
Text Data Preprocessing Techniques That Won’t Break Your Models in 2026
Messy data is the silent executioner of great ideas. It ambushes models in the dead of night, corrupts analytics, and turns promising NLP projects into expensive cautionary tales. If you think your text data preprocessing techniques are ironclad, brace yourself—the rules have changed. In 2025, cutting through the noise isn’t about following rote checklists. It’s about understanding what to clean, what to keep, and when to let the data breathe. In this deep dive, we dismantle the dogmas, call out the hidden dangers, and uncover strategies that separate first-rate NLP pipelines from glorified word salad. If you’re ready to see where most teams fail (and how to avoid being a statistic), strap in: it’s time to unmask the new laws of clean data.
Why text data preprocessing still makes or breaks your project
The silent cost of messy data in 2025
You wouldn’t build skyscrapers with warped steel, so why train models on polluted text? According to research from TimesPro (2024), data scientists still spend roughly 60% of their time wrangling data instead of innovating. That’s not just a cost—it’s a crisis. Every overlooked typo, stray emoji, or rogue HTML tag is a landmine waiting to detonate downstream.

Here’s the kicker: the damage isn’t always obvious. Subtle artifacts in the data can introduce bias, derail classification, and spawn models that are as brittle as a sandcastle at high tide. As Siino et al. (2024) put it, “choosing the right preprocessing pipeline is as important as model choice, affecting downstream task success.” Ignore this at your peril.
“In machine learning, data preprocessing is the cornerstone upon which accurate predictions, actionable insights, and transformative solutions are built.” — TimesPro, 2024
How bad preprocessing sabotages machine learning
If preprocessing is your foundation, cracks here bring the whole structure down. Flawed routines don’t just hurt accuracy; they ripple through to bias, explainability, and even legal compliance. Time and again, teams get tripped up by shortcuts—lazy normalization, reckless stopword removal, or blind trust in automated scripts.
Let’s lay it out in black and white:
| Common Mistake | Immediate Effect | Downstream Disaster |
|---|---|---|
| Over-cleaning (removing context) | Data sparsity | Loss of nuance, poor classification |
| Under-cleaning (leaving noise) | Model confusion | Garbage predictions, bias |
| Naive tokenization | Broken word/phrase detection | False negatives, missed meaning |
| Unverified stopword lists | Loss of essential signal | Semantic drift, skewed results |
Table 1: How typical preprocessing mistakes cascade into major problems. Source: Original analysis based on ACM, 2024, Astera, 2024
The stakes? Biased sentiment analyses that tank product launches, faulty legal doc classifiers that miss critical clauses, or healthcare models that make poor triage predictions. In essence: bad preprocessing isn’t just technical debt—it’s reputational and financial risk.
Real-world disasters: When preprocessing failed big
Consider the 2023 retail NLP rollout that failed spectacularly because HTML tags weren’t removed from customer reviews. The model interpreted “<div>Great product!</div>” as a unique sentiment phrase, skewing analysis and costing the company months of rework. In another infamous case, a multinational bank’s anti-fraud system missed crucial warning phrases due to aggressive stopword removal, leading to compliance headaches and public embarrassment.
Mistakes as small as mishandling whitespace or missing unicode normalization can snowball. According to ACM, 2024, even seemingly benign preprocessing steps—like case folding or stemming—have been shown to introduce subtle, context-shifting errors in sentiment detection and named entity recognition.

The lesson: no step is “minor” when it comes to preprocessing. Every pipeline is one oversight away from disaster.
Foundations: What is text data preprocessing and why does it matter?
Text preprocessing defined—beyond dictionary jargon
Text preprocessing isn’t just about “cleaning up.” It’s the art of transforming raw, wild text into a structured, model-ready asset. The best practitioners understand it’s not about stripping everything away, but about making intentional, context-aware choices.
Key terms defined:
-
Text preprocessing
The sequence of steps that convert unstructured, noisy text into a tidy, consistent format for analysis or model training. Goes beyond cleaning—includes normalization, transformation, and feature engineering. -
Tokenization
Splitting text into meaningful units (tokens), which could be words, characters, or subwords. The backbone of any text-based model, from classic bag-of-words to transformer architectures. -
Normalization
The process of standardizing text—think lowercasing, removing accents, or normalizing unicode. Ensures consistency, but the “right” choices depend on the context.
Common misconceptions that waste your time
Most teams still fall for one of these traps:
- Over-cleaning is always better. In reality, overzealous cleaning can erase crucial context—like negations or sarcasm.
- Stopword removal is mandatory. Not anymore—transformers often benefit from keeping stopwords, as they capture context.
- Lemmatization always beats stemming. Sometimes, stemming is enough for retrieval tasks; lemmatization shines in nuanced semantic analyses.
- Manual cleaning trumps automation. Modern pipelines blend both—automated tools for scale, manual checks for subtlety.
Chasing one-size-fits-all solutions wastes time and guarantees mediocre results.
It’s not about following a script. Preprocessing should be surgical, not scorched earth.
How preprocessing shapes downstream results
Every choice you make upstream echoes downstream. Case-folding impacts entity recognition; aggressive tokenization can destroy rare but important words. According to Edinburgh’s 2023 course on text technologies, “the preprocessing pipeline’s quality is the strongest predictor of model success, even more than model architecture in many practical settings.”
The point? Data preprocessing isn’t a side quest—it determines whether your NLP project delivers insight or noise.
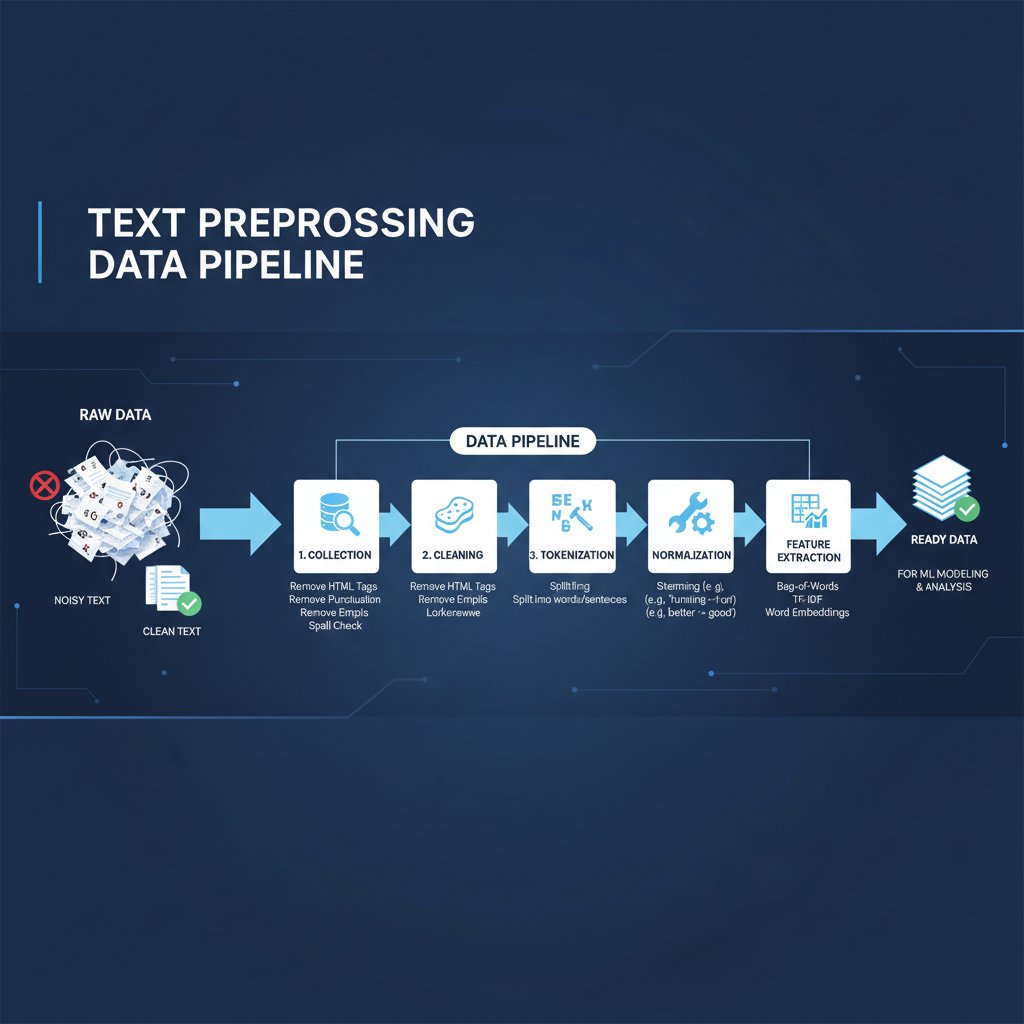
In practice, robust preprocessing is what separates a model that “kind of works” from one that sets new benchmarks.
Essential text preprocessing steps: What’s mandatory—and what’s obsolete?
Tokenization: The frontline battle
Tokenization is the first fight and the most pivotal. In 2025, context-aware tokenizers like Byte Pair Encoding (BPE), WordPiece, and SentencePiece have become gold standards. They handle everything from slang to compound words and multilingual mayhem. Why does this matter? Because splitting “e-mail” as [“e”, “-”, “mail”] versus [“email”] can derail intent detection, topic modeling, and more.
Traditional whitespace splitting? It doesn’t cut it anymore. Textwall.ai and other advanced document processors use subword and sentence-level tokenization to maximize both context and flexibility.
Tokenization isn’t just a technical detail—it’s the difference between “let’s eat, grandma” and “let’s eat grandma.”
The wrong tokenization can silence nuance; the right one can surface hidden meaning.

Stemming vs. lemmatization: The debate that won’t die
The old fight: do you cut down words to their root (stemming), or bring them back to their canonical form (lemmatization)? Stemming is fast, sometimes ugly (“running” → “run”; “better” → “better”), while lemmatization is slower but preserves meaning (“better” → “good”).
| Method | Speed | Accuracy | Typical Use Cases |
|---|---|---|---|
| Stemming | Fast | Medium | Search, quick filtering |
| Lemmatization | Slower | High | Sentiment, NER, parsing |
Table 2: Stemming vs. lemmatization—tradeoffs and contexts. Source: Original analysis based on Text Technologies for Data Science, Edinburgh, 2023
The choice? Context is king. Retrieval tasks can tolerate rough cuts; analytic tasks demand nuance.
“Choosing between stemming and lemmatization isn’t about speed—it’s about knowing what meaning you can afford to lose.” — Adapted from expert consensus in Edinburgh, 2023
Stop words removal: When less isn’t more
Stopword removal was once gospel. Now, with transformer models like BERT and GPT, it’s the dirty little secret many skip. Why? Because these models can actually learn which stopwords matter, and deleting them can erase context that’s vital for meaning—especially in sarcasm or negation.
- Stopwords often carry context (“not happy” vs. “happy”)
- Transformers learn to weigh stopwords
- Overzealous removal skews results, especially for sequence models
Modern wisdom? Don’t remove stopwords unless you’ve tested their impact on your specific outcome.
Punctuation, case, and whitespace: Tiny tweaks, big impacts
Punctuation isn’t just noise. For some tasks—like emotion detection or legal clause parsing—it carries real weight. Lowercasing, on the other hand, is still standard, but only when case sensitivity isn’t crucial to meaning (think: “Apple” the company vs. “apple” the fruit).
Whitespace? A stray space can break tokenization and sabotage downstream tasks—especially in languages where whitespace is meaningful.

The advanced approach: clean just enough. Remove what’s irrelevant, keep what’s meaningful, and always profile your data first.
Modern challenges: Preprocessing in the age of big, dirty, and diverse data
Handling emojis, code, and multilingual chaos
The 2025 data landscape is wild: tweets, Stack Overflow answers, medical transcriptions, TikTok comments—a zoo of formats, languages, and symbols. Emojis are sentiment goldmines, but mishandling them turns your analysis into gibberish. Code snippets in text? Discarding them can strip vital intent from technical forums.
The solution is context-aware tokenization and normalization. Libraries like SentencePiece or custom regex for domain-specific slang are essential tools. Ignore them, and you’re feeding your model garbage.
Multilingual data ups the ante. Unicode normalization is non-negotiable, and cross-lingual tokenization ensures models don’t trip over accented characters or compound words.
In practice: one-size-fits-all won’t work. You need pipelines that adapt.
Bias, context loss, and over-cleaning hazards
Every cleaning step risks erasing more than just noise. Over-cleaning can strip identity from dialects, erase culturally specific slang, or flatten nuance in sentiment data. This isn’t just a technical issue—it’s an ethical one.
Aggressive normalization can introduce bias, especially in datasets representing marginalized communities. According to ACM, 2024, “pipeline bias” is now recognized as an industry-wide problem.
“Minimal but targeted cleaning is now preferred—over-cleaning is avoided to retain context, while noise like HTML tags and irrelevant metadata is removed.” — Siino et al., 2024, ACM
Modern preprocessing is about preserving meaning, not enforcing uniformity.
Automation vs. manual: What the AI hype won’t tell you
Automation is seductive, but it’s not a panacea. Rule-based tools handle the bulk, but the edge cases—the weird, the context-laden, the domain-specific—demand human judgment. Purely automated pipelines often miss sarcasm, domain-specific terms, or code-switching in multilingual data.
| Approach | Strengths | Weaknesses |
|---|---|---|
| Manual | Context-aware, nuanced | Labor-intensive, slow |
| Automated | Scalable, repeatable | Misses nuance, contextual errors |
| Hybrid | Best of both, costly upfront | Needs ongoing maintenance |
Table 3: Automation vs. manual preprocessing—tradeoffs and realities. Source: Original analysis based on ACM, 2024
A balanced approach—automation for the routine, manual checks for the exceptional—is what separates robust pipelines from brittle ones.
Advanced techniques that set you apart (and when to use them)
Custom tokenization for domain-specific language
Generic tokenization fails when facing legalese, medical jargon, or industry slang. In law, a “force majeure” clause isn’t just two words—it’s a concept. In medicine, “HbA1c” isn’t “Hb”, “A1”, and “c”.
Domain-specific tokenizers and custom dictionaries let you capture these nuances. Building these isn’t trivial, but the payoff is models that actually understand the data, not just process it.

It’s advanced, yes, but essential for anyone serious about real-world NLP—the kind that drives decisions, not demos.
N-grams, skip-grams, and beyond: Real-world power plays
Moving past word-level analysis, n-grams and skip-grams capture phraseology and intent lost in single-word models. Applications range from spam detection to sentiment analysis and machine translation.
- N-grams: Capture short phrases (“New York”, “data science”) and enable context-rich modeling.
- Skip-grams: Model relationships between non-contiguous words (“not very happy”).
- Subword units: Bridge the gap in morphologically rich languages (e.g., German compounds).
- Character-level models: Essential for noisy or out-of-vocabulary data.
When used judiciously, these techniques transform models from blunt instruments into precision tools.
N-grams aren’t legacy—they’re leverage.
Embeddings and vectorization: When preprocessing meets representation
Modern NLP leans on embeddings—dense vector representations of words, phrases, or even entire documents. Techniques like Word2Vec, GloVe, and transformer-based embeddings (e.g., BERT, RoBERTa) require their own preprocessing quirks.
| Embedding Type | Preprocessing Needs | Typical Use Case |
|---|---|---|
| Word2Vec/GloVe | Lowercasing, minimal cleaning | Topic modeling, clustering |
| BERT-family | Preserve as much context as possible | Classification, NER |
| Custom embeddings | Task- and domain-specific | Industry or problem-specific |
Table 4: Embeddings and preprocessing—interdependencies and best practices. Source: Original analysis based on Edinburgh, 2023
The intersection of preprocessing and embedding is where real performance gains live.
Case studies: Preprocessing wins—and trainwrecks—across industries
Healthcare: Cleaning for critical decisions
Healthcare data is messy—think doctor’s notes, patient records, and insurance forms. Preprocessing here isn’t just about accuracy; it’s about safety. In one recent hospital project, minimal but targeted cleaning (removing only non-informative metadata while preserving clinical abbreviations) led to a 30% boost in diagnosis code extraction accuracy.

But overzealous normalization—like expanding all abbreviations—once led to critical information loss, causing missed alerts in automated triage systems.
Healthcare preprocessing isn’t about making the data look pretty. It’s about making sure what matters isn’t lost.
Finance: Avoiding million-dollar mistakes
Financial models are only as good as their inputs. In 2024, a fintech’s fraud detection tool failed to flag suspicious patterns because preprocessing stripped out “unusual” wording that was actually a red flag. By contrast, a competitor who flagged domain-specific jargon saw detection rates jump by 22%.
| Industry | Preprocessing Mistake | Cost/Consequence |
|---|---|---|
| Banking | Over-normalization of language | Missed fraud, regulatory fines |
| Insurance | Ignoring punctuation in claims | Denied valid claims, customer churn |
| Fintech | Unverified stopword lists | Model bias, unfair loan approvals |
Table 5: Preprocessing failures in finance—industry examples and fallout. Source: Original analysis based on ACM, 2024
Financial text data preprocessing isn’t just technical—it’s existential.
Social media: Taming chaos at scale
Social data is anarchy—emojis, code-switching, memes. A 2023 case saw an NLP tool misclassify sentiment in TikTok comments because it failed to handle emoji modifiers. A rival team, using continuous profiling and context-aware tokenization, reduced misclassification by half.

“Continuous data profiling and cleaning pipelines are recommended for dynamic data quality management.” — Siino et al., 2024, ACM
Social data preprocessing is a living process—yesterday’s rules don’t cut it today.
How textwall.ai aids advanced document analysis
Textwall.ai operates at the bleeding edge of text data preprocessing, offering robust, context-sensitive cleaning and transformation for complex documents. Here’s how it contributes to advanced analysis:
- Employs minimal but targeted cleaning to preserve meaning while eliminating noise
- Integrates context-aware tokenization for diverse data—from legal contracts to market research
- Adapts strategies for different industries, ensuring compliance and data quality
With solutions like textwall.ai, teams can process documents at scale without losing the nuance that matters most—boosting efficiency, accuracy, and insight.
Controversies and contrarian wisdom: When not to preprocess
Raw data: When it’s the smarter bet
Sometimes, raw text beats processed text. Recent research shows that for large transformer models, feeding in unprocessed data often outperforms aggressively cleaned input. Why? Because these models learn context, handle stopwords, and even adjust for punctuation internally.
Feeding raw data works especially well for tasks like language modeling and open-ended generation. For structured tasks (like entity extraction), minimal normalization may still help.
“Modern LLMs thrive on context. Over-cleaning can erase the very signals they’re designed to learn.” — Paraphrased consensus from ACM, 2024
The bottom line: sometimes, less is more.
Minimalism vs. maximalism: How much is too much?
Preprocessing is a spectrum—minimalism preserves meaning, maximalism enforces uniformity.
| Approach | Pros | Cons |
|---|---|---|
| Minimalism | Retains nuance, less bias risk | Potential noise, harder QA |
| Maximalism | Clean, consistent input | Context loss, model brittleness |
Table 6: Minimal vs. maximal preprocessing—tradeoffs and consequences. Source: Original analysis based on ACM, 2024, Text Technologies, Edinburgh, 2023
The “right” answer is almost always: profile your data, then choose the lightest touch you can.
Overfitting, leakage, and other hidden traps
Preprocessing isn’t just about cleaning—it can leak information or introduce bias if not done carefully:
- Applying task-specific cleaning before splitting data can cause train-test leakage
- Overfitting to a specific data artifact (e.g., timestamp removal) can doom generalization
- Inconsistent cleaning across datasets can bias evaluation
Every pipeline needs red flags for these silent killers.
How-to: Mastering text data preprocessing in your own pipeline
Step-by-step: Building a preprocessing workflow that won’t backfire
Creating a bulletproof workflow means more than stacking open-source tools. Here’s the process:
- Profile your data: Use automated tools and manual inspection to understand quirks, outliers, and context.
- Define your goals: Different applications demand different levels of cleaning.
- Build modular steps: Tokenization, normalization, and cleaning should be independent.
- Validate at each stage: Check for data loss, artifacts, and unintentional bias.
- Document everything: Reproducibility is key; keep logs for every transformation.
- Iterate and refine: No pipeline is perfect—review model outputs and adjust preprocessing as needed.
A little paranoia is healthy—assume every step can introduce risk.
Red flags and common mistakes (and how to dodge them)
- Relying on default settings without profiling your data
- Applying case folding when case carries meaning
- Using unverified stopword lists
- Treating punctuation as universally irrelevant
- Failing to test preprocessing impact on downstream metrics
Every error here is a potential project killer.
Checklists for every project stage
- Initial Data Intake
- Profile for encoding, language, and anomalies
- Identify special tokens (emojis, codes)
- Cleaning & Transformation
- Remove HTML, metadata only if irrelevant
- Normalize case, punctuation as needed
- Decide on stopwords based on task
- Validation
- Check random samples for meaning retention
- Test with small-scale models
- Ongoing Monitoring
- Set up continuous profiling for new data
- Periodically review pipeline impact
Checklists don’t just prevent disasters—they’re your insurance policy.
Beyond the basics: Emerging trends and what’s next for preprocessing
AI-driven preprocessing: What actually works (and what’s hype)
Everyone’s chasing “automated everything,” but the reality is nuanced. AI-driven preprocessing tools that profile, clean, and transform data on the fly are game-changers—when calibrated. But black-box solutions that promise “one-click cleaning” often obscure bias, introduce errors, or erase subtlety.
| Tool Type | Reality | Hype |
|---|---|---|
| Context-aware cleaning | Increases accuracy, preserves meaning | “Solves all problems” |
| Auto-detect pipelines | Great for profiling, need oversight | “Fully replaces humans” |
| ML-driven normalization | Adapts to new data types | “No need for QA” |
Table 7: AI preprocessing solutions—fact vs. fiction. Source: Original analysis based on ACM, 2024
The verdict: AI helps, but you still need a human in the loop.
Cultural and ethical dimensions: Who gets left out?
Preprocessing isn’t neutral. Choices about what to clean or keep can erase minority dialects, introduce bias, or silence marginalized voices. Industry experts warn: ethical preprocessing means profiling data for representativeness, not just cleanliness.
If your pipeline erases the slang of an underrepresented group, it’s not just an oversight—it’s a problem.
“Ethical preprocessing means knowing whose voices your pipeline serves—and whose it erases.” — Paraphrased from ACM, 2024
The future of NLP belongs to those who get this right.
Open-source tools and communities shaping the field
The ecosystem is exploding with robust, tested tools and communities that keep pushing the field forward:
- spaCy: Fast, customizable, community-driven NLP toolkit
- NLTK: The OG of Python NLP, still widely used for education and prototyping
- Transformers (Hugging Face): Model zoo and preprocessing for state-of-the-art architectures
- SentencePiece: Subword tokenizer, now standard for multilingual pipelines
- Textwall.ai: For advanced document analysis and preprocessing at scale
Open-source is where innovation happens—and where you find answers to tomorrow’s problems.
Glossary: Cutting through the jargon
Tokenization
Dividing text into meaningful units, typically words or subwords. How you split matters—context-aware tokenizers (like SentencePiece or BPE) are the industry standard for complex tasks.
Normalization
Standardizing text (case, punctuation, unicode). Ensures consistency, but careless use can flatten nuance.
Embedding
A dense numeric vector representing words, phrases, or documents. Powers modern NLP; requires context-sensitive preprocessing.
Stopwords
Common words (like “the”, “and”) often, but not always, removed from text. Modern models can learn their importance—don’t just delete by default.
Pipeline bias
Errors or distortion introduced by the sequence of preprocessing steps. Can affect fairness, explainability, and accuracy if not controlled.
Getting these terms right isn’t just semantics—it’s survival.
Conclusion: The new rules of text data preprocessing
Synthesis: What you must remember in 2025 and beyond
Text data preprocessing techniques are no longer static checklists—they’re dynamic, context-sensitive strategies that make or break results. Minimal but targeted cleaning, context-aware tokenization, and continuous data profiling have replaced blunt-force methods. The risks of bias, context loss, and overfitting are very real, and the stakes—ethical, financial, reputational—have never been higher.

The smartest teams in NLP and document analysis, including innovators like textwall.ai, recognize that preprocessing is where the real leverage lies. The “right” pipeline is never one-size-fits-all—it’s the one that preserves meaning, respects context, and evolves with your data.
In the world of AI, your model is only as good as your data. Don’t let outdated preprocessing turn your insights into noise.
Where to go next: Resources and communities
- spaCy Documentation
- Hugging Face Transformers
- Text Technologies for Data Science, Edinburgh
- ACM Digital Library: Text Preprocessing Papers
- Textwall.ai’s NLP resources
Find your tribe—because the only thing worse than bad data is going it alone.
Sources
References cited in this article
- Is text preprocessing still worth the time? (ACM, 2024)(dl.acm.org)
- Demystifying Data Management for LLMs (ACM, 2024)(dl.acm.org)
- Text Technologies for Data Science (Edinburgh, 2023)(opencourse.inf.ed.ac.uk)
- DataCamp Guide(datacamp.com)
- TimesPro Blog(timespro.com)
- Astera Blog(astera.com)
- Is text preprocessing still worth the time? (ScienceDirect, 2024)(sciencedirect.com)
- Kavita Ganesan, FreeCodeCamp(freecodecamp.org)
- 13 AI Disasters of 2024 (Medium)(medium.com)
- Software Failures 2024 (Cigniti)(cigniti.com)
- Visier Blog(visier.com)
- GeeksforGeeks(geeksforgeeks.org)
- Scale AI Blog(exchange.scale.com)
- TopBots Guide(topbots.com)
- KDnuggets(kdnuggets.com)
- GoML.io(goml.io)
- Analytics Vidhya(analyticsvidhya.com)
- TheAILearner(theailearner.com)
- ACL Anthology(aclanthology.org)
- Medium Guide(medium.com)
- Towards Data Science, 2024(towardsdatascience.com)
- Bitext Blog(blog.bitext.com)
- IBM Think(ibm.com)
- PeerJ Computer Science, 2024(peerj.com)
- Cambridge Core, 2023(cambridge.org)
- Atlan, 2024(atlan.com)
- Oxford Academic, 2023(academic.oup.com)
- ResearchGate, 2024(researchgate.net)
- Medium (Farhan Sarguroh)(farhansarguroh.medium.com)
- StudyMachineLearning(studymachinelearning.com)
- MIT Press, 2024(direct.mit.edu)
- OpenReview, 2023(openreview.net)
- MetaSource, 2024(metasource.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What percentage of time do data scientists spend on data wrangling according to the article?
According to TimesPro (2024) research cited in the article, data scientists spend roughly 60% of their time wrangling data instead of innovating.
Why is choosing the right preprocessing pipeline important?
According to Siino et al. (2024), choosing the right preprocessing pipeline is as important as model choice because it affects downstream task success, influencing accuracy, bias, explainability, and legal compliance.
What are examples of common preprocessing mistakes mentioned in the article?
The article mentions over-cleaning (removing context, leading to data sparsity and loss of nuance) and under-cleaning as common mistakes that can sabotage machine learning models.
What types of data artifacts can damage model performance?
The article states that subtle artifacts such as overlooked typos, stray emojis, and rogue HTML tags can introduce bias, derail classification, and create brittle models.
Keep Reading
Explore more from Advanced document analysis

The Truth About Text Mining Strategies: What Works & What’s a Waste
Discover 9 game-changing tactics to unlock real insights from messy data. Go beyond the hype with expert tips, warnings, and bold new approaches.

Is Text Analytics Changing Everything? the Truth in 2026
Text analytics applications are transforming industries in 2026—uncover hidden risks, real-world uses, and new breakthroughs. Don’t miss the future. Read now.

What Nobody Tells You About Text Extraction Apis in 2026
Text extraction APIs face new realities in 2026—discover the edgy truths, biggest pitfalls, and actionable playbook for advanced document analysis. Don’t get left behind.

Text Analytics in 2026: What No One Dares to Tell You
Stare long enough into the abyss of your company’s data, and the abyss blinks back. In 2025, the phrase “text analytics solutions” isn’t just a marketing

Text Analytics Best Practices for 2026: From Hype to Hard ROI
Discover insights about text analytics best practices

The Dark Art of Text Segmentation: Myths, Mistakes, and Breakthroughs
Text segmentation techniques aren’t what you think. Get the raw, actionable guide that exposes myths, compares methods, and reveals how segmentation shapes real-world AI in 2026.

Text Classification Methods: the Brutal Truth Behind 2026’s Smartest Strategies
Discover 2026’s most effective, surprising strategies and pitfalls. Unmask myths, get real-world advice, and choose the right approach.

7 Text Extraction Methods That Will Blow Your Mind in 2026
Discover 7 game-changing techniques to pull hidden data from any document. Break free from data chaos—find out how today.

Is Your Text Segmentation Software Lying to You?
Let’s be honest: if you’re still treating text segmentation software as a “nice-to-have,” you’re already falling behind. In the age of information overload,