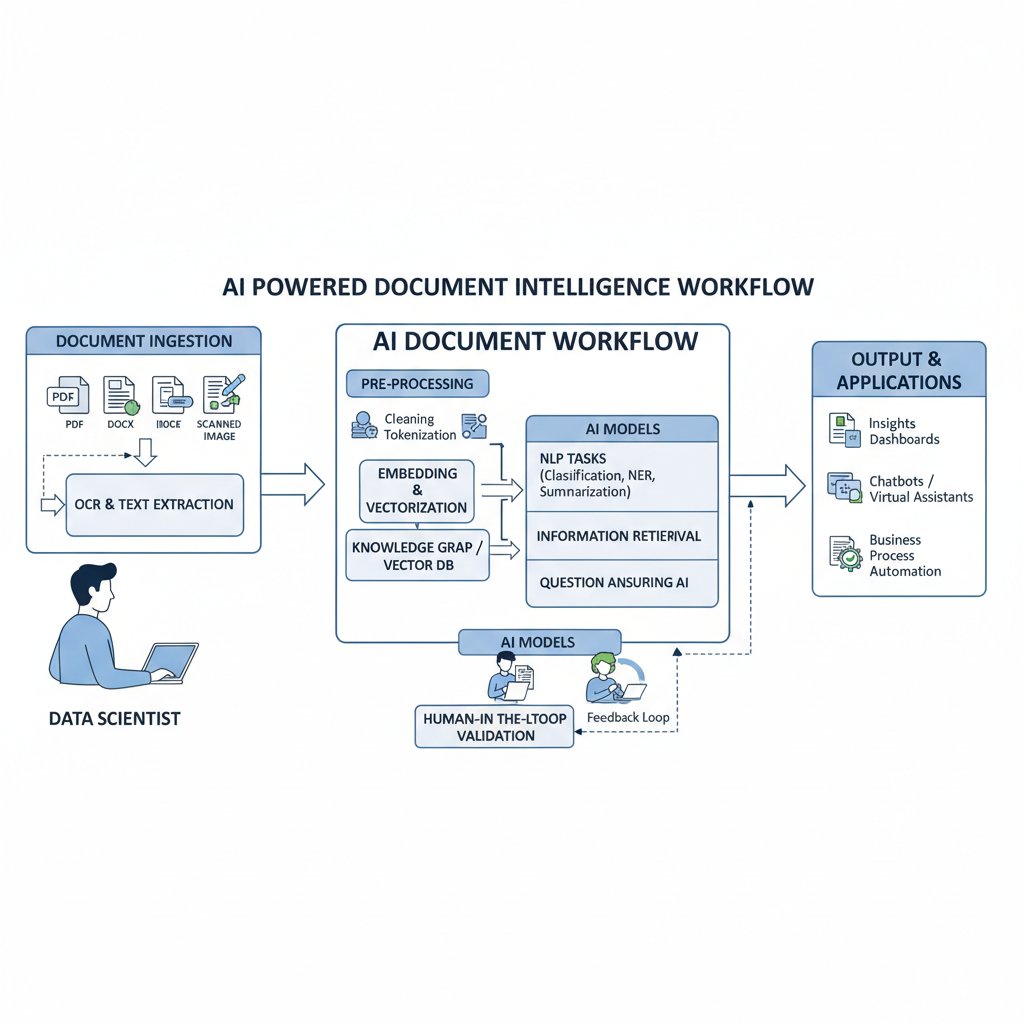
How AI document recognition actually works (and where it fails hard)
Under the hood: Anatomy of an AI recognition engine
The guts of an automated document recognition system are a ballet of preprocessing, segmentation, recognition, and validation layers. Here’s what’s really happening:
- Preprocessing: Enhances image quality—forgives bad scans, corrects angles, removes noise.
- Segmentation: Locates blocks of interest—text, tables, images.
- Model Selection: Chooses the right recognition model (e.g. printed text vs. handwriting).
- Extraction: Pulls raw data using OCR, NLP, and entity recognition.
- Postprocessing: Applies business rules, spell checks, and context validation.
- Human-in-the-Loop (Optional): Flags low-confidence results for manual review.
- Audit Logging: Tracks changes for compliance and traceability.
Key terms explained:
Optical Character Recognition—a technology that “reads” printed or written text from images or documents. Born in the 1980s, still evolving.
Named Entity Recognition—AI models that find and label key entities like names, dates, and amounts within unstructured text. Critical for extracting context, not just content.
A machine-generated probability (often 0-1) indicating how “sure” the system is about each extracted element. High scores mean less human review; low scores mean more manual checks.
Common error traps and why ‘accuracy’ is a minefield
In the pristine world of AI research, accuracy rates for document recognition may hit 99%—until real-world chaos arrives. Complex layouts, smeared ink, and non-standard formats can send error rates skyrocketing.
- Red flag 1: “Lab accuracy” touted instead of real-world benchmarks. Always demand field-tested numbers.
- Red flag 2: Overfitting on simple forms—systems that nail invoices, but collapse on multi-page contracts.
- Red flag 3: Failure to handle multi-language or handwriting without massive accuracy drops.
- Red flag 4: Hidden costs in correcting “false positives” and “missed entities.”
- Red flag 5: Black-box logic—no transparency into why data was (mis)classified.
- Red flag 6: Inability to adapt to new document types without costly retraining.
- Red flag 7: No human-in-the-loop option, leaving high-risk decisions fully automated.
Accuracy, it turns out, is a moving target—one that shifts with every new form, scan setting, and regulatory twist.
Manual review: The controversial comeback nobody talks about
For all the machine hype, the industry’s worst-kept secret is that human review isn’t dead—it’s just evolved. “Human-in-the-loop” systems deliver higher quality by letting people check or correct low-confidence extractions.
"No machine gets it right 100%—that’s not how the real world works." — Priya, Document Automation Specialist (Illustrative)
Hybrid workflows, where AI handles the grunt work and humans the edge cases, are proving to offer the best ROI. In fact, research from AIIM, 2024 shows that organizations with a robust “human fail-safe” see error rates drop by 65% compared to fully automated or fully manual approaches.
Industry battlegrounds: Where automated document recognition changes everything
Finance, healthcare, logistics: High stakes, zero room for error
In heavily regulated sectors, the risks (and rewards) of document automation are magnified. In finance, a single misclassified wire transfer can trigger regulatory scrutiny—or worse, fraud. In healthcare, lost or misread patient records can cost lives and licensing. Logistics, with its tsunami of bills of lading and manifests, faces speed and accuracy pressures no manual team can match.
| Industry | Typical Docs | Error Cost (Per Incident) | Automation Win |
|---|---|---|---|
| Finance | Invoices, KYC, Loans | $50,000+ | Instant compliance checks, fraud flagging |
| Healthcare | Records, Claims | $5,000–$500,000 | Acceleration of patient intake, error reduction |
| Logistics | Manifests, Bills | $1,000–$100,000 | Real-time tracking, faster customs clearance |
Table 3: Sector-by-sector automation impact. Source: Original analysis based on Gartner, 2024, AIIM, 2024.

The bottom line: the bigger the stakes, the less room for error—and thus the higher the pressure to get automated document recognition right.
Case study: The million-dollar invoice rescue
Let’s break down a real (but anonymized) scenario: A global manufacturer discovers a $1.2 million invoice buried in a backlog. Thanks to automated document recognition, the invoice is flagged before write-off.
How the rescue unfolded—step by step:
- Invoice batch scanned and uploaded.
- AI models detect high-value entries via entity recognition.
- System flags low-confidence fields—manual review triggers.
- Human specialist verifies details, confirms it’s unpaid.
- Automated cross-check runs against payment database.
- Alert sent to accounts team.
- Payment scheduled—loss averted.
If automation had failed, the invoice would have been written off—erasing a quarter’s profit margin. The alternative? Months of manual sifting, with no guarantee of success.
When regulation meets automation: Compliance nightmares and solutions
GDPR in Europe and HIPAA in the US have made data compliance a full-contact sport. Manual audits are expensive and slow, but automation brings its own risk: one misclassified document, and sensitive data leaks out.
Automated systems can create audit trails, access logs, and role-based controls, slashing audit prep from weeks to hours. Yet, poorly configured ADR can just as easily magnify errors, embedding them in immutable archives.
Regulatory terms explained:
General Data Protection Regulation—Europe’s strict data privacy law. Requires strict access controls, audit trails, and right-to-forget compliance.
Health Insurance Portability and Accountability Act—US healthcare privacy law. Dictates handling, storage, and access rules for medical documents.
The ability to produce verifiable, complete records on demand. Automated systems can deliver this—when set up right.
Choosing the right automated document recognition system: No-BS guide
AI, OCR, hybrid, bespoke—what’s hype and what’s real?
Not all document recognition is created equal. Here’s how the tech stacks up:
| Feature / Use Case | OCR Only | Pure AI | Hybrid (AI + OCR) |
|---|---|---|---|
| Simple forms | Excellent | Good | Good |
| Complex layouts | Poor | Excellent | Best |
| Handwriting | Poor | Good | Best |
| Speed | Fast | Moderate | Fast |
| Cost | Low | High | Mid |
| Transparency | Good | Varies | Good |
| Adaptability | Low | High | High |
Table 4: Feature matrix—OCR vs AI vs Hybrid. Source: Original analysis based on G2 OCR Software Reviews 2025, AIIM, 2024.
For buyers, the real-world implications are stark: choose pure OCR for basic, high-volume tasks; AI for messy, high-risk documents; hybrid for true “Swiss army knife” versatility. But beware—costs scale with complexity, and vendor lock-in is a real risk with proprietary tech.
Implementation war stories: What goes wrong (and how to dodge disaster)
Many companies leap into automation without a parachute. The result? Burned budgets and years lost. One Fortune 100 firm spent $2M on a bespoke solution that couldn’t handle 10% of their document types.
- Mistake 1: Underestimating data quality requirements. Garbage in, garbage out.
- Mistake 2: Ignoring change management—users resist, adoption lags.
- Mistake 3: Overreliance on a single vendor—proprietary lock-in.
- Mistake 4: Skipping pilot tests—systems fail when scaled.
- Mistake 5: Failing to plan for continuous updates—models stagnate.
- Mistake 6: Neglecting integration points—legacy systems choke.
- Mistake 7: Not budgeting for human review—error rates spike.
- Mistake 8: Siloed deployment—data stuck in walled gardens.
"We learned more from our failures than any vendor’s pitch." — Jordan, Digital Transformation Lead (Illustrative)
Remedies? Pilot everything. Work with data first. Demand open APIs. Plan for ongoing training—for both machines and humans.
Priority checklist: Getting started without getting burned
Kick off your automation journey with these tactical steps:
- Map document flows—what, where, who, how many.
- Audit current error rates and compliance risks.
- Identify “quick win” document types.
- Gather high-quality training data.
- Select vendors with open standards and strong support.
- Run pilots with real-world data, not demos.
- Secure stakeholder buy-in—train your team early.
- Plan for hybrid workflows (human-in-the-loop).
- Ensure robust audit and compliance logging.
- Budget for continuous improvement and retraining.
- Integrate with existing systems gradually.
- Monitor, tweak, and celebrate wins—then scale.
Before you plunge into advanced strategies, nail these basics—survival depends on it.
Advanced tactics the vendors won’t tell you
Hacking accuracy: Training, tuning, and real-world testing
The secret sauce in high-performing ADR is relentless data refinement. Most models choke on messy, real-world documents—unless you feed them enormous, diverse, and regularly updated datasets. Organizations like textwall.ai have built their reputations on continuous model tuning, using customer feedback and live error reporting.
Consider three testing scenarios:
- Controlled lab: Clean, standardized forms—models hit 98%+ accuracy.
- “In the wild:” Mixed formats, partial scans—accuracy drops to 85%.
- Adversarial stress test: Deliberately corrupted, multi-language, and hand-annotated docs—models range from 70-90%, flagging more items for review.
Each scenario reveals new blind spots. The lesson: without ongoing real-world validation, even the smartest AI is little more than a glorified calculator.

Integrating with legacy systems: The secret to not losing your mind
Most organizations don’t have the luxury of starting from scratch. Legacy systems are everywhere, and integrating ADR is less plug-and-play, more open-heart surgery.
- Tip 1: Use middleware or APIs to bridge gaps without rewriting ancient code.
- Tip 2: Prioritize open standards (XML, JSON) for data exchange.
- Tip 3: Start with “low risk” documents before tackling mission-critical flows.
- Tip 4: Document every integration point (and every workaround).
- Tip 5: Build rollback plans in case of failures.
Survival depends on patience, a ruthless eye for edge cases, and a willingness to abandon sunk cost fallacies. Integration is never pretty—but when done right, it unleashes exponential value.
Scaling up: Going from pilot project to enterprise-wide rollout
Scaling from a pilot to full enterprise deployment is a marathon, not a sprint. Here’s a proven roadmap:
- Identify high-impact document types.
- Secure cross-departmental buy-in.
- Standardize data formats and governance.
- Roll out phased pilots—measure, refine, repeat.
- Train staff in both tech and new workflows.
- Transition core processes, keeping manual backups.
- Migrate to full production, with continuous QA.
Each phase has pitfalls: pilot fatigue, scope creep, and stakeholder churn. To avoid disaster, communicate relentlessly, celebrate early wins, and never stop measuring ROI.
The dark side: Bias, privacy, and the ethics of automated document recognition
AI bias: When your document workflow discriminates
ADR models are only as good as the data they train on. Bias in training sets—missing languages, overrepresented formats—can lead to unequal error rates, perpetuating discrimination. In HR, for example, automated resume parsing has been found to overlook minority-sounding names or non-Western credentials, according to Harvard Business Review, 2024.

Real-world incidents have forced companies to revisit their models, retrain with diverse data, and open their “black boxes” to public scrutiny. If your ADR system can’t explain its logic—and correct for bias—it’s a liability, not an asset.
Privacy isn’t dead (yet): Protecting sensitive information
The temptation to throw every document into the AI maw must be balanced with ironclad privacy. Encryption, audit trails, and access controls aren’t optional—they’re the baseline.
- Encryption in transit and at rest: Prevents unauthorized snooping.
- Role-based access controls: Limits sensitive document access to the right people.
- Comprehensive audit logs: Tracks every touchpoint for compliance.
- Data minimization: Only process what’s necessary; purge when done.
- Regular penetration testing: Stay ahead of hackers and compliance auditors.
Regulatory trends are only tightening—non-compliance means not just fines, but public shaming and business bans.
Ethical automation: Can we trust machines with critical documents?
Trust in ADR is built not on hype, but on transparency. Users, regulators, and the public demand clarity: How does the system make decisions? Can errors be detected and fixed? Is there recourse if things go wrong?
"Trust is built on transparency, not perfection." — Lina, Information Governance Lead (Illustrative)
For organizations, the bar isn’t “no mistakes ever”—it’s knowing when, why, and how mistakes happen, and having the tools to fix them. Anything less is digital snake oil.
What’s next? The 2025 outlook for automated document recognition
Breakthroughs on the horizon: What’s coming faster than you think
As of mid-2025, ADR is seeing a surge in multi-modal AI—systems that parse not just text, but images, tables, and even voice notes. Real-time analysis is bringing document processing down to seconds, not hours. Voice-to-document AI is blurring lines between transcription and analysis, especially in legal and healthcare.
Emerging trends with disruptive potential:
- Semantic search: Instantly finds meaning, not just keywords, across millions of documents.
- Handwriting-to-data: Near-human accuracy on messy, multi-language scripts.
- Cloud-first IDP: Intelligent Document Processing platforms deliver global scalability.

These aren’t distant dreams—they’re being piloted by organizations that refuse to drown in paperwork or get left behind.
Why the human factor isn’t going away (and that’s a good thing)
For all their speed and smarts, ADR systems fall short on nuance, context, and judgment. Humans still outperform AI in:
- Interpreting ambiguous documents: Context often trumps code.
- Handling exceptions: Edge cases baffle even the best models.
- Detecting fraud or subtle manipulation: Experience matters.
- Managing escalation and mediation: Empathy wins over logic.
- Ensuring compliance in gray areas: Human oversight is irreplaceable.
Blending machine speed with human judgment isn’t a crutch—it’s a competitive advantage.
How to future-proof your document strategy—starting today
Don’t wait for the perfect tool—act now with these tactics:
- Audit your document landscape quarterly.
- Build diverse, up-to-date training datasets.
- Integrate human review where risk is highest.
- Track key metrics—accuracy, speed, compliance rates.
- Invest in partner relationships with proven ADR experts like textwall.ai.
- Stay agile—updates and retraining are never optional.
Document chaos is a choice. Clarity—with the right strategy and partners—is within reach.
Beyond automation: Adjacent trends shaping the future of work
The rise of end-to-end workflow automation
ADR isn’t a standalone fix; it’s the beating heart of next-generation workflow automation. Integrated with Robotic Process Automation (RPA) and Business Process Management (BPM) tools, ADR enables seamless, touchless business flows—think contracts signed, classified, routed, and stored, all without human bottlenecks.

Cross-industry examples abound: insurance claims processed in minutes, supply chain docs routed instantly to customs, HR onboarding handled in a single digital journey.
AI-powered insights: Turning documents into decisions
With information overload the new default, the real value of ADR is in actionable intelligence. Automated systems can now spot trends, surface outliers, and enable decisions that would take weeks for human teams.
- Detecting market shifts before competitors via invoice and contract analysis.
- Flagging compliance risks from recurring patterns in legal docs.
- Identifying process bottlenecks through meta-data analytics.
- Spotting fraud trends in financial paperwork.
- Benchmarking supplier performance by analyzing delivery documents.
Each insight transforms a sea of information into a springboard for strategic advantage.
Global shifts: How document automation is redrawing the world map
Remote work and global supply chains are making document automation not just a convenience, but a necessity. From GDPR in Europe to CCPA in California, regulatory hurdles are multiplying.
| Region | Adoption Rate (%) | Major Regulatory Barriers |
|---|---|---|
| North America | 62 | CCPA, SOX, HIPAA |
| Europe | 71 | GDPR, eIDAS |
| Asia-Pacific | 48 | Data localization, sector-specific rules |
| Latin America | 39 | Infrastructure gaps, varied compliance |
Table 5: Global adoption rates and regulatory hurdles. Source: Original analysis based on Gartner, 2024, AIIM, 2024.
The upshot? ADR isn’t just a local upgrade—it’s a ticket to staying globally competitive, agile, and compliant.
Conclusion
Automated document recognition isn’t a silver bullet—it’s a battlefield. The hard truths? Complexity, cost, and resistance to change are everywhere. But the wins—faster workflows, fewer errors, ironclad compliance—are rewriting what’s possible in business and beyond. As we’ve seen, successful ADR demands more than technology: it takes a ruthless focus on data, integration, human oversight, and a relentless drive for clarity. Don’t fall for the buzzwords or shortcuts. The organizations thriving in 2025 are those who face the messy realities head on, partner with trusted experts like textwall.ai, and never stop tuning their approach. If you’re still drowning in documents, the lifeline is here—but it’s not what you think. It’s smarter, harder, and, yes, more human than ever.
Sources
References cited in this article
- G2 OCR Software Reviews 2025(learn.g2.com)
- DotComm Magazine: AI in Document Recognition 2025(dotcommagazine.com)
- Base64.ai: 5 Breakthroughs in AI IDP 2025(base64.ai)
- FileCenter: Document Management Statistics(filecenter.com)
- Ripcord: True Cost of Poor Document Management(blog.ripcord.com)
- CheckHub: Document Management Challenges 2024(checkhub.io)
- MetaSource: Scanning Myths(metasource.com)
- SecureScan: Scanning vs. Digitization(securescan.com)
- Rely Services: Importance of Document Digitization in 2024(relyservices.com)
- Market.us: Intelligent Document Processing Stats(scoop.market.us)
- Docsumo: IDP Trends 2025(docsumo.com)
- Creatum: ICR vs OCR(creatum.online)
- ThinkOwl: Intelligent Document Recognition(thinkowl.com)
- DocuWare: Automated Document Processing(start.docuware.com)
- ABBYY: AI Document Processing(abbyy.com)
- Forage.ai: Guide to IDP 2025(forage.ai)
- Marketing Scoop: Handwriting Recognition 2025(marketingscoop.com)
- ExpertBeacon: Handwriting Recognition(expertbeacon.com)
- IBM: What is Document AI?(ibm.com)
- Evolution AI: Intelligent Document Recognition(evolution.ai)
- DocumentLLM: AI Document Processing 2024(documentllm.com)
- Synthesia: 8 AI Trends 2025(synthesia.io)
- TechTarget: AI and ML Trends 2025(techtarget.com)
- National University: AI Statistics 2024-2025(nu.edu)
- Parseur: Invoice Processing(parseur.com)
- zenphi: Invoice Automation Case Study(zenphi.com)
- KlearStack: IDP Trends 2024(medium.com)
- CFlow: Best OCR Software 2025(cflowapps.com)
- Auxis: Top 2024 IDP Tools(auxis.com)
- Gartner: IDP Reviews(gartner.com)
- Roboflow: Guide to AI OCR 2025(blog.roboflow.com)
- Arya AI: Best OCR APIs 2025(arya.ai)
- Auxis: Top IDP Tools 2024(auxis.com)
- Epsillion: Document Automation Mistakes(epsillion.com)
- DMS Solutions: IDP Challenges(dms-solutions.co)
- Suvit: Why IDP Implementations Fail(suvit.io)
- Lumenalta: AI Readiness Checklist 2025(lumenalta.com)
- OneTrust: AI Project Intake Checklist(onetrust.com)
- ScienceSoft: Document Automation Trends(scnsoft.com)
- Docsumo: IDP Market Report 2025(docsumo.com)
- ScaleHub: 2025 IDP Guide(scalehub.com)
- Bain: Automation Scorecard 2024(bain.com)
- ChooseAcacia: Scaling AI(chooseacacia.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What percentage of enterprise information is still trapped in documents according to the article?
According to Gartner 2024 data cited in the article, nearly 80% of enterprise information remains trapped in documents, emails, and forms.
What are the main hidden costs of manual document management mentioned in the article?
The article identifies three main hidden costs: human errors like misfiled contracts and typos, compliance fines from missing paperwork, and speed penalties that drag critical processes from hours into days.
How much faster is automated document recognition compared to manual processing according to the article's table?
According to Table 1, automated ADR processing takes 1.8 minutes per document compared to 12 minutes for manual processing, making it approximately 6.7 times faster.
What is the total annual cost difference between manual and automated document processing as shown in the article?
According to Table 1, manual processing costs $125,000 annually while automated ADR processing costs $48,000 annually, representing a difference of $77,000 per year.
How much global data is estimated to exist by the end of 2025?
According to IDC estimates cited in the article, global data will reach 175 zettabytes by the end of 2025, with much of it being unstructured and document-based.
Keep Reading
Explore more from Advanced document analysis

AI-Driven Document Processing: What Nobody’s Telling You (2026)
AI-driven document processing in 2026: Expose myths, reveal real ROI, and uncover hidden dangers. Discover how to transform chaos into clarity—act now or get left behind.

7 Truths Nobody Tells You About Document Processing Workflows
Document processing workflow decoded: Shatter myths, avoid hidden traps, and discover the 2026 playbook for reliable, AI-powered results. Get ahead or get left behind.

Document Processing Automation in 2026: Wins, Traps, and What’s Real
Discover insights about document processing automation

Document Workflow Automation in 2026: Hard Roi, Real Risks
Discover insights about document workflow automation

Are Document Processing Tools Making Us Smarter or Just Lazier?
Welcome to the world where document processing software tools are supposed to be your ticket out of paperwork hell—but often just hand you a different brand of

How Document Automation Is Rewriting the Rules (and Who Wins in 2026)
Tools for automating document management are disrupting workflows in 2026. Discover the hidden risks, real ROI, and bold strategies that experts won’t tell you.

Document Processing’s Dark Side: Are You Ready for the Real Fight?
It’s 2025, and the world is drowning in documents—paper, PDFs, scanned contracts, and endless digital forms. Every click, every upload, every missing version

Document Chaos Decoded: How Intelligent Recognition Is Rewriting the Rules
Intelligent document recognition is changing everything. Discover 7 raw truths, shocking stats, and expert hacks for turning document chaos into clarity—don’t fall behind.

Data Capture From Documents: What No One Tells You
Data capture from documents just changed forever. Discover 7 brutal truths, hidden wins, and how to actually get ahead—before your competitors do.