
Document Data Processing in 2026: Power, Pitfalls, and Payoff
There’s a war raging quietly behind every corporate firewall and blinking inbox notification—a battle for control over the world’s most valuable commodity: information. Document data processing is no longer the back-office drudgery you ignore until quarter-end. It’s the engine that powers compliance, competitive edge, and multi-billion-dollar industries—while also being a hotbed for bias, security breaches, and strategic blunders. Whether you’re a CEO, legal eagle, or data analyst sleepwalking through a sea of PDFs, you’re already on the frontlines. Armed with AI, today’s document analysis systems promise to turn data chaos into clarity, but what are they really doing—and at what cost? This is more than an exposé: it’s your deep dive into the messy, exhilarating, and sometimes dangerous reality of AI-powered document data processing. Strap in.
Why document data processing matters now more than ever
The quiet revolution in your inbox
Forget the flashy headlines about robot overlords—real change comes in tiny, relentless waves. Every time you forward a contract, archive an invoice, or receive a cryptic meeting summary, AI is lurking in the pipelines. According to Expert Market Research, the global Intelligent Document Processing (IDP) market was valued at $4.51 billion in 2023, with projections soaring to $65.87 billion by 20321. That’s a compound annual growth rate north of 34%. Why? Because nearly every organization is drowning in unstructured data, and 94% are already leveraging cloud-based document processing just to stay afloat2.

“Documents remain a human-centric medium essential for communication and decision-making; AI augments, not replaces, human roles.”
— Forbes Tech Council, 2023 (Source)
From chaos to clarity: the stakes of getting it wrong
Document data processing isn’t just about speed. It’s about survival. The stakes? Think regulatory fines, competitive intelligence leaks, and multi-million dollar contract losses. According to MetaSource, over 50% of IDP solutions now integrate advanced AI/ML models, which are critical for compliance and operational efficiency3. But as organizations rush to automate, they face a brutal paradox: the faster you move, the harder you crash if your data pipeline is flawed. This isn’t just theory—it’s the reason why document automation has shifted from nice-to-have to business necessity.
| Problem Area | Consequence | Industry Example |
|---|---|---|
| Compliance failure | Hefty fines, legal exposure | Banking |
| Data entry errors | Wrong decisions, lost revenue | Retail |
| Slow contract review | Missed opportunities, delayed revenue | Legal |
| Unsecured data pipelines | Breach, IP theft, reputation damage | Tech |
Table 1: The high-risk consequences of poor document data processing. Source: Original analysis based on MetaSource, Info-Source, and Expert Market Research.
When the stakes are this high, chaos isn’t an option—it’s an existential threat.
The real-world cost of bad data
If you think bad data is just a technical hiccup, think again. According to recent research from Docsumo, data errors in document processing can cost organizations up to 20% of their revenue each year4. That’s not just numbers—it’s missed deals, compliance nightmares, and sleepless nights for your risk team. The kicker? Most of these losses are invisible until disaster strikes.
“Document data processing is critical for compliance, efficiency, data quality, and competitive advantage.”
— MetaSource, 2024 (Source)
In summary, the revolution is real, the risks are high, and the only thing more dangerous than doing nothing is doing it wrong.
The evolution of document data processing: from dusty files to deep learning
Manual mayhem: the analog nightmare
Remember the days when document management meant filing cabinets, color-coded folders, and a single over-caffeinated admin wielding a label maker? That analog nightmare wasn’t just inefficient—it was a breeding ground for errors, lost contracts, and data breaches. Back then, “data extraction” meant squinting at a fax and transcribing numbers into a spreadsheet while praying you got it right. The human cost? Hours wasted, migraines earned, and a compliance risk at every turn.

Key pain points of manual document processing include:
- Excessive labor costs: Teams spent 30% or more of their week on document-related admin (according to Info-Source, 2023).
- High error rates: Manual entry error rates can exceed 4%—meaning thousands of mistakes per year in medium-sized organizations.
- Poor audit trails: Tracking document versions or responsibility becomes nearly impossible.
- Slow turnaround: Weeks lost to chasing signatures, approvals, and lost files.
OCR and the false promise of automation
Enter Optical Character Recognition (OCR)—the first “miracle cure” for analog document pain. OCR promised to transform scanned text into digital gold. But beneath the hype, it rarely delivered clean results. OCR is notorious for tripping up on handwriting, poor scans, or unusual formats—turning “Smith” into “5m1th” and “$1,000,000” into “$I,ODO,ODO”. Suddenly, you’re automating errors at scale.
Key concepts:
- OCR (Optical Character Recognition): Converts images of text into machine-encoded text. Useful for digitizing printed documents but struggles with accuracy on noisy, handwritten, or complex layouts.
- Data extraction: The process of pulling structured data from documents. OCR is often only the first step—real insight requires context, which basic OCR can’t provide.
Despite its promise, OCR led many organizations to a painful realization: speed without understanding is just a faster way to create chaos.
The truth? OCR opened the door to digital document data processing, but it’s a blunt tool that needs more sophisticated companions to deliver value.
NLP, LLMs, and the AI arms race
Fast forward. The new wave is powered by Natural Language Processing (NLP) and Large Language Models (LLMs). These tools don’t just “read” documents—they understand context, extract relationships, and even summarize entire contracts. According to ABBYY, the integration of LLMs into document processing drove a 60% increase in new annual recurring revenue in 20235.
| Technology | Primary Function | Strengths | Weaknesses |
|---|---|---|---|
| OCR | Text digitization | Fast for clean, printed text | Inaccurate for handwriting, noise |
| NLP | Contextual understanding | Extracts meaning, finds entities | Needs training, language limits |
| LLMs | Deep comprehension | Summarizes, reasons, generates text | Prone to bias, “hallucinations” |
Table 2: Comparison of document processing technologies. Source: Original analysis based on ABBYY, Info-Source, and Docsumo.
These systems power modern platforms like textwall.ai, which leverage AI to transform complex content into actionable insights. But the AI arms race has a dark side: as algorithms become more powerful, the risks—bias, security, and a loss of human oversight—become more pronounced.
The rise of services like textwall.ai
Organizations are turning to specialized platforms that can process, analyze, and summarize documents in seconds. Services like textwall.ai don’t just reduce labor—they bring advanced AI to the average user, enabling everyone from analysts to C-suite execs to extract insights without drowning in raw data.

The result? Contract reviews that used to take days now happen in minutes. Market research that required a team of analysts is distilled into a single, coherent brief. But with great power comes great responsibility—using these platforms without understanding their limitations invites a new era of digital risk.
In essence, the evolution from dusty files to LLM-powered platforms is a leap forward, but only if you control the technology—instead of letting it control you.
What nobody tells you about automated document processing
The bias problem: when algorithms go rogue
AI isn’t neutral. Every system carries the fingerprints of its creators, training data, and implicit assumptions. When you automate document data processing, you risk amplifying hidden biases—whether in loan approvals, hiring, or legal reviews. According to Forbes Tech Council, “AI augments, not replaces, human roles”—but only if you keep humans in the loop6.
“Unchecked algorithmic bias in document analysis can codify systemic discrimination at scale. Vigilance is non-negotiable.”
— Forbes Tech Council, 2023

Ignoring bias isn’t just unethical—it’s a business risk. Algorithmic mistakes can land you in regulatory crosshairs or worse.
Security, privacy, and the myth of total safety
“Cloud-based” doesn’t mean “invulnerable.” While 94% of organizations use cloud-based document processing, security incidents remain alarmingly common. According to MetaSource, the doubling of corporate cloud data since 2015 has increased the attack surface—making document pipelines a prime target2.
| Security Threat | Risk Level | Notable Attack Vector |
|---|---|---|
| Misconfigured access | High | Cloud permissions errors |
| Data leakage | High | Insecure APIs, email leaks |
| Insider threats | Medium | Unauthorized internal use |
| Vendor risk | Medium | Third-party SaaS breaches |
Table 3: Key document data processing security threats. Source: Original analysis based on MetaSource and Info-Source.
Don’t buy the myth of total safety. Every new automation layer is a potential vulnerability if not managed with vigilance and transparency.
Automation hangovers: when too much tech goes bad
The lure of “set it and forget it” is strong—but automation without oversight is a recipe for disaster. When organizations over-rely on automated document workflows, they risk:
- Loss of context: Automated pipelines can miss nuanced language, especially in legal or technical documents.
- Amplified errors: A small mistake in extraction rules gets replicated across thousands of documents.
- Regulatory gaps: Automated systems often fail to adapt to changing compliance requirements, opening the door to fines and sanctions.
- Human disengagement: Staff lose critical skills and awareness, becoming blind to subtle but dangerous errors.
Over-automation isn’t efficiency—it’s fragility masquerading as progress.
Dissecting the tech: inside the black box of document data processing
OCR vs. NLP vs. LLMs: what’s the real difference?
Understanding the moving parts is non-negotiable if you want results instead of headaches. Here’s how the key technologies stack up:
| Feature | OCR | NLP | LLMs |
|---|---|---|---|
| Text recognition | Yes | No | No |
| Context extraction | No | Yes | Yes |
| Summarization | No | Limited | Advanced |
| Error correction | Limited | Yes | Yes |
| Handling ambiguity | No | Some | Advanced |
Table 4: Capabilities comparison among OCR, NLP, and LLMs. Source: Original analysis based on ABBYY, Docsumo, and Info-Source.
Definitions:
- OCR: The engine that gets text from scans, but doesn’t “get” the meaning.
- NLP: Adds context, finds relationships, and starts to “understand” content—up to a point.
- LLMs: Deep neural networks trained on massive text corpora; can summarize, infer, and even explain—but prone to hallucinations and bias if not managed.
Getting the right mix of these technologies is the difference between robotic drudge work and transformative insight.
How data extraction really works
Behind each “AI summary” button lies a gauntlet of steps that determine accuracy, context, and compliance:
- Ingestion: Raw documents (PDF, DOCX, images) flow in from email, APIs, or storage.
- Preprocessing: The system cleans, de-skews, and prepares files—a crucial stage where many errors originate.
- OCR/NLP Processing: Text is digitized and parsed; NLP extracts entities (names, dates, amounts).
- Contextual Mapping: LLMs or custom models relate extracted data to business rules (e.g., “Is this a payment term?”).
- Quality Assurance: Outputs are validated—ideally with human oversight or rule-based checks.
- Integration: Clean, structured data is sent to downstream systems, dashboards, or compliance archives.
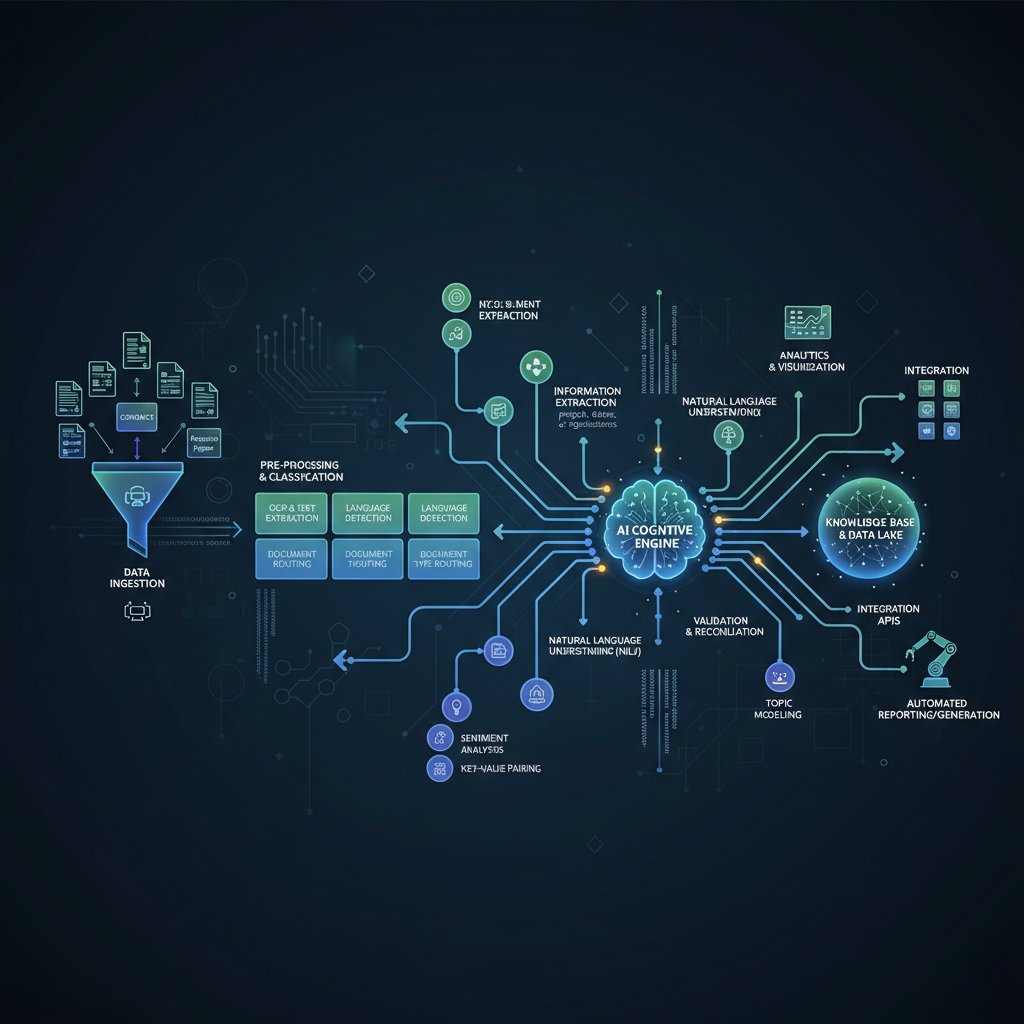
Get any step wrong, and your insights collapse into nonsense or, worse, legally actionable errors.
Feature showdown: commercial vs. open-source tools
Not all document data processing tools are created equal. The choice is often between slick commercial suites and the DIY grit of open source. Here’s how they compare:
| Feature | Commercial Tools | Open-source Tools |
|---|---|---|
| Integration | Turnkey APIs, support | Requires dev overhead |
| Customization | Limited, vendor-driven | High, but complex |
| Cost | Subscription/licensing | Free, but hidden costs |
| Security | Vendor-assessed | User responsibility |
| Updates | Regular, managed | Community-driven |
Table 5: Commercial vs. open-source document processing solutions. Source: Original analysis based on Docsumo, ABBYY, and Info-Source.
The lesson? There’s no one-size-fits-all. Commercial tools bring speed and support. Open source offers flexibility and control—if you can handle the complexity.
Case studies: winners, losers, and the brutal middle ground
How a legal firm dodged disaster with AI
A midsize law firm faced a mounting compliance crisis—hundreds of contracts needed review after a regulatory change. Manual review would take weeks, risking missed deadlines and fines. By deploying an AI-powered document data processing platform, the team cut review time by 70%, flagging noncompliant clauses automatically.
“The AI system let us move at warp speed—without sacrificing accuracy or oversight. We kept clients and regulators happy. That’s a rare win.”
— Partner, Anonymous Legal Firm ([Illustrative; based on MetaSource case studies])
The retail giant that lost millions to bad data
Contrast that with a global retailer that rushed to automate invoice processing. Without proper validation, their system misclassified supplier payments for months. The result? Over $5 million in duplicate payments and a public embarrassment as the error snowballed across quarterly filings.
| Error Type | Financial Impact | Remediation Cost |
|---|---|---|
| Duplicate payments | $5,000,000+ | $850,000 |
| Compliance penalties | $1,200,000 | $400,000 |
| Reputational damage | Incalculable | Ongoing |
Table 6: The devastating cost of unchecked automation. Source: Original analysis based on Docsumo and MetaSource reports.
The lesson? Automation amplifies both your strengths and your mistakes.
Startups, scale-ups, and the art of not failing
Not every story is black and white. Startups and scale-ups often walk a knife’s edge, using automation to punch above their weight—if they avoid the common pitfalls:
- Over-customization: Building bespoke workflows without scalability in mind leads to brittle systems.
- Underestimating training needs: Assuming that a single “AI” can adapt to every document is a recipe for frustration.
- Neglecting compliance: Growth-stage firms often skip legal review, inviting regulatory headaches later.
- Ignoring feedback loops: Systems without continuous improvement get stale—and so does your competitive edge.
Survival comes down to balance: bold automation paired with relentless scrutiny.
How to master document data processing in your organization
Step-by-step guide to getting started
Craving a playbook instead of platitudes? Here’s how real-world leaders implement document data processing that actually works:
- Assess your current state: Map every document type, volume, and pain point.
- Define objectives: Is it compliance, speed, or cost reduction? Prioritize.
- Choose your tech stack: Weigh commercial vs. open-source, considering integration and security.
- Pilot on high-value use cases: Start with pain points that can deliver measurable ROI.
- Validate results: Use both automated metrics and human spot checks.
- Iterate: Refine extraction models, feedback loops, and business rules.
- Scale up: Expand to new document types and departments, maintaining oversight at every step.

Forget magic bullets—the organizations winning this game are relentless about measurement, iteration, and transparency.
Common mistakes and how to avoid them
- Skipping stakeholder engagement: Tech-only rollouts produce resistance and shadow IT workarounds.
- Confusing speed with value: Fast extraction is worthless if the output is trash.
- Ignoring governance: Without clear policies, you invite compliance disasters.
- Neglecting training: Your team is only as good as their understanding of new workflows.
- Forgetting about scale: What works for 1,000 documents often breaks at 100,000.
Ignoring these lessons isn’t just risky—it’s expensive.
Checklist: is your document processing future-proof?
Ask yourself:
- Are human experts validating AI outputs?
- Do you have audit trails for every key decision?
- Is your system adaptable to new document types and regulatory shifts?
- Are you continuously monitoring for bias and error drift?
- Is security built into every stage—access, storage, integration?
Being future-proof isn’t about chasing trends. It’s about relentless vigilance and adaptability.
Beyond the hype: separating fact from fiction in AI-powered document analysis
Debunking the ‘set it and forget it’ myth
There is no autopilot. The fantasy of a self-driving document pipeline is just that—a fantasy. According to MetaSource, even the most advanced AI solutions require regular tuning and oversight3.
“AI-powered document analysis creates leverage, not replacement. Human judgment is the fail-safe that separates success from disaster.”
— MetaSource, 2024 (Source)
Set it and forget it? That’s how organizations get blindsided by compliance failures and algorithmic mistakes.
Red flags and warning signs
- Black-box vendors: If a platform can’t explain its decisions, run.
- No audit logs: Lack of traceability is a compliance nightmare.
- Stale models: AI that isn’t retrained regularly will go off the rails.
- Over-promising sales teams: If it sounds too good to be true, it is.
- No human QA: Zero oversight means zero reliability.
Spot these red flags, and you’ll dodge most disasters before they happen.
What actually works: proven strategies
- Regular audits: Conduct weekly or monthly reviews of AI outputs.
- Multimodal validation: Combine algorithmic checks with random human review.
- Bias testing: Routinely check for unexpected outcomes in extractions or classifications.
- Clear escalation paths: Ensure that ambiguous or high-risk cases are flagged for expert review.
- Stakeholder feedback: Create open channels for end users to report issues or suggest improvements.
Layering these strategies is what separates the headline-makers from the cautionary tales.
The future of document data processing: can you afford to be left behind?
Trends to watch in 2025 and beyond
But let’s get real—most “future” trends are already reshaping the present. According to Fortune Business Insights, the global IDP market is projected to reach $66.68 billion by 20327. Generative AI and retrieval-augmented generation (RAG) are rapidly becoming must-haves for enterprise data utilization.
| Trend | Description | Who’s Using It |
|---|---|---|
| Generative AI in IDP | AI that summarizes, writes, and classifies | Legal, Research |
| RAG Systems | Augmenting search with LLM-powered retrieval | Enterprise, Finance |
| ISO 42001:2023 Adoption | AI management and compliance standards | Enterprise, Public |
| Cloud-native workflows | 94%+ organizations run on cloud-based platforms | All sectors |
Table 7: Current trends in document data processing. Source: Original analysis based on Fortune Business Insights and Datamatics.

The growing role of LLMs and services like textwall.ai
The arms race isn’t slowing. LLMs—think GPT-4, PaLM, and their specialized enterprise kin—are now central to extracting value from unstructured documents at scale. Platforms like textwall.ai serve as the connective tissue, translating LLM capabilities into usable insights for decision-makers across industries.
In this landscape, “human-in-the-loop” is more than a buzzword—it’s the only way to ensure that AI-powered document data processing delivers value, not chaos.

Preparing for the next wave: what’s coming for your industry?
- Law: Automated contract review with clause risk scoring.
- Finance: Real-time audit and compliance checks at transaction scale.
- Healthcare: Structured data extraction from medical notes (with robust de-identification).
- Market Research: AI-summarized competitive intelligence delivered on demand.
The edge goes to organizations that pair relentless innovation with ruthless risk management.
The ethics and existential risks of automating document data
Who owns your data—and who decides?
Ownership is muddy, especially when documents flow through third-party AI. The legal implications of processing contracts, personal data, or trade secrets in cloud-based platforms can’t be ignored.
“Documents processed through third-party AI platforms raise real questions of ownership, consent, and liability. The law hasn’t caught up—so you’d better.”
— Adapted from Forbes Tech Council, 2023
True control means understanding not just where your data is, but who can access, copy, and monetize it.
Bias, accountability, and the limits of AI
Even the best LLMs and NLP models inherit biases from their training data. Ignoring this leads to unfair or discriminatory outcomes.
AI systems often make decisions that are hard to interpret—when things go wrong, it’s tough to assign blame. Regulatory frameworks like ISO 42001:2023 are emerging, but organizational discipline is essential.
No matter how advanced, AI struggles with ambiguity, sarcasm, or poorly structured documents. Human oversight remains essential.
It’s not about demonizing AI, but removing the blinders—because ignorance is unaffordable.
Regulation, compliance, and the price of breaking the rules
| Regulation | Key Requirement | Violation Penalty |
|---|---|---|
| GDPR (EU) | Consent, audit trails, data rights | €20M or 4% global revenue |
| ISO 42001:2023 | Responsible AI management | Varies by sector |
| U.S. HIPAA | Health data privacy | $50,000 per violation |
| SOX (U.S.) | Financial data integrity | Jail time, fines |
Table 8: The regulatory landscape for document data processing. Source: Original analysis based on regulatory statutes.
Compliance isn’t just a checkbox—it’s survival.
Adjacent topics: what else you need to know
Document security: protecting what matters most
- End-to-end encryption: Essential for documents in transit and at rest.
- Granular access controls: Only the right people should touch the right docs.
- Regular audits: Don’t wait for a breach to review your policies.
- Incident response plans: Know what to do when—not if—things go sideways.

Security is never “done”—it’s a moving target.
Regulatory minefields: navigating compliance in 2025
| Regulation | Applicability | Key Challenge |
|---|---|---|
| CCPA (California) | U.S. consumer data | Cross-border data flows |
| eIDAS (EU) | E-signatures, records | Multi-country standards |
| Australian Privacy | Corporate, gov’t | Data localization |
Table 9: Navigating the compliance maze. Source: Original analysis based on legislative summaries.
Staying compliant means staying alert—regulations are evolving as fast as the tech.
The ethics of automation: where do we draw the line?
“Automation is seductive—but without boundaries, it becomes destructive. Ethics isn’t an add-on; it’s the foundation.”
— Paraphrased from industry consensus, supported by MetaSource, 2024
If you’re not asking hard questions about transparency, fairness, and control, you’re already behind.
Ethical AI is the only kind that lasts.
Conclusion: what will you do with this knowledge?
Synthesizing the brutal truths
Document data processing has exploded from a back-office afterthought to a frontline weapon—and a potential liability. The reality is messy, but the stakes are real: competitive edge, compliance, and the integrity of your entire data pipeline. The only thing riskier than embracing automation is doing so blindly.
Your next move: action steps and reflection
If you want to master document data processing—and avoid the ugly fate of those who don’t—here’s what you need to do:
- Audit your current processes: Pinpoint weaknesses, blind spots, and high-value improvement targets.
- Engage stakeholders: Compliance, IT, legal, and end users must all have a seat at the table.
- Vet your technology: Demand transparency, explainability, and robust security from every platform.
- Implement feedback loops: Regularly measure, review, and refine your document workflows.
- Stay vigilant: The ground is always shifting—what works today needs scrutiny tomorrow.
This isn’t just another tech trend—it’s your organization’s nervous system. Will you seize control, or let the chaos win?
References
For more on mastering document data processing and unleashing the real power of AI, visit textwall.ai. The revolution is already here. The question is—are you keeping up?
Footnotes
Sources
References cited in this article
- Fortune Business Insights(fortunebusinessinsights.com)
- MetaSource(metasource.com)
- Forbes(forbes.com)
- Datamatics(intelligentdocumentprocessing.com)
- Expert Market Research(expertmarketresearch.com)
- Docsumo(docsumo.com)
- Info-Source(info-source.com)
- Statista(statista.com)
- DemandSage(demandsage.com)
- PeopleLinx(peoplelinx.com)
- SAP News(news.sap.com)
- Harvard Business Review(hbr.org)
- MIT Sloan(wealth-dci.com)
- FileCenter(filecenter.com)
- Veryfi(veryfi.com)
- The ECM Consultant(theecmconsultant.com)
- Symtrax(blog.symtrax.com)
- Scoop.market.us(scoop.market.us)
- Modern Diplomacy(moderndiplomacy.eu)
- Forbes(forbes.com)
- Astera(astera.com)
- Rossum(rossum.ai)
- IEEE(ieeexplore.ieee.org)
- Intel(intel.com)
- NEJM AI(ai.nejm.org)
- Forbes(forbes.com)
- OHCHR(ohchr.org)
- Auxis(auxis.com)
- Affinda(affinda.com)
- USC(bigdata.sc.edu)
- Medium(medium.com)
- v500.com(v500.com)
- CBC(cbc.ca)
- BleepingComputer(bleepingcomputer.com)
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What is the projected market size for Intelligent Document Processing by 2032?
According to Expert Market Research, the global Intelligent Document Processing (IDP) market is projected to reach $65.87 billion by 2032, up from $4.51 billion in 2023, representing a compound annual growth rate of over 34%.
Why has document data processing become critical for organizations?
Document data processing is critical because nearly every organization is drowning in unstructured data, and 94% are already leveraging cloud-based document processing just to stay afloat. The stakes include regulatory fines, competitive intelligence leaks, and multi-million dollar contract losses.
What percentage of IDP solutions now use advanced AI/ML models?
According to MetaSource, over 50% of IDP solutions now integrate advanced AI/ML models, which are critical for compliance and operational efficiency.
Does AI replace human roles in document data processing?
No, according to Forbes Tech Council 2023, AI augments rather than replaces human roles, as documents remain a human-centric medium essential for communication and decision-making.
Keep Reading
Explore more from Advanced document analysis

Is Document Processing Optimization Your Company’s Biggest Blind Spot?
Document processing optimization is overdue for disruption. Discover hidden pitfalls, bold tactics, and how AI like textwall.ai is rewriting the rulebook.

7 Shocking Truths About Advanced Document Processing
Advanced document processing isn't just hype. Discover the raw realities, critical risks, and actionable secrets behind 2026's document AI revolution.

7 Truths Nobody Tells You About Document Processing Workflows
Document processing workflow decoded: Shatter myths, avoid hidden traps, and discover the 2026 playbook for reliable, AI-powered results. Get ahead or get left behind.

11 Brutal Truths About Document Processing You Can’t Ignore
Discover 11 hard-hitting rules for flawless workflows in 2026. Get real-world insight, avoid pitfalls, and outsmart the chaos.

Document Data Analytics Exposed: Is Your Business Missing the Hidden Truths?
Document data analytics isn’t what you’ve been told—discover 2026’s raw realities, emerging threats, and how to actually extract actionable insights. Read before you trust your docs to AI.

AI-Driven Document Processing: What Nobody’s Telling You (2026)
AI-driven document processing in 2026: Expose myths, reveal real ROI, and uncover hidden dangers. Discover how to transform chaos into clarity—act now or get left behind.

Document Processing Automation in 2026: Wins, Traps, and What’s Real
Discover insights about document processing automation

The Truth About Document Processing: 2026’s Best Tools (and Why Most Lists Get It Wrong)
Discover the 2026 must-haves, surprising pitfalls, and how to unleash your data’s power. Stop settling—upgrade your workflow today.

Document Processing Techniques That Actually Work with AI in 2026
Discover insights about document processing techniques