
Intelligent Text Extraction in 2026: Breakthroughs, Risks, Reality
If you think intelligent text extraction is just OCR in a flashy new suit, you’re about to get a reality check. In 2025, AI-driven document analysis is not only breaking the rules—it’s exposing the cracks in how businesses, law, and media have played the information game for decades. We’re swimming in more data than ever, and the stakes have multiplied. One missed clause, buried insight, or mistyped field can cost millions, kill careers, or bury truths that needed a searchlight. This isn’t sci-fi: it’s the brutal, brilliant now. In this deep dive, we’ll pull apart the hype, the hidden pitfalls, and the actionable strategies that separate hype from hard results. You’ll see how technologies like LLMs and context-aware AI extractors are changing the very nature of work, power, and trust. Welcome to the edge—where intelligent text extraction is smarter (and sneakier) than you think.
Why intelligent text extraction matters more than ever
From information overload to insight: the new urgency
The digital document tidal wave isn’t a metaphor—it’s a daily reality crashing over every sector. As of 2025, the average enterprise processes over 2.2 million documents annually, up from just 400,000 a decade ago. Manual review hasn’t just buckled; it’s imploded. According to recent IDP market reports, classic data entry teams now face error rates upwards of 5%—a figure that may sound small until you realize it means tens of thousands of missed or mangled data points every year. This chaos isn’t just a productivity drag; it’s an existential threat.
The cost isn’t abstract. Businesses lose opportunities, money, and sleep over what slips through the cracks. Every minute spent sifting through noise instead of acting on insight is a minute closer to irrelevance. The emotional toll is real, too: over 70% of professionals surveyed in a 2024 industry study reported “data fatigue” as a top cause of workplace stress, with direct impact on mental health and decision-making clarity.

| Metric | 2015 Value | 2025 Value |
|---|---|---|
| Avg. docs processed/company | 400,000 | 2,200,000 |
| Manual error rate (%) | 8.6 | 5.1 |
| Manual labor hrs/year | 18,200 | 5,900 |
| AI-processed docs (%) | 12 | 64 |
Table 1: Document processing growth, error rates, and labor hours: 2015 vs. 2025. Source: Original analysis based on Scoop Market, 2024, Docsumo, 2025
The high-stakes risks of getting it wrong
Picture this: a global retailer missed a crucial contract clause due to faulty extraction, triggering a $7 million penalty for non-compliance. The fallout? Shareholder lawsuits, negative headlines, and months of costly remediation. When extraction fails, it isn’t just about spreadsheets—it’s about reputations, legal exposure, and market position. According to a 2024 Expert Beacon review, every 1% extraction error in regulated industries translates to an average of $350,000 in annual losses.
"One missed clause can cost millions—AI can't afford to blink." — Alex, industry expert, Expert Beacon, 2024
- Compliance gaps: Overlooked regulatory terms can trigger audits, penalties, or worse.
- Bias amplification: Algorithms that misread ambiguous phrases may reinforce old biases.
- Decision paralysis: Incomplete or misclassified data chokes workflow velocity.
- Legal liability: Inaccurate extraction can invalidate contracts or expose confidential data.
- Financial exposure: Missed invoice terms mean lost revenue or duplicated payments.
- Reputational harm: News of a data breach or contractual blunder spreads fast.
- Lost competitive edge: Slow extraction means missed opportunities and insights.
What users really want: clarity, speed, truth
Modern users don’t just want data. They demand instant, actionable, and transparent results—no more wading through noise or second-guessing black-box systems. The frustration with legacy tools is palpable: according to user surveys, top complaints include inconsistent accuracy, lack of explainability, and clunky interfaces that turn simple tasks into epic quests. The hunger is for tools that surface truth—not just data—at the speed of business.
This is where platforms like textwall.ai are carving out trust. By focusing on clarity, speed, and verifiable insight, they’ve become indispensable for everyone from corporate analysts to researchers drowning in the document deluge. In a world where time is money and accuracy is currency, settling for less is no longer an option.
The evolution: from dumb OCR to context-aware AI
OCR’s awkward adolescence: why old tech failed
OCR (Optical Character Recognition) looked revolutionary in the 90s. It digitized text, sure—but with all the subtlety of a sledgehammer. Early systems botched handwriting, mangled fonts, and had a nasty habit of swapping “0” for “O” or missing entire blocks of text. Entire legal teams spent their days double-checking what OCR had “helped” them process, and horror stories abound: medical instructions rendered unreadable, invoices with swapped figures, and contracts where key terms simply vanished.
| Era | Key Advance | Impact/Notes |
|---|---|---|
| 1990s | Classic OCR | Digitizes print, high error rates |
| 2005-2015 | Rule-based, template-driven extraction | Improved forms, failed on non-standard docs |
| 2017 | Neural OCR, first ML models | Better accuracy, still context-blind |
| 2020 | NLP engines, basic semantic parsing | Early context, prone to shallow misreads |
| 2023-2025 | LLM-powered, context-aware extraction | Near-human nuance, multi-format, low-code config |
Table 2: Timeline of text extraction advances, 1990s–2025. Source: Original analysis based on Docsumo, 2025, Expert Beacon, 2024
The leap to context-aware AI wasn’t just inevitable—it was essential. Rule-based approaches collapsed under the complexity of real-world documents, where nuance trumps templates every time.
The LLM revolution: context is everything
Large Language Models (LLMs) didn’t just up the ante—they rewrote the rules. Where old systems saw raw pixels and strings, LLMs grasp structure, intent, and the semantic web holding text together. Suddenly, ambiguity wasn’t a death sentence—it was a challenge to be met head-on.
Today’s LLM-powered extractors don't just grab keywords; they understand that “termination” could mean job loss or contract closure, depending on context. They resolve subtle ambiguities, map relationships, and even surface hidden sentiment. This is the technical leap: AI that “reads” like a skeptical analyst, not a naive automaton.
Key terms (in plain English):
- LLM (Large Language Model): Think of it as a digital Sherlock Holmes—spotting patterns, reading between the lines, and always asking, “What’s really being said?”
- NLP (Natural Language Processing): The science behind letting machines understand human speech and text—idioms, sarcasm, all of it.
- Semantic extraction: Pulling not just words, but meaning and relationships—like spotting that “CEO” and “John Doe” are connected.
- Context window: The amount of text an AI “remembers” at once—like a human’s short-term memory, only supersized.

Why 'intelligent' doesn’t always mean 'accurate'
Let’s kill the myth: even the smartest AI stumbles. Intelligent text extraction isn’t magic, and edge cases still trip up the best systems. Picture an NDA with a clause written in legalese so dense even partners argue over it—AI can struggle just like humans. Sometimes, the model gets “confidently wrong,” hallucinating details or missing cultural context.
That’s why human-in-the-loop validation isn’t optional—it’s mandatory. Combining AI speed with critical human review prevents costly blunders, while regular audits keep bias and drift in check.
"Smart extraction is only as good as your skepticism." — Priya, data scientist, Expert Beacon, 2024
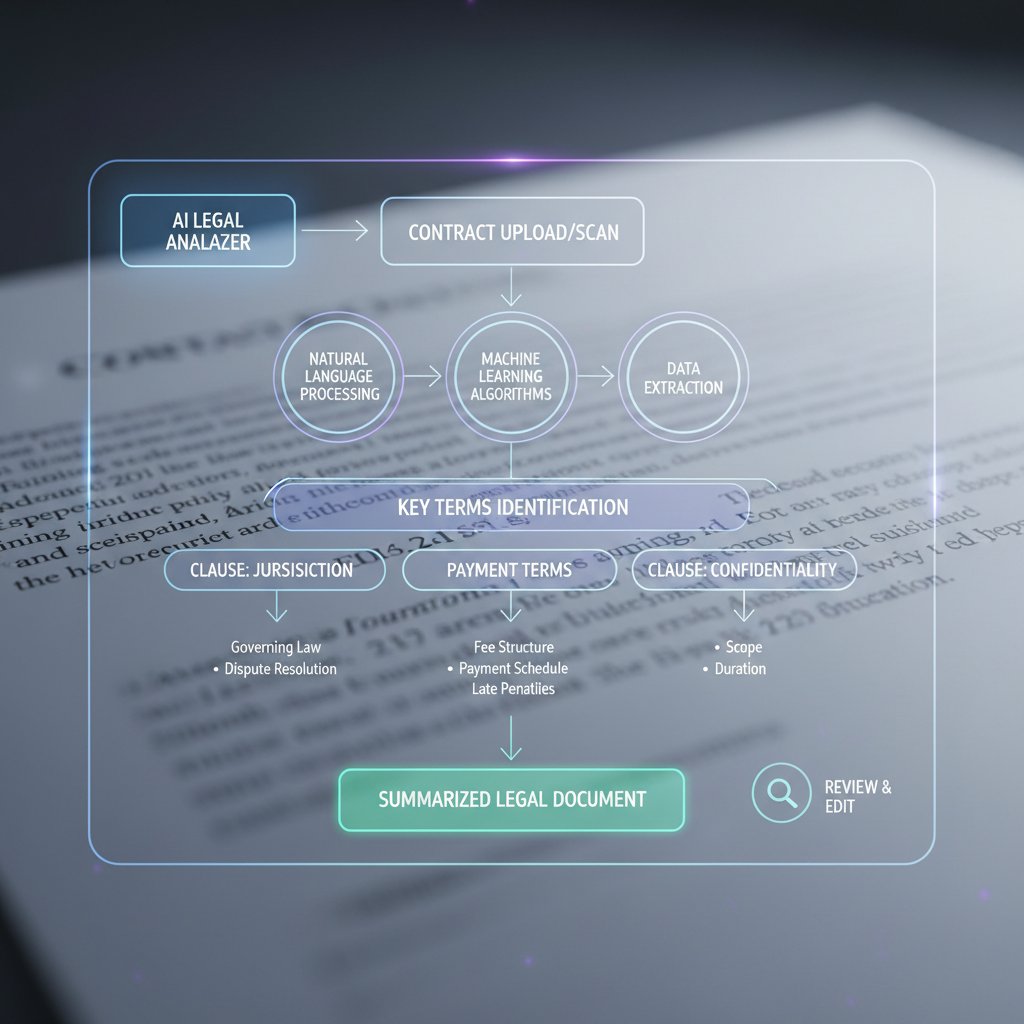
How intelligent text extraction actually works (no BS)
The anatomy of an extraction pipeline
Let’s break down the journey from raw document to actionable insight. Every extraction pipeline, whether you’re using textwall.ai or coding your own, follows key steps:
- Document upload: Whether via drag-and-drop or API, your file enters the system.
- Preprocessing: Images get deskewed, noise is reduced, and PDFs are split into digestible chunks.
- OCR or raw text parsing: For images and scanned docs, OCR digitizes content. For digital docs, native parsing grabs the text.
- Tokenization: Text is sliced into logical units—words, sentences, or even semantic blocks.
- Model inference: Here’s where the LLM or extraction engine interprets, labels, and pulls entities, relationships, and more.
- Post-processing: Outputs are cleaned, formatted, and validated against rules or schemas.
- Human review (optional): Edge cases or low-confidence outputs are flagged for expert eyes.
- Actionable output: Data is exported (CSV, JSON, XML) or integrated into downstream systems.
Errors creep in at every stage: blurry scans, misclassified entities, context loss, or bad post-processing logic. Regular audits and well-tuned confidence thresholds are your reality check against automation run wild.
Beyond text: extracting meaning, not just words
Today’s AI isn’t just scanning for words; it’s mapping meaning. Named entity recognition (NER) pulls out names, places, dates; relationship mapping links them—who signed what, when, and why. Sentiment analysis surfaces the tone—hostile, neutral, or deferential. For example, in a contract, AI can extract parties, deadlines, obligations, and even spot risky clauses. The difference? It’s the chasm between copying text and surfacing actionable, legal, or business-critical insights.
Common mistakes (and how to avoid them)
Even smart teams fall into classic traps:
- Assuming out-of-the-box accuracy: Industry jargon and document variations kill off-the-shelf models.
- Ignoring preprocessing quality: Garbage-in still means garbage-out.
- Overfitting to training data: Models that ace test sets but fail in the wild.
- Misclassifying entities: “Net price” vs. “gross price” is not a rounding error.
- Lack of confidence calibration: No thresholds mean all results look equally trustworthy.
- Skipping human validation: Blind trust in AI is a recipe for disaster.
- Neglecting continuous retraining: New document types or language drift will break yesterday’s models.
For better results: always tailor models to your data, set up validation workflows, and monitor outputs like a hawk. The mantra? Trust, but verify.
Real-world case studies: extraction in action (and disaster)
The finance fiasco: when automation backfires
In late 2023, a major bank rolled out a new extraction pipeline to process loan agreements. The promise: slash review time by 60%. The reality: a misconfigured entity extraction model swapped borrower and guarantor fields on 3,500 documents. Regulators fined the institution $2.8 million for non-compliance, and the manual clean-up wiped out any cost savings for the year. According to the bank’s post-mortem, error rates before the incident averaged 1.2%; during the crisis, they spiked to 8.4%. Recovery required retraining models, instituting human-in-the-loop review at key steps, and publishing a monthly accuracy dashboard.
| Metric | Before Incident | During Incident | After Remediation |
|---|---|---|---|
| Extraction accuracy | 98.8% | 91.6% | 99.3% |
| Time to process | 4 days | 2 days | 2.2 days |
| Losses incurred | $0 | $2.8M | $0 |
Table 3: Financial sector extraction error—impact and recovery. Source: Original analysis based on Expert Beacon, 2024
Lesson? Validation isn’t optional. Automation without oversight is risk multiplied.
Healthcare, law, and media: unexpected heroes and villains
Hospitals have embraced AI-powered text extraction for patient intake, cutting form processing time from 40 minutes to under 10 and reducing admin errors by 50% (Docsumo, 2025). This means faster care and better data continuity.
Meanwhile, a top-tier law firm tried automating contract review, only to find that AI missed subtle jurisdictional nuances. The result: costly amendments and a stern warning from regulators. Investigative journalists, on the other hand, have weaponized extraction to unearth hidden links in court filings and leaked emails, breaking stories that might have stayed buried for years.
"The right tool can turn chaos into clarity, or the reverse." — Jamie, analyst, Docsumo, 2025
Your next move: what these stories teach us
Extracting value from AI isn’t about blind faith—it’s about rigor, nuance, and never assuming automation is infallible. Before adopting intelligent extraction, organizations must audit processes, set monitoring KPIs, and plan for ongoing tuning.
Self-assessment checklist for organizations:
- Have you benchmarked current manual processes for speed and accuracy?
- Is your sample data representative of real-world variety and edge cases?
- Do you have clear validation and exception-handling workflows?
- Can you trace model decisions for compliance audits?
- Are you tracking extraction KPIs (accuracy, recall, false positives)?
- How do you handle ambiguous or low-confidence outputs?
- Is there a feedback mechanism for continuous improvement?
- Have you reviewed vendor transparency and data privacy commitments?
- Are your teams trained to question, not just consume, automation?
- How often do you retrain or refresh extraction models?
Each “yes” is a building block of robust, resilient automation.
Choosing the right tool: how to sift hype from reality
Features that actually matter (and which are just noise)
Not all extraction platforms deliver on the sales pitch. The hype centers on AI, but what matters most are context awareness, error reporting, explainability, and airtight security. Nothing else substitutes for these real-world needs.
| Feature/Metric | Manual Review | Classic OCR | LLM-based Extraction |
|---|---|---|---|
| Speed | Slow | Fast | Fastest |
| Accuracy | Highest* | Low–Medium | Very High (99%+) |
| Cost | Highest | Low | Moderate |
| Flexibility | High | Very Low | High |
| Context awareness | Human-level | None | Near-human |
| Explainability | Strong | None | Strong (if built-in) |
*Manual review is only “highest” when humans are well-rested, motivated, and highly trained—which is rare at scale.
Table 4: Comparison of document review approaches—speed, accuracy, cost, flexibility. Source: Original analysis based on Scoop Market, 2024, Docsumo, 2025
Numbers don’t lie: LLM-driven tools hit the sweet spot for most real-world needs, but only when embedded with explainable, user-friendly workflows.
Red flags and hidden costs
Buyer beware: Not all tools play fair. Watch for:
- Vendor lock-in: Proprietary formats trap your data and limit portability.
- Black-box models: If you can’t see how the results are produced, trust erodes fast.
- Weak error handling: Platforms that bury mistakes invite disaster.
- Opaque pricing: Hidden fees for “premium” features or extra API calls.
- Poor data privacy: Lax controls can leak customer or proprietary data.
- Lack of support: Community forums are no substitute for real accountability.
- Unclear documentation: If you can't tell what it does, neither can your auditors.
- No integration roadmap: Legacy system headaches await.
Textwall.ai stands out for transparency, robust documentation, and a commitment to user control—qualities that the savviest organizations now demand.
Integration headaches (and how to cure them)
API compatibilities, clashing data schemas, and stubborn legacy software are the classic integration nightmares. But they don’t have to be showstoppers.
- Audit your existing tech stack for compatibility.
- Prioritize tools with open APIs and strong documentation.
- Start with pilot integrations, not big-bang launches.
- Leverage data mapping utilities for schema alignment.
- Create rollback plans for failed integrations.
- Document every step for repeatability and compliance.
Future-proofing means picking adaptable, standards-based platforms and never letting short-term convenience become tomorrow’s straightjacket.
Advanced strategies: getting more from your data
Training custom models for your niche
Plug-and-play models fail when documents get weird—think industry-specific jargon, regulatory forms, or deeply technical manuals. Three proven strategies for fine-tuning:
- Curate a diverse, edge-case-rich training set from your own archives.
- Use transfer learning to adapt open models to your context.
- Continuously retrain with live feedback from users and subject-matter experts.
Cost varies: custom model training can run $20,000–$200,000 depending on complexity and volume, but ROI is measured in fewer compliance failures, faster workflows, and sharper competitive insight.
Human-in-the-loop: striking the right balance
Even the best models need expert backup. The “human-in-the-loop” approach ensures that low-confidence, ambiguous, or high-risk extractions get a second look.
Definitions:
- Human-in-the-loop: A workflow where experts review, correct, and approve AI outputs—vital for regulated industries.
- Confidence threshold: A score at which the AI defers to humans for review.
- Validation workflow: The process for escalating, annotating, and learning from errors.
Effective feedback loops—where corrections are fed back into model training—make the difference between static and ever-improving extraction.
Monitoring, metrics, and continuous improvement
Extraction isn’t a “set and forget” project. Ongoing monitoring of these KPIs is non-negotiable:
- Extraction accuracy (%)
- Recall (ability to find all relevant data)
- Precision (minimizing false positives)
- Error rate by document type
- Turnaround time per doc
- Human intervention rate
- Model drift (performance over time)
For optimization: schedule regular audits, retrain models on real-world errors, and reward teams for surfacing—not hiding—mistakes.
The dark side: privacy, security, and ethical dilemmas
When extraction reveals too much
AI-driven text extraction can inadvertently surface sensitive information that was never meant for broad eyes. From accidental exposure of medical histories in poorly secured datasets to leaks of confidential contract terms in financial services, the list of recent breaches is long—and growing. Each incident erodes public trust and invites regulatory scrutiny.

Bias, fairness, and the myth of neutrality
AI models soak up the biases in their training data. An extraction pipeline fed only Western contracts may fumble with global templates, amplifying pre-existing inequities. Notably, a 2024 audit found that several leading extraction tools misclassified female and minority names at a rate 2.5x higher than majority names.
- Audit data for representation gaps and edge cases.
- Track extraction accuracy across demographic slices.
- Flag ambiguous terms for manual review.
- Benchmark outputs against human-curated gold standards.
- Rotate training data sources regularly.
- Involve diverse experts in validation.
Ethically, organizations owe it to users to monitor, disclose, and correct these biases—not sweep them under the rug.
Regulatory gray zones: what you need to know
Data regulations are scrambling to keep up. GDPR, CCPA, and new AI-specific statutes demand transparency, auditability, and data residency controls. In Europe, localization laws require that extracted data stay within borders—even as cloud pipelines span continents.
Compliance checklists now include explainability of AI decisions, traceability of model changes, and user consent for automated processing.
"Regulators move slow—risk moves fast." — Morgan, policy expert, Expert Beacon, 2024
Future shock: what’s next for intelligent text extraction
Frontiers: multimodal extraction and beyond
Cutting-edge platforms are blending text, images, and even audio for richer, layered analysis. Imagine extracting contract clauses from a scanned PDF, speaker identities from a boardroom transcript, and mood from a recorded negotiation—all in one pass. These multimodal systems are already piloted in high-stakes journalism and compliance.

Open-source vs. proprietary: the coming battles
Open-source frameworks are democratizing intelligent extraction. While proprietary tools offer support, polish, and integrations, open-source delivers transparency, community-driven innovation, and total control.
| Feature | Open-source | Proprietary |
|---|---|---|
| Community | Vibrant | Limited |
| Customizability | High | Low–Medium |
| Support | Community | Commercial |
| Cost | Low | Moderate–High |
| Innovation speed | Fast | Slower |
| Data privacy | High (if self-hosted) | Varies |
Table 5: Open-source vs. proprietary extraction tools—feature matrix. Source: Original analysis based on Docsumo, 2025
Smart teams often run hybrids: open-source for core logic, proprietary for scale and support.
The human impact: will extraction kill or create jobs?
Job displacement is real: data entry roles are shrinking fast. But demand is booming for AI trainers, model validators, workflow designers, and compliance auditors. According to industry projections, over 40% of companies created new roles in “AI oversight” and “data strategy” in 2024 alone.
- AI workflow designer
- Model validation analyst
- Data ethicist
- Legal tech specialist
- Human feedback loop manager
- Bias auditor
- Document security engineer
Adaptation isn’t just survival—it’s the path to entirely new careers.
Practical guides and resources
Step-by-step: implementing intelligent extraction in your organization
Getting started requires more than a budget—it needs a plan.
- Define clear business outcomes (compliance, speed, cost).
- Map document types and sources.
- Benchmark current processes (accuracy, speed, pain points).
- Pick pilot documents for initial testing.
- Vet and shortlist vendors using your actual data, not demos.
- Test for integration fit with existing systems.
- Set up validation and exception workflows.
- Monitor KPIs from day one.
- Retrain and calibrate based on real-world feedback.
- Schedule quarterly reviews and updates.
Roadblocks? Expect data silos, internal resistance, and “unknown unknowns.” Early wins and transparent reporting are the best antidotes.
Jargon decoded: your extraction glossary
Clarity kills confusion. Here’s your no-BS dictionary:
Automated process of pulling structured, actionable data from unstructured documents using AI.
Converts images or scans of text into machine-readable characters.
Identifies people, places, organizations, and other key entities in text.
AI model trained on vast swathes of text data, capable of nuanced interpretation.
Pulls not just words but the relationships and meanings between them.
Workflow where experts validate or correct AI outputs.
The cut-off score for sending extraction outputs for human review.
When model performance degrades over time as documents or language evolve.
For more definitions, see the textwall.ai glossary.
Where to go deeper: recommended reading and tools
There’s no shortage of brains in this game. For the best research and platforms:
- Scoop Market, 2024: Authoritative market statistics and trends.
- Docsumo, 2025: In-depth market analysis and tool reviews.
- Expert Beacon, 2024: Expert takes on OCR accuracy and pitfalls.
- Textwall.ai: Community insights, best practices, and real-world guides.
- OpenAI GPT-4 documentation: Deep dive into LLMs and extraction APIs.
- Stanford NLP Group: Cutting-edge research, tools, and open datasets.
Top tools shaping the future:
- Textwall.ai: Enterprise-ready, context-aware extraction—trusted by analysts and researchers alike.
- Docsumo: High-accuracy, multi-format document extraction for business.
- Google Document AI: Flexible, cloud-based pipeline with strong NLP.
- Microsoft Azure Form Recognizer: Enterprise integration and compliance credentials.
- Open-source frameworks (e.g., spaCy, Hugging Face Transformers): Community-driven, highly extensible.
- ABBYY FlexiCapture: Deep roots in OCR, now evolving for AI-driven workflows.
Controversies, myths, and what everyone gets wrong
The biggest misconceptions about intelligent text extraction
Let’s torch some persistent myths:
- AI “understands” text like a human: It simulates understanding—it doesn’t “know” or “comprehend.”
- Black-box models are always better: Without explainability, trust is an illusion.
- More data = better extraction: Quality beats quantity every time.
- Automation replaces all manual review: Not in law, finance, or regulated domains.
- Humans can’t add value: Expert oversight is still the ultimate failsafe.
- One-size-fits-all works: Jargon and document structure differ wildly by industry.
- AI never makes mistakes: It just makes different—and sometimes weirder—ones.
- All tools are equally secure: Security is a design choice, not a given.
- Extraction is “set and forget”: In reality, it’s a living, breathing process.
The contrarian’s view: when manual beats AI
In highly creative, subjective, or nuanced domains—think literary analysis, contract renegotiation, or investigative research—human review still reigns. No AI can yet parse sarcasm, cultural subtext, or legal gray areas with a master’s touch.
"Sometimes, slow is fast when precision is non-negotiable." — Sam, researcher
What success really looks like: it’s not perfection
The real measure of intelligent text extraction isn’t 100% accuracy—it’s actionable, explainable insight delivered with speed and confidence. Failures and edge cases are not proof the tech is broken; they’re signals for where human judgment and better training are required. The goal? “Good enough” to act, “transparent enough” to trust, and “nimble enough” to evolve.
Conclusion
Intelligent text extraction in 2025 is more than a tech trend—it’s a new lens on power, truth, and decision-making. The rules are being rewritten: AI now reads documents at scale, surfaces insights, and exposes blind spots that humans didn’t even know existed. But the pitfalls are every bit as real: bias, error, and overconfidence lurk wherever oversight lapses. The organizations that thrive aren’t those with the flashiest tools, but those with the toughest questions, the most rigorous validation, and the guts to challenge both machine and human judgment. If you want to outsmart the chaos, clarity is your best weapon—and as this guide shows, the combination of intelligent extraction, skeptical oversight, and relentless curiosity is the only way to stay ahead. Don’t settle for noise—demand better answers, and let the truth rise to the top.
Sources
References cited in this article
- Scoop Market(scoop.market.us)
- Docsumo(docsumo.com)
- Expert Beacon(expertbeacon.com)
- Fortune Business Insights(fortunebusinessinsights.com)
- V7 Labs(v7labs.com)
- SortSpoke(sortspoke.com)
- Hyperscience(hyperscience.ai)
- Microsoft Learn(learn.microsoft.com)
- Centre for Emerging Technology and Security(cetas.turing.ac.uk)
- Frontiers in Computer Science(frontiersin.org)
- evolution.ai(evolution.ai)
- Rossum(rossum.ai)
- NanoNets(medium.com)
- Intelligent Document Processing News(intelligentdocumentprocessing.com)
- Expert.ai(expert.ai)
- Commercient(commercient.com)
- Newgen(newgensoft.com)
- ResearchGate(researchgate.net)
- Evolution AI(evolution.ai)
- Kanverse.ai(kanverse.ai)
- Pretalx Hack.lu 2024(pretalx.com)
- Innovative Driven(innovativedriven.com)
- Auxis IDP Guide 2024(auxis.com)
- Gartner Peer Insights(gartner.com)
- Rapid Innovation(rapidinnovation.io)
- Docsumo Trends(docsumo.com)
- AIMultiple(research.aimultiple.com)
- ISG Buyers Guide 2024(research.isg-one.com)
- Cloud Security Alliance(cloudsecurityalliance.org)
- IEEE Security & Privacy 2025(sp2025.ieee-security.org)
- HackersGrid(hackersgrid.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What is the current scale of document processing in enterprises as of 2025?
As of 2025, the average enterprise processes over 2.2 million documents annually, up from 400,000 a decade ago, representing a significant increase in data volume that manual review processes can no longer handle effectively.
What error rates do manual data entry teams currently experience?
Classic data entry teams now face error rates upwards of 5%, which translates to tens of thousands of missed or mangled data points every year across enterprises.
What percentage of professionals report data fatigue as a workplace concern?
According to a 2024 industry study, over 70% of professionals surveyed reported 'data fatigue' as a top cause of workplace stress, with direct impact on mental health and decision-making clarity.
How has AI document processing adoption changed from 2015 to 2025?
AI-processed documents have increased from 12% in 2015 to 64% in 2025, while manual labor hours have decreased from 18,200 to 5,900 hours per year over the same period.
Is intelligent text extraction just an upgraded version of OCR technology?
No; the article states that intelligent text extraction is not just OCR in a new form, but rather AI-driven document analysis powered by technologies like LLMs and context-aware AI extractors that are fundamentally changing the nature of work, power, and trust.
Keep Reading
Explore more from Advanced document analysis

Everything You Know About Text Extraction Software Is Wrong
Text extraction software is rewriting the rules in 2026. Discover hidden truths, avoid costly mistakes, and unlock the real power of automated document analysis.

7 Text Extraction Methods That Will Blow Your Mind in 2026
Discover 7 game-changing techniques to pull hidden data from any document. Break free from data chaos—find out how today.

Text Extraction Solutions Will Change Your Mind in 2026
Text extraction solutions are changing fast. Uncover the 9 brutal truths, new breakthroughs for 2026, and how to avoid the pitfalls. Read before you choose.

The Dark Side of Document Content Extraction: What You’re Missing
If you think “document content extraction” is just a buzzword for automating boring paperwork, buckle up—because the truth is sharper, messier, and far more

7 Truths About Document Extraction Systems Nobody’s Telling You
Discover the hard truths, real risks, and future-proof strategies for AI-driven document processing in 2026. Don’t get left behind.

The Dark Side of Document Knowledge Extraction (and How to Win)
Document knowledge extraction unlocked: Discover hidden risks, real-world strategies, and 2026’s boldest breakthroughs in document intelligence. Don’t settle for surface insights—dive deep now.

Are Document Extraction’s Promises Real? 2026 Insights Revealed
Document extraction industry insights for 2026—expose myths, see what’s next, and unlock bold opportunities. Get the edge with in-depth, no-BS analysis. Don’t get left behind.

Are You Ready for the Brutal Reality of Intelligent Data Extraction?
Intelligent data extraction isn’t just hype—discover the raw realities, killer pitfalls, and breakthrough strategies shaping the future of document analysis. Get ahead or get left behind.

The AI Secret: What Information Extraction Software Is Really Doing to Your Documents
Information extraction software is rewriting how we mine meaning from chaos. Discover hidden risks, real wins, and why 2026 is a pivotal year.