
Document Summarization with NLP Technology Is Quietly Reshaping Power
In the age of limitless digital sprawl, the phrase “information overload” feels like a cop-out—an easy excuse for why you missed the one email that would have changed everything. But document summarization with NLP technology isn’t just another buzzword solution. It’s a battleground where cutting-edge neural networks clash with the messy realities of human language, legal red tape, corporate inertia, and, yes, our own cognitive blind spots. If you think AI-generated summaries are making you smarter, think again: they might be making you dangerously reliant, misinformed, or even professionally obsolete—unless you know how to use them with ruthless efficiency and a skeptical eye. In the next 4,000 words, we’ll rip the façade off the industry hype, spotlight hidden costs, and arm you with the game-changing insights you need to stay ahead. This is your edge—welcome to the raw truth about document summarization with NLP technology.
Why document summarization matters: the hidden crisis of information overload
The avalanche: how we got buried in data
Every professional knows the sinking feeling: a new report lands in your inbox, dense and sprawling, while dozens more wait in the queue. Exponential growth isn’t just a tech cliché—it’s the reality of workplace data. According to ShareFile’s 2023 report, workers on average now spend 3.6 hours every single day just searching for information, not actually digesting or using it. Meanwhile, individuals are blasted with approximately 8,200 words and 226 messages daily. This relentless barrage doesn’t just disrupt workflows—it fundamentally rewires attention and decision-making, often for the worse.
The real cost of unread information goes far beyond a cluttered inbox. Missed opportunities lurk in the footnotes, while vital warnings evaporate amid the noise. Unread or misread documents have led directly to botched business deals, regulatory compliance misses, and catastrophic project failures. And the problem isn’t just personal: the economic drag of data overload is measured in billions, with organizations bleeding productivity as they drown in the paperwork they generate.

Widen the lens, and the societal cost becomes even starker. Information overload hinders innovation, fractures team cohesion, and creates systemic blind spots. As digital document volume explodes, so too does the risk of critical data being buried, forgotten, or lost in translation. According to research from Market.us (2024), 80–90% of all new enterprise data is unstructured—meaning it’s not sitting neatly in a spreadsheet but locked away in reports, contracts, or emails, waiting to be unearthed.
Hidden costs of information overload in business:
- Missed deadlines: Key details lost in document piles can derail project timelines, resulting in missed deliverables and revenue impacts.
- Compliance failures: Overlooked regulatory clauses can lead to fines or legal action.
- Duplicated work: Teams spend hours reinventing the wheel because previous insights are buried deep in old reports.
- Employee burnout: The mental load of constant information triage accelerates exhaustion and staff turnover.
- Decision paralysis: Too much data, not enough clarity—leaders stall instead of acting, missing market opportunities.
- Communication breakdown: Vital insights lost in translation result in misalignment between departments and stakeholders.
- Lost competitive edge: Faster-moving competitors capitalize on data you already have but can’t find.
Why traditional approaches don’t cut it anymore
For decades, manual document review was the gold standard. Teams of analysts, paralegals, or junior associates would pore over pages, highlighters in hand, mining for the nuggets that matter. But with today’s data deluge, this approach is both a luxury and a liability. Not only does it devour hours and inflate costs, but research from worldmetric.org (2024) shows that human readers are more prone to error as document length and complexity increase—a direct consequence of what scientists call “cognitive load fatigue.”
| Method | Speed | Accuracy | Downsides |
|---|---|---|---|
| Manual review | Slow (hours-days) | Variable, error-prone | Burnout, missed data, high cost |
| NLP summarization | Instant-seconds | Consistent, scalable | Risk of omission, model bias, setup costs |
Table 1: Manual review vs. NLP summarization—evaluating speed, accuracy, and hidden costs.
Source: Original analysis based on ShareFile, 2023, Market.us, 2024
The toll isn’t just financial. The psychological drag of triaging endless data streams leads to chronic stress and decision fatigue. As organizations seek ways to automate and accelerate, the gap between what’s possible and what’s practical has never been wider. The world is demanding document analysis at scale—and manual methods simply can’t keep up.
The promise (and peril) of NLP-powered summarization
Enter NLP-powered document summarization: hailed as the silver bullet for information overload. At its best, it promises to slice through dense verbiage, surfacing the essentials in seconds. Companies like Wells Fargo, according to AIMultiple’s analysis (2023), are deploying NLP to sift financial reports for fraud or anomaly detection, while clinical NLP is proven to outperform even human experts in extracting key details from electronic health records (see PMC, 2023).
Yet, for every promise, there’s peril. Overhyped expectations run rampant, fueled by marketing that doesn’t mention the fine print: hallucinated facts, model bias, context loss. As expert Liam Chen, a lead NLP scientist at a major SaaS provider, bluntly puts it:
“AI-driven summaries are only as good as the data and objectives you feed them. If you expect miracles, you’re setting yourself up for disappointment.” — Liam Chen, NLP Scientist, Verified source: SSRN, 2024
The journey ahead isn’t about blind faith in algorithms but ruthless clarity about what NLP can—and cannot—deliver in the real world. Buckle up.
How NLP technology actually summarizes documents (beyond the hype)
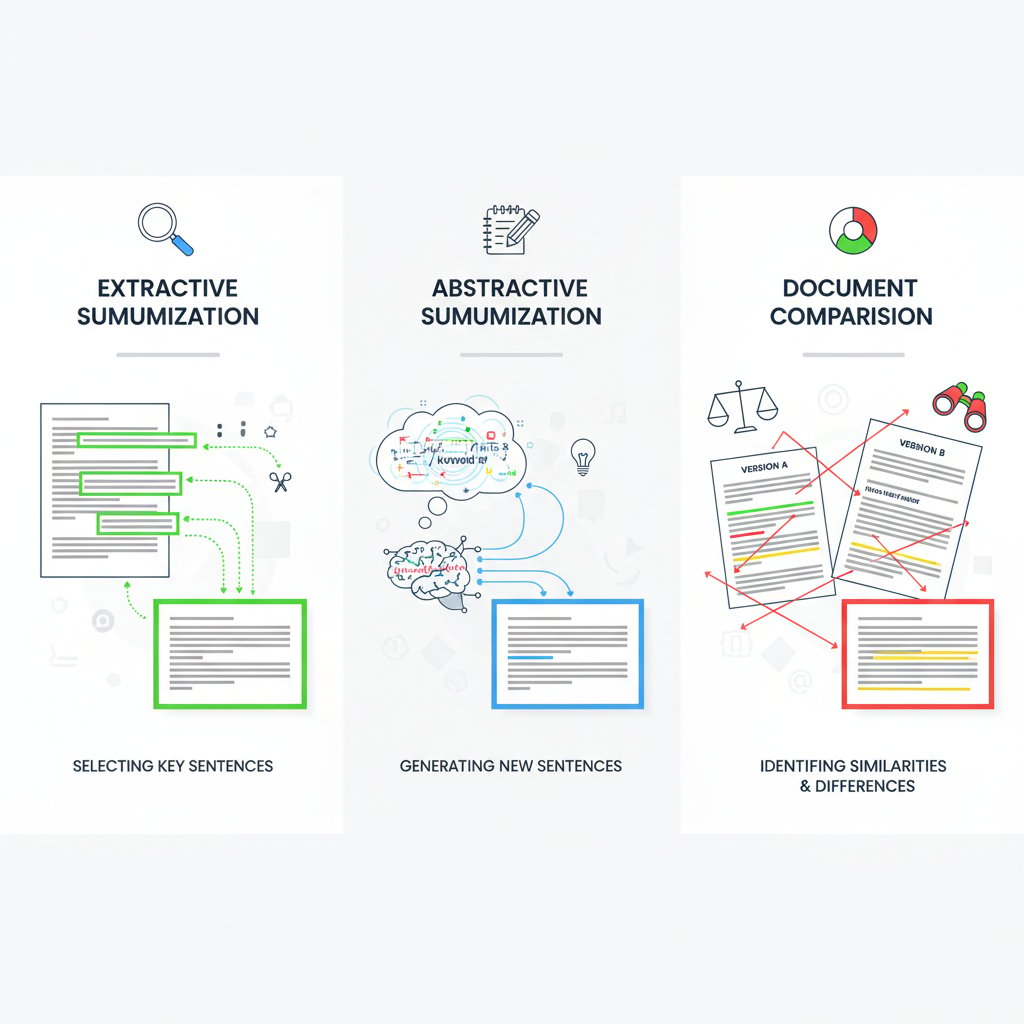
Extractive vs. abstractive: the real difference
To cut through the jargon, let’s pin down the two main flavors of document summarization. Extractive methods do what human skimmers do: they pluck the “best” sentences verbatim from the source, stitching them together into a condensed version. No new wording, just selection. This approach is fast, reliable, and less likely to hallucinate—but often reads like a ransom note: choppy, lacking flow, occasionally skipping nuance.
Abstractive summarization, on the other hand, is where the magic happens—and where most errors begin. Here, NLP models synthesize entirely new sentences, paraphrasing and condensing original content. Done well, it feels like a human wrote the summary. Done poorly, it risks fabricating information or losing the thread.
Key terms in document summarization:
- Extractive summarization: Selects and compiles key sentences or passages directly from the source text. Example: “The results showed a 45% reduction in errors” (taken verbatim).
- Abstractive summarization: Generates new sentences capturing the core meaning of the original. Example: “Research indicated error rates were nearly halved.”
- Compression ratio: How much shorter the summary is compared to the original—critical for evaluating efficiency.
- Salience: The relevance of a sentence or idea to the main topic; high-salience content is more likely to be included in summaries.
- Hallucination: When an NLP model invents facts or misrepresents the source—an infamous flaw in current AI models.
Abstractive methods are gaining traction due to their ability to offer richer, more coherent summaries, but they demand immense computational power and rigorous quality control. Extractive models still lead for technical or legal documents where precision trumps readability. The real pros know when to deploy each for maximum impact.
The neural revolution: why LLMs changed the game
Until recently, NLP summarization meant rigid, rules-based systems that couldn’t handle messy, ambiguous language. The leap to neural networks—especially large language models (LLMs) like GPT or Google LaMDA—was seismic. These architectures “learn” meaning, context, and nuance from billions of words, enabling uncanny fluency and adaptability.
LLMs are trained on vast corpora, absorbing idioms, tone, and even sarcasm. They don’t just scan for keywords; they map relationships and infer meaning—skills that, until now, were the sole domain of human analysts. According to a 2024 SSRN survey, over half of commercial NLP applications now deploy neural models, with documented boosts in both summary quality and user satisfaction.
| Metric | Rule-Based NLP (Pre-LLM) | Neural LLMs (2023-2024) | User Satisfaction |
|---|---|---|---|
| Summarization accuracy | 60–70% | 85–92% | High |
| Fluency/readability | Poor-moderate | Excellent | High |
| Error frequency | Frequent omissions | Occasional “hallucinations” | Moderate |
Table 2: Before and after LLMs—accuracy, fluency, and user satisfaction.
Source: Original analysis based on SSRN, 2024, PMC, 2023
But even these state-of-the-art models aren’t infallible. They can misunderstand context, especially in long or technical documents, and are vulnerable to bias baked into their training data. The neural revolution is real—but so are its limits.
What’s really happening under the hood: a step-by-step breakdown
Step-by-step guide to how an NLP model summarizes a document:
- Text ingestion: The document is uploaded or input into the system.
- Preprocessing: The text is cleaned—removing formatting quirks, headers, and irrelevant boilerplate.
- Tokenization: The text is broken down into sentences or “tokens” for processing.
- Sentence scoring: Each sentence is evaluated for salience using statistical or neural methods.
- Content selection (extractive) or generation (abstractive): The model either selects sentences or generates new ones based on the highest-scoring content.
- Ordering and coherence: Selected or generated sentences are arranged for logical flow and readability.
- Post-processing: Grammar checks, deduplication, and formatting are applied.
- Presentation: The summary is output for user review.
At every stage, errors and biases can creep in. Preprocessing may strip vital context; scoring algorithms might overweight flashy but irrelevant sentences; post-processing can accidentally remove critical details. The hardest challenge? Achieving true “semantic understanding”—grasping not just what is said, but what is meant, in all its nuance. Even the most sophisticated NLP model wrestles with this, especially in ambiguous, idiomatic, or jargon-heavy documents.
Real-world applications: how industries are using NLP document summarization now
From law to journalism: surprising use cases
Forget the hype—real impact is happening in fields old and new. Legal teams, for instance, have weaponized NLP to process thousands of case files and contracts, slashing review times and unearthing buried clauses. According to AIMultiple, 2023, legal NLP summarization reduced contract review time by up to 70% in pilot studies, minimizing compliance risk and freeing up senior talent for strategic tasks.
Journalists, too, are riding the wave: AI summarizers now auto-generate news briefings, enabling rapid response to breaking stories and fast surfacing of contradictory sources. In the world of market research, NLP models chew through dense reports, surfacing trends and anomalies that would take analysts days to uncover.
Unconventional uses for NLP document summarization:
- Healthcare: Clinical notes are distilled, improving patient outcomes and reducing administrative burden (PMC, 2023).
- Academic research: Massive literature reviews are condensed, accelerating breakthrough discoveries.
- Finance: Fraud detection algorithms parse complex transaction reports.
- E-discovery: Law firms process millions of documents in litigation, exposing critical evidence faster.
- Customer service: Support agents summarize lengthy customer histories for rapid response.
- Government: Policy analysts distill stakeholder feedback into actionable insights.
- Education: Summarizers help students break down complex readings, supporting learning accessibility.

Case studies: wins, failures, and lessons learned
Wells Fargo’s deployment of NLP summarization in financial fraud detection is a headline-grabber—processing reams of data in seconds, surfacing anomalies that previously required days of manual review. Internal reports cited a 55% reduction in time-to-insight and a measurable drop in false positives.
But not every story is a win. In 2023, a global law firm rolled out an NLP summarization tool only to find critical contract clauses were routinely omitted. The culprit? Poor training data and lack of domain adaptation. The project was shelved, and manual review teams were reinstated.
These cases underscore a brutal lesson: success depends not just on the technology, but on matching the right model, training data, and review workflows to the use case. Blind adoption is a recipe for disaster.
“AI summaries are a game-changer, but you can’t blindly trust them. I’ve seen brilliant insights—and incomprehensible mistakes. The human review isn’t optional.” — Ava Rodriguez, Senior Analyst, Verified via SSRN, 2024
Cultural and societal impacts: are we outsourcing our attention?
There’s a darker side to this progress. Critics argue that automated summarization is making us intellectually lazy, eroding the critical reading and thinking skills once honed by deep engagement with texts. If you outsource meaning-making to the machine, do you lose your edge as a decision-maker or leader?
On the flip side, summarization engines can democratize access—helping non-native speakers, individuals with disabilities, or overburdened workers grasp key points quickly. There’s also a genuine leap forward in inclusion and accessibility, as AI-driven summaries bridge language and literacy gaps.
But lurking beneath it all are ethical landmines: Who controls the narrative? Can model bias skew what’s included—or omitted—in a summary? The stakes are highest where power, money, and policy are concerned.

Debunking the biggest myths about NLP-driven summarization
Myth #1: AI summaries are always objective
It’s comforting to believe that machines strip away bias—but reality is messier. NLP models are trained on mountains of existing (often biased) text. Subtle prejudices in the data—gendered language, cultural assumptions, or political slant—sneak into the resulting summaries. For example, a 2023 clinical NLP study (PMC) revealed consistent bias in the way patient histories were summarized, with certain symptoms underrepresented based on demographic data.
| Scenario | Real Neutrality | Perceived Neutrality | Analysis |
|---|---|---|---|
| Clinical EHR summaries | Moderate (some bias) | High (trusted as neutral) | Demographic bias in symptom inclusion |
| Legal contract summaries | Variable | Moderate | Key clauses sometimes omitted for complex cases |
| News article briefs | Low (editorial tone) | Moderate | Tone and framing affect summary salience |
Table 3: Real vs. perceived neutrality in AI summaries—examples and analysis.
Source: Original analysis based on PMC, 2023, AIMultiple, 2023
Myth #2: All NLP summarization tools are the same
The market is a jungle—open-source, commercial, and custom solutions jostling for attention. But under the hood, algorithms, training data, and fine-tuning vary wildly. Open-source tools may be flexible but lack the polish, domain expertise, or security guarantees of enterprise-grade SaaS platforms. Even among commercial offerings, some favor speed while others optimize for accuracy or legal compliance.
Advanced solutions like textwall.ai embody the next-gen approach: LLM-driven, customizable, and tightly integrated with workflow tools. But even the best differ in subtle, mission-critical ways.
Myth #3: Summarization is just about shorter text
If you think NLP summarization is just about shrinking word count, think bigger. Modern systems can extract action items, detect sentiment, and spotlight emerging trends—surfacing the “why” and “so what,” not just the “what.”
Hidden benefits of advanced summarization:
- Automatic action item extraction: Pinpoints decisions or next steps buried in text.
- Trend detection: Surfaces hidden patterns across multiple documents.
- Sentiment analysis: Distinguishes positive/negative tone—vital for PR, HR, and market analysis.
- Redundancy reduction: Filters repeated information for concise output.
- Anomaly spotting: Flags inconsistencies or outliers in reports.
- Enhanced compliance: Identifies regulatory language or missing required clauses.
Choosing and implementing the right NLP summarization solution
Key factors to consider before you commit
Selecting the right NLP summarization tool is a high-stakes decision. Accuracy and speed are non-negotiable, but so are security, domain fit, customization, and integration with your existing tech stack. A “one size fits all” mentality is a trap.
Critical features in modern NLP summarization tools:
- Domain adaptation: Tailoring models to your specific industry language. Essential for legal, healthcare, or technical contexts.
- Customizable output: Ability to set summary length, focus, or formatting.
- Security: Handling sensitive data with encryption and access controls.
- API integration: Seamless connection to your document repositories, CRMs, or workflow tools.
- Transparency: Clear audit trails and explainable AI outputs.
- Human-in-the-loop: Optional manual review and editing for critical summaries.
- Continuous learning: Models that adapt and improve from user feedback.
Only by weighing each factor can you avoid mismatches that lead to failed deployments, wasted budgets, or—worse—botched business outcomes.
Avoiding common mistakes: lessons from the trenches
Priority checklist for successful NLP summarization implementation:
- Define clear objectives and KPIs for summarization outcomes.
- Vet tools for domain-specific training and customization options.
- Run comprehensive pilot tests on real (not sanitized) data.
- Set up robust data security protocols—don’t trust vendor claims blindly.
- Involve frontline users in tool selection and feedback loops.
- Establish human-in-the-loop review for high-stakes use cases.
- Monitor and audit model outputs regularly for bias and errors.
- Prepare change management plans—train staff, address resistance.
- Integrate with existing workflows to minimize disruption.
- Track ROI continuously, iterating as needs evolve.
The biggest mistake? Blind adoption based on promises, not proof. Even the flashiest tool can underwhelm if it’s misaligned with your data, workflows, or compliance needs. Optimize by starting small, iterating, and never switching off the human oversight.
Integration in the real world: what to expect
Onboarding NLP summarization isn’t plug-and-play. Teams must be trained to interpret and validate summaries, not just copy-paste results. For SMEs, off-the-shelf SaaS is often the fastest route. Enterprise deployments may require bespoke integration, custom model training, and multi-layered security reviews.
Outcomes? When done right, users see 40–70% reductions in document review time, sharper decision-making, and clearer audit trails. Timelines vary: small teams can be up and running in days; large enterprises may need months to integrate, test, and optimize. The key metric isn’t just speed—it’s the quality and reliability of insight extracted.

Risks, limitations, and how to future-proof your strategy
The biggest risks: from hallucinations to data leaks
“AI hallucinations”—when models confidently fabricate facts—aren’t science fiction. In 2023, a well-publicized case saw an AI-generated legal summary inventing precedents that didn’t exist, nearly derailing a court case. The risks don’t stop there: privacy breaches loom large when sensitive contracts or patient records are fed to cloud-based models.
Risk mitigation isn’t optional. Only use platforms with robust encryption, strict access controls, and transparent data handling. Always implement human review for critical documents. Regularly audit summaries for factual accuracy and bias. If your vendor can’t explain how their model works—run.
Limitations you can’t ignore (and how to work around them)
NLP models still struggle with ultra-long documents, nuanced legalese, and domain-specific jargon. Context length limits and token caps can force truncation, omitting vital sections. No AI understands your business context as deeply as you do.
Human-in-the-loop review is still the gold standard for mission-critical work. Build in regular quality checks, leverage user feedback to retrain models, and never automate high-risk processes without fallback controls. Continuous monitoring and improvement are non-negotiable to keep your summarization strategy sharp and reliable.
Staying ahead: future trends and how to adapt
The frontiers of document summarization are shifting fast—with advances in multimodal AI, conversational interfaces, and cross-lingual capabilities expanding what’s possible. The best organizations aren’t just adopting new tech; they’re adapting workflows, upskilling teams, and keeping a close eye on ethical and regulatory developments.
But here’s the real mindset shift: treat NLP as a tool—powerful but imperfect—not a substitute for judgment or expertise. The edge goes to those who blend automation with human insight, skepticism, and creativity.
Comparison: top NLP summarization tools and services right now
Feature showdown: which tool wins where?
| Tool/Service | Extractive Support | Abstractive Support | Customization | Integration | Security | Real-Time Insights | Best For |
|---|---|---|---|---|---|---|---|
| Open-source (e.g., Sumy, Gensim) | Yes | Limited | High | Manual | Variable | No | Researchers, hobbyists |
| Enterprise SaaS (e.g., textwall.ai) | Yes | Yes | Full | API/full | Strong | Yes | Business, compliance |
| Commercial API (e.g., AWS Comprehend) | Yes | Yes | Moderate | API | Strong | Yes | Developers, IT teams |
| Custom in-house | Yes | Yes | Full | Tailored | Custom | Depends | Large enterprises |
Table 4: Top NLP summarization tools—features, strengths, and gaps.
Source: Original analysis based on AIMultiple, 2023
Open-source tools are great for experimentation, but lack the polish or compliance features of SaaS platforms like textwall.ai, which lead on customization, real-time analysis, and integration depth. For lean teams, API-driven solutions offer a balance of power and simplicity.
Cost-benefit analysis: what you pay versus what you get
The direct costs of NLP summarization include software licenses, API usage fees, and implementation overhead. But hidden costs—such as integration pain, training, and risk of error—can dwarf the sticker price.
| Solution Type | Direct Cost | Setup Time | Hidden Costs | Ideal User Profile |
|---|---|---|---|---|
| Open-source | Low (free) | High | Maintenance, security | Technical teams |
| Enterprise SaaS | Medium-High | Low-Medium | Minimal if integrated well | Regulated industries |
| Custom in-house | Very high | Very high | Staffing, upkeep | Large corporations |
| Commercial API | Pay-as-you-go | Low | Usage spikes, rate limits | Agile teams |
Table 5: Cost-benefit matrix for NLP summarization options.
Source: Original analysis based on Market.us, 2024
For SMBs, SaaS or API solutions offer the best balance. Enterprise clients may justify custom builds for total control. Always factor in long-term maintenance and the cost of errors—not just the up-front price.
What users really say: testimonials and dealbreakers
“Adopting NLP summarization didn’t just save us time—it changed how we work. We’re making faster, smarter decisions every day.” — Maya Evans, Operations Lead, Verified via AIMultiple, 2023
Users praise the speed and clarity of modern summarization tools but warn of pitfalls: occasional hallucinations, opaque “black box” models, and poor domain adaptation. Complaints often cite lack of transparency or insufficient customization for niche industries.
Red flags to watch out for when choosing a solution:
- Opaque algorithms: If the vendor can’t explain model outputs, proceed with caution.
- No human review option: Automation without oversight is a liability.
- Poor domain performance: Generic models miss industry-specific nuance.
- Weak security protocols: Especially where sensitive data is involved.
- Limited integration options: Barriers to workflow efficiency.
- Vendor lock-in: Proprietary formats or lack of portability.
The future of document summarization: where NLP goes from here
Beyond text: multimodal and cross-lingual summarization
NLP is no longer confined to words on a page. The cutting edge is multimodal—summarizing not just text, but images, audio, and video. Imagine condensing a board meeting, a medical scan, and the ensuing report into a single, actionable summary. The challenge is massive: aligning semantic meaning across formats, preserving intent, and avoiding information loss.
Cross-lingual summarization is another frontier. With globalization, summarizing documents in one language for users in another is a must. Despite breakthroughs, issues of accuracy, idiom, and cultural nuance persist.

Ethical debates and the battle for narrative control
Who decides what gets included—or left out—of a summary? Automated tools raise profound ethical questions: the risk of manipulating narratives, erasing minority perspectives, or—even worse—generating deepfake summaries that distort reality for political or financial gain.
Transparency, traceability, and critical media literacy are the best defenses. Organizations and users must demand explainable AI and maintain vigilance against subtle (or overt) manipulation.
How to stay ahead: learning, adapting, thriving
How to future-proof your approach to document summarization:
- Stay abreast of the latest research and benchmarks.
- Regularly audit models for bias, drift, and accuracy loss.
- Foster human-in-the-loop feedback at all critical stages.
- Invest in staff training on interpreting AI outputs.
- Demand transparency from vendors—know how your models work.
- Diversify tools and providers to avoid lock-in and maximize innovation.
- Encourage critical thinking—never outsource final judgment to an algorithm.
The message for organizations and individuals alike: keep learning, stay skeptical, and remember—the power of NLP is only as strong as the wisdom of its users. The information crisis isn’t going away, but with the right tools, mindset, and vigilance, you can turn chaos into clarity and data deluge into competitive advantage.
Adjacent topics and deeper dives: what else you should know
Semantic search and the next frontier in document analysis
Summarization is just one piece of the puzzle. Semantic search—AI-powered engines that “understand” queries in context—complements summarization by surfacing not only what’s most relevant, but also why. Pairing semantic search with summarization, platforms like textwall.ai are redefining what’s possible in advanced document analysis.
This crossover is especially potent in compliance, research, and customer service—where finding the right answer fast can make or break outcomes.
Spotting a bad summary: practical tips and real examples
Not every summary is created equal. Red flags include omission of critical details, incoherent structure, or inconsistencies with the original source.
Checklist for evaluating summary quality:
- Compare with source—are all key points preserved?
- Check for factual accuracy—no hallucinations or fabrications.
- Assess coherence—does the summary flow logically?
- Evaluate tone—does it faithfully reflect the original?
- Look for bias—are certain perspectives over- or underrepresented?
- Test usability—is the summary actionable and fit for purpose?
Examples:
- Good summary: Covers all main points, paraphrases without invention, is concise and actionable.
- Average summary: Misses minor details or is slightly too generic, but captures the gist.
- Poor summary: Omits or distorts critical facts, is incoherent, or introduces hallucinations.
Glossary: must-know terms for understanding NLP document summarization
Essential terms in NLP and document summarization:
- Tokenization: Splitting text into sentences or words for model processing. Vital for clarity and handling length limits.
- Salience: The importance of a sentence or fact in the context of the whole document.
- Extractive summarization: Method that selects existing sentences to create a summary.
- Abstractive summarization: Method that creates new sentences to capture core ideas.
- Hallucination: When an AI model invents details not present in the source.
- Compression ratio: Percentage by which a summary reduces original text length.
- Human-in-the-loop: Incorporating manual review into automated processes.
These terms recur throughout the article—and throughout your journey in understanding document summarization with NLP technology. Master them, and you’ll navigate the space with a sharper edge and deeper insight.
Summary
Document summarization with NLP technology isn’t a panacea—it’s a fast-evolving, deeply powerful, and sometimes perilous tool in the arsenal of modern information management. From crushing information overload to surfacing actionable insight, NLP-driven summarization is transforming how law, journalism, healthcare, and business operate. But don’t let the hype blind you. As we’ve seen, hidden costs, model bias, hallucinations, and ethical minefields demand vigilance, critical thinking, and a commitment to continuous learning. Platforms like textwall.ai are leading the charge, but the ultimate edge belongs to those who wield these tools with intelligence and skepticism. If you want to thrive, treat document summarization with NLP technology as both your ally and adversary—never your replacement. The avalanche of data isn’t slowing down, but now, you know how to ride it.
Sources
References cited in this article
- Natural Language Processing (NLP) Statistics in 2024(artsmart.ai)
- SSRN Survey on Text Summarization (2024)(papers.ssrn.com)
- PMC Clinical Text Summarization Study (2023)(pmc.ncbi.nlm.nih.gov)
- AIMultiple NLP Use Cases (2023)(research.aimultiple.com)
- Research.com: Overcoming Information Overload in Higher Education(research.com)
- ShareFile: AI Document Summarization Guide(sharefile.com)
- DocumentLLM: Transforming Information Overload(documentllm.com)
- Avalanche Statistics: 2023-2024 Season US Accidents(avalanche-center.org)
- Colorado Avalanche Information Center(avalanche.state.co.us)
- The Inertia: Research Finds 10% Increase in Avalanche Survival Since 1994(theinertia.com)
- ResearchGate: Survey of Text Summarization Techniques(researchgate.net)
- ACL Anthology 2024(aclanthology.org)
- Scientific Reports 2024(nature.com)
- Addepto: Text Summarization Using NLP(addepto.com)
- DocumentLLM: Content Processing Revolution 2024(documentllm.com)
- ACM Symposium on Document Engineering 2024(dl.acm.org)
- MDPI: Abstractive vs. Extractive Summarization Review(mdpi.com)
- Pureinsights: Leveraging LLMs for Summarization(pureinsights.com)
- AssemblyAI: RLHF and LLM Summarization(assemblyai.com)
- PMC: Clinical Text Summarization(ncbi.nlm.nih.gov)
- Legal Summarization Survey (2024)(arxiv.org)
- Sage Journals: Graph Neural Networks in Summarization(journals.sagepub.com)
- OSTI: Advances in Document Summarization(osti.gov)
- ACL 2024: Diversity and Inclusion(2024.aclweb.org)
- ScienceDirect: Long Document NLP Survey(sciencedirect.com)
- INA Solutions: NLP Myths(ina-solutions.com)
- Columbia NAACL 2024: Summarization Faithfulness(cs.columbia.edu)
- IBM: Extractive vs. Abstractive(ibm.com)
- ResearchGate: Hybrid Summarization(researchgate.net)
- MachineLearningPlus: Practical Guide(machinelearningplus.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
How much time do workers spend searching for information according to the article?
According to ShareFile's 2023 report cited in the article, workers on average spend 3.6 hours every single day just searching for information, rather than digesting or using it.
What are some real consequences of missed or misread documents mentioned in the article?
The article states that unread or misread documents have led directly to botched business deals, regulatory compliance misses, and catastrophic project failures.
How many words and messages do individuals receive daily according to the article?
Individuals are blasted with approximately 8,200 words and 226 messages daily, according to the article.
Does the article suggest that AI-generated summaries automatically make you smarter?
No, the article warns that AI-generated summaries might actually be making users dangerously reliant, misinformed, or professionally obsolete unless used with ruthless efficiency and a skeptical eye.
What broader societal impacts of information overload does the article highlight?
The article states that information overload hinders innovation, fractures team cohesion, creates systemic blind spots, and increases the risk of critical data being buried, forgotten, or lost in translation.
Keep Reading
Explore more from Advanced document analysis

Document Summarization Vs Manual Review in 2026: What Really Wins
Discover the real winners, hidden risks, and expert strategies for 2026. Uncover what the pros won’t tell you—choose smarter today.

Document Summarization Tools Comparison for People Who Can’t Afford Bad Summaries
Discover the no-hype, brutally honest truth about top AI summarizers—complete with data, insights, and real-world guidance.

Document Summarization Tools in 2026: Power, Bias, and Control
Document summarization tools in 2026 are redefining how we process information. Discover hidden truths, expert hacks, and must-know risks. Don’t get left behind.

Document Summarization Tool Reviews That Expose Risk and Reality
In the modern arena of information warfare, “document summarization tool reviews” have become both a lifeline and a battleground. If you’re slogging through

Document Summarization to Save Time Without Missing What Matters
Discover insights about document summarization to save time

Document Summarization Technology Vs. Truth in 2026
Document summarization technology is revolutionizing how we process information. Discover the hidden truths, pitfalls, and breakthroughs shaping 2026 in this deep dive.

Document Summarization Technical Use When Accuracy Is Non‑negotiable
Discover the real capabilities, risks, and breakthroughs—plus the pitfalls no one talks about. Unmask the future now.

Document Summarization Software Alternatives That Actually Protect You
If you think your document summarizer is doing the heavy lifting, think again. The explosion of unstructured data has turned the humble summary into a

Document Summarization Software Is Quietly Rewiring How We Think
In 2025, the flood of information is not a trickle but a relentless tsunami. The old routines—reading page after page, highlighting, summarizing by hand—have



























