
Document Data Extraction Automation When It Fails—And How to Win
Behind every slick business dashboard and AI-powered workflow is a dirty secret: enterprise data is still a battlefield of paper, PDFs, and legacy systems. Document data extraction automation, the supposed panacea, is rewriting the rules of the digital economy—just not how you think. As companies pour millions into workflows that promise to liberate knowledge at scale, they’re slammed with hard truths, unexpected meltdowns, and the sobering reality that “automated” doesn’t mean “effortless.” This is an uncompromising look at what works, what fails, and what’s next in the automation arms race. Whether you’re a CTO, an analyst, or just someone watching the relentless march of bots and algorithms, buckle up: you’re about to see the underbelly of document data extraction automation—warts, wonders, and all.
Why document data extraction automation is breaking the business status quo
The legacy nightmare: manual processes in a digital world
Step into almost any office—no matter how “digital-first” the mission statement—and you’ll find the ghosts of manual data entry haunting every corner. Despite decades of tech hype, armies of employees still squint at invoices, contracts, and forms, keying data by hand into sprawling (and error-prone) spreadsheets. According to the IDC, a staggering 80% of enterprise data remains unstructured as of 2023, hiding in emails, scanned documents, and PDFs that resist easy classification. The cost? Not just direct salaries—think overtime, burnout, and the hidden bleed of human error that creeps in after hour six of document slog.

Digital transformation promises salvation, but look closer: even the most “modern” companies patch together brittle RPA bots, macro-laden Excel files, and frantic Slack threads to fill the automation gap. Humans are still the glue—fragile, expensive, and increasingly frustrated. The productivity lost to these manual bridges isn’t just a rounding error. It’s a strategic liability.
| Aspect | Manual Extraction | Automated Extraction | Hidden Risks (Manual) |
|---|---|---|---|
| Cost per Document | $3-$10 | $0.50-$2 | Overtime, rework costs |
| Processing Time | 10-30 minutes | 1-5 minutes | Delays, workflow bottlenecks |
| Error Rate | 2-8% | 0.5-2% | Compliance exposures |
| Data Security | Highly variable | Audit trails available | Data leaks, mishandled docs |
Table 1: Manual vs. automated document data extraction. Source: Original analysis based on IDC, 2023, Forrester, 2023.
The real cost of doing nothing: what’s at stake
It’s tempting to treat document automation as tomorrow’s problem—but inertia is a silent killer. Manual processing isn’t just slow; it’s a minefield for regulatory and compliance failures. In 2022, a mid-sized insurer was hit with a $6 million fine when a single misfiled document cascaded through months of unchecked errors. The root cause? Human fatigue and a lack of process auditability—two hallmarks of manual data handling. These aren’t isolated incidents. As regulations like GDPR and CCPA tighten the screws, the cost of error multiplies. Even late payments due to processing delays can balloon into millions in lost revenue, strained relationships, and blown SLAs.
"Staying manual is a silent killer for business growth." — Alex, corporate transformation lead
The upshot: businesses that cling to manual data extraction are betting against their own survival. The promise of automation isn’t just speed—it’s the chance to unlock insights, protect compliance, and reclaim expertise from the trenches of paperwork.
How automation really works: the guts and glitches of document data extraction
OCR, NLP, LLMs, and RPA: decoding the acronyms
Automation didn’t spring fully formed from the mind of a Silicon Valley engineer. It’s the messy offspring of decades of incremental tech: first came Optical Character Recognition (OCR)—crude, error-prone, but better than squinting at faxes. Then Natural Language Processing (NLP) trudged onto the scene, parsing meaning from context. Today, Large Language Models (LLMs) and Robotic Process Automation (RPA) are the new shock troops, promising to “read” documents, extract actionable data, and even route findings through business logic with minimal human touch.
Essential terms—decoded for real-world impact
The foundational tech that turns scanned images into machine-readable text. Key for digitizing paper, but struggles with handwriting, poor scans, and creative document layouts.
AI algorithms trained to parse syntax, semantics, and context. Essential for teasing meaning from messy, unstructured documents—especially emails and contracts.
Massive neural networks (think: GPT, BERT) that “understand” language with uncanny nuance, enabling contextual extraction, summarization, and classification.
Software “robots” that mimic human actions across systems. Useful for orchestrating extraction, validation, and transfer tasks—though notoriously brittle when systems change.
The umbrella term for solutions blending OCR, NLP, LLMs, and RPA to create end-to-end automated workflows.
The real magic isn’t in any single component, but in the orchestration. Modern automation stacks juggle OCR to digitize, NLP for light parsing, LLMs for deep understanding, and RPA for process execution. The result: a Frankenstein’s monster that, when tuned right, crushes manual throughput—but when misaligned, unravels spectacularly.
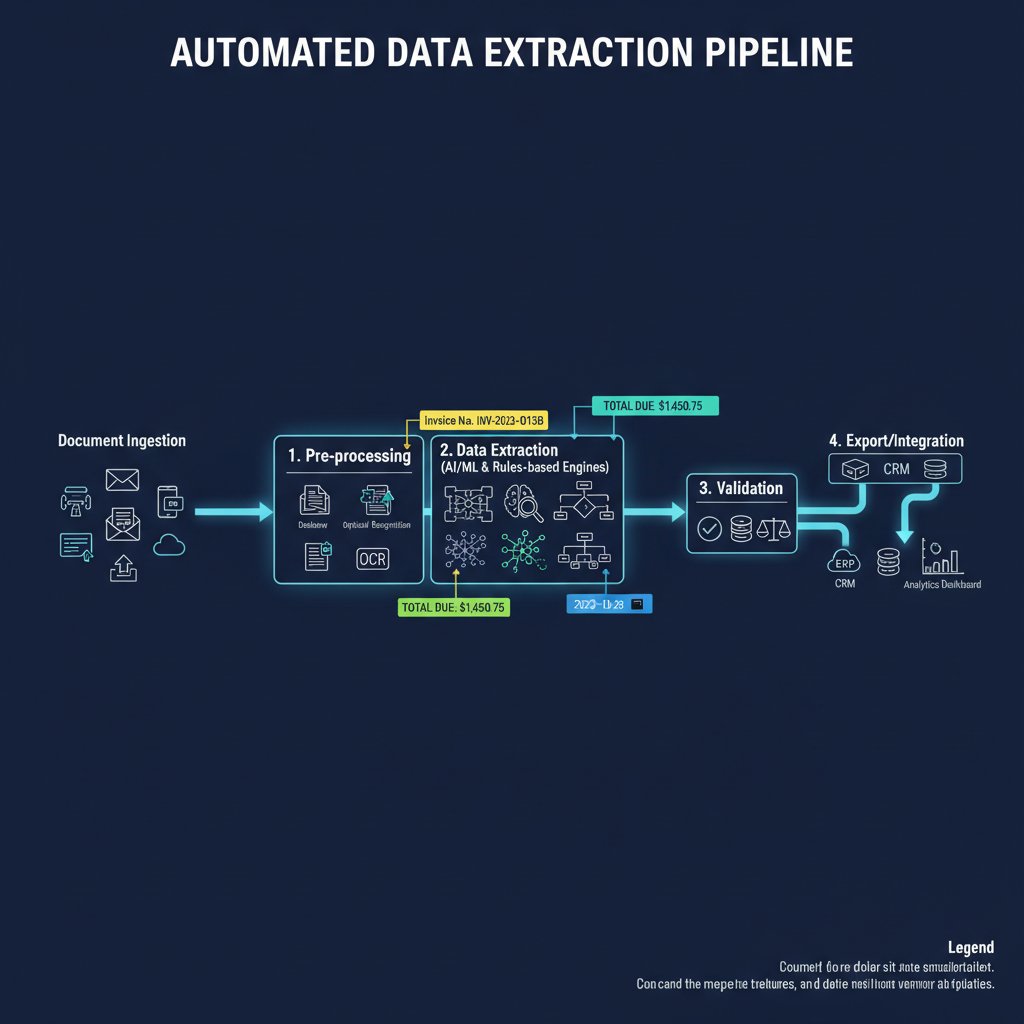
Where the magic dies: why 100% accuracy is a myth
Here’s the uncomfortable truth: even the cleverest AI models stumble. Document layouts shift. Scanned images blur. Contextual nuance—like “net 30” versus “net 10”—can throw LLMs into confusion, especially when data is messy, multilingual, or laden with jargon. According to Forrester, even state-of-the-art extraction cuts errors by up to 70%, but that still leaves a stubborn residue of mistakes.
Hidden benefits of embracing imperfection in automation
- Faster detection of edge cases: Imperfect systems force organizations to identify and address the weird, outlier documents sooner—boosting overall resiliency.
- Continuous learning loops: Regular exceptions push teams to upgrade their models and processes, rather than stagnating.
- Risk awareness: Embracing imperfection builds a culture of regular auditing, which mitigates catastrophic failures.
- Human-machine synergy: Knowing automation isn’t flawless encourages intelligent human oversight, creating a stronger last line of defense.
Automation isn’t about eliminating humans; it’s about redeploying them where nuance and judgment matter most. The best-run organizations build “human-in-the-loop” workflows—escalating edge cases, flagging uncertainties, and documenting exceptions. Perfection is a fantasy. What matters is resilience.

The automation arms race: who’s winning, who’s faking it, and who’s left behind
Big tech vs. open-source: the war for your data
In 2025, document automation is a high-stakes chess match between the titans of proprietary software and the insurgent open-source crowd. Big tech platforms promise seamless integration and glossy interfaces, but often lock customers into expensive, opaque ecosystems. Meanwhile, open-source tools—spurred by communities hungry for control and transparency—are closing the gap, offering customization, peer review, and cost savings. According to Gartner’s “Market Guide for Intelligent Document Processing Solutions,” the decision increasingly hinges on how much customization, data sovereignty, and vendor independence an organization demands.
| Feature | Proprietary Platforms | Open-Source Tools |
|---|---|---|
| Customizability | Limited (vendor driven) | Extensive (user driven) |
| Transparency | Black box models | Open codebase, peer review |
| Cost | High (subscription/lic.) | Low/none, but DIY labor |
| Support | Enterprise-grade, SLAs | Community-based, variable |
| Data Control | Often cloud-hosted | On-prem/self-host options |
Table 2: Proprietary vs. open-source document automation platforms. Source: Original analysis based on Gartner, 2024.
The upshot? Organizations burned by vendor lock-in and privacy scares are switching sides, seeking leverage over their automation destiny.
"Open-source gives us leverage, not just savings." — Jamie, IT director
Industry case files: healthcare, finance, and legal put to the test
No two industries wrestle with document data extraction quite the same way. Healthcare organizations swim in a sea of protected health information (PHI), facing HIPAA, GDPR, and a patchwork of local rules. Automating insurance claims means matching medical codes, flagging anomalies, and preserving bulletproof audit trails—missions where failure is not an option. In finance, extracting invoice data, loan agreements, and contracts demands precision and security under the watchful eye of SOX and PCI-DSS auditors. Even a minor slip—say, a misplaced decimal or a missed signature—can have catastrophic financial consequences.
Legal departments, meanwhile, live and die by document review: e-discovery, contract analysis, compliance audits. Here, the risks of automation gone wrong are existential—think wrongful disclosures, missed clauses, or privilege breaches. No wonder many legal teams treat “AI analysis” with a suspicious squint, insisting on human review for high-stakes documents.

Automation gone sideways: epic failures and the lessons they leave behind
When automation fails: the $10M compliance meltdown
Picture this: a global logistics company rolls out a shiny new automation stack. It promises to process customs forms, shipping manifests, and invoices in record time. For the first three months, things are smooth—until auditors uncover a critical mapping error that’s been misclassifying hazardous materials. The result: a regulatory firestorm, millions in fines, and months of reputation damage. The culprit? A brittle extraction model, unchecked exception handling, and a lack of audit trails.
The failure chain is frighteningly common: data mapping is rushed, oversight is delegated to overworked analysts, and no one checks the logs—until it’s too late.
Step-by-step guide to recovering from automation disaster
- Call a halt: Pause all affected workflows immediately—contain the blast radius before more damage occurs.
- Audit everything: Trace every decision, from model training data to system handoffs, to uncover root causes.
- Engage humans: Pull in cross-functional teams—IT, compliance, operations—to oversee recovery and redesign.
- Patch and validate: Correct mapping errors, strengthen exception handling, and implement robust audit trails.
- Document and learn: Treat the incident as an institutional lesson—update policies, retrain staff, and share findings.
Bridge to risk mitigation: Recovery is possible, but prevention is priceless. Risk-aware automation isn’t just about tech—it’s about culture, vigilance, and relentless curiosity about what could go wrong.
Red flags: warning signs your extraction project is doomed
Even the best tech can’t save a project built on shaky ground. Watch out for these common pitfalls:
- Undefined requirements: Vague goals guarantee scope creep and disappointment.
- Blind trust in vendors: “Set it and forget it” is a recipe for disaster.
- Ignoring subject matter experts: Tech teams alone can’t decipher industry-specific documents.
- Skipping pilot phases: Rolling out at scale before testing edge cases means learning the hard way.
- No escalation plan: Every workflow needs clear handoffs for exceptions—otherwise, errors pile up.
Red flags to watch out for when launching document automation
- Overpromising on 100% accuracy
- Lack of continuous monitoring or audit trails
- No plans for regulatory change updates
- Inadequate training data for extraction models
- Failure to engage business stakeholders early
The fix? Early detection, ruthless prioritization, and a willingness to kill failing projects before they metastasize. For those seeking a general resource on best practices, platforms like textwall.ai gather up-to-date insights from across industries—making them a solid checkpoint for troubled teams.

Beyond the hype: actionable strategies for next-level document data extraction automation
Building your automation stack: what matters in 2025
Forget the vendor slides: real-world automation success hinges on matching tools to real business needs. Start by mapping pain points—where is manual work still bleeding your margins? Choose solutions that fit your document types, complexity, and compliance landscape. Don’t chase the shiniest AI—chase the right fit.
Priority checklist for document data extraction automation implementation
- Define objectives: What business outcomes—cost, speed, quality—are you targeting?
- Assess data landscape: Inventory types, formats, and volumes of documents.
- Evaluate compliance needs: Map out regulatory and audit requirements.
- Select core technologies: OCR vs. LLMs vs. hybrid approaches.
- Plan integrations: Ensure interoperability with existing systems.
- Establish oversight: Build human-in-the-loop processes and exception tracking.
- Pilot, iterate, scale: Start small, refine, and expand with robust change management.
Integration and security are non-negotiable. Prioritize platforms with open APIs, granular user controls, and proven security certifications. Scaling? Don’t just add servers—optimize workflows, eliminate redundancy, and monitor performance relentlessly.

Human + machine: why people still matter in the loop
The dirty secret of automation is that people are still the last mile of trust. Even as AI systems grow more capable, nuanced judgment—spotting intent, context, or outright fraud—remains uniquely human. Augmented intelligence, not full automation, is the winning formula: machines handle the grind, humans handle the gray areas.
"People are the last mile of trust." — Priya, process architect
Building resilient workflows means designing for escalation: when a document defies the model, a human steps in, investigates, and updates the rules. This hybrid approach not only boosts accuracy, but also catches systemic errors before they spiral out of control.
Actionable advice: Train teams to understand both tech and domain context. Incentivize feedback loops—make it easy for humans to flag anomalies and suggest improvements. The result? A system that gets smarter, safer, and more aligned with business reality over time.
The data dilemma: privacy, compliance, and the future of trust
Who owns your data in an automated world?
Data ownership is now a boardroom brawl. As workflows span cloud providers, SaaS platforms, and on-premise databases, the boundaries blur. Regulations like GDPR (Europe), CCPA (California), and LGPD (Brazil) impose strict controls on data use, storage, and transfer. Organizations must track not just who can access data, but where it physically resides and how it’s processed.
A growing regulatory maze means every automation project must map data lineage—who owns each field, who can see it, and how long it’s retained.
| Year | Regulation | Geographic Scope | Key Provisions |
|---|---|---|---|
| 2018 | GDPR | EU | Consent, data portability, right to erasure |
| 2020 | CCPA | California, USA | Consumer opt-out, disclosure, deletion rights |
| 2021 | LGPD | Brazil | Data subject rights, reporting |
| 2023 | CPRA | California, USA | Expanded privacy, enforcement |
Table 3: Timeline of major data privacy regulations impacting document automation. Source: Original analysis based on EU GDPR Portal, 2024, California AG, 2024.
Bridge to security: Compliance is only the start. Security and ethics are now central to the automation conversation.
Security breaches and bias: the unspoken risks
Automated extraction, by its very speed and scale, can amplify data exposure risks. A misconfigured pipeline might accidentally dump confidential files into public buckets. Worse, extraction models can inherit and perpetuate bias—skewing results, reinforcing inequality, and exposing organizations to legal challenges.
How to audit your document automation for risk
- Conduct regular penetration tests focused on document pipelines.
- Audit access logs for unusual or unauthorized document activity.
- Review training data for bias and representativeness.
- Implement red-team exercises to simulate adversarial attacks.
- Map data flows to ensure all regulatory requirements are met.

Show, don’t tell: real-world wins and spectacular stumbles
Case study: how a shipping giant cut processing time by 90%
Consider the case of Monarch Freight, a shipping powerhouse grappling with thousands of customs forms daily. The company rolled out a blended automation stack—leveraging OCR for digitization, LLMs for contextual extraction, and RPA for workflow orchestration. Step by step, they mapped each document type, built exception handling, and trained staff to review flagged cases.
Alternative approaches—outsourcing, manual scaling, or legacy upgrades—were considered but rejected due to cost, scalability, and speed concerns. The result? Processing time dropped from 30 minutes per file to under 3, error rates fell by two-thirds, and compliance auditability soared. The lesson: automation, when rigorously planned and human-augmented, delivers transformative results.

Case study: when AI extraction went off the rails
Contrast with the cautionary tale of a global bank’s failed AI pilot. Eager to extract data from loan documents, leadership rushed deployment—without adequate training data or subject matter expert review. The model misclassified dozens of contracts, triggering regulatory alarms and months of manual rework.
Root causes? Overreliance on vendor claims, lack of human review, and disregard for edge-case complexity.
"We trusted the system more than we trusted ourselves." — Morgan, risk officer
The recovery required rebuilding trust through hybrid workflows and transparent audit trails—proving again that human judgment is the backbone of sustainable automation.
The overlooked realities: environmental, cultural, and human impacts
The carbon cost of automation: is saving trees costing the earth?
Digitization is often sold as an environmental win—less paper, fewer trees felled. But the truth is murkier: vast data centers guzzle power, models require energy-hungry training runs, and every click feeds a growing digital carbon footprint. According to research by the University of Massachusetts, training a single large AI model can emit the carbon equivalent of five cars over their lifetimes.
| Metric | Paper-Based Workflows | Digital Automation |
|---|---|---|
| Annual Paper Use | 10,000–50,000 pages | 1,000–5,000 pages |
| Server Energy (kWh/yr) | ~0 | 5,000–20,000 |
| Carbon Footprint (tons) | 1–2 | 2–8 |
Table 4: Comparison of paper use and server energy consumption in document workflows. Source: Original analysis based on University of Massachusetts Amherst, 2023.
Greener automation is possible: optimize models, use renewable-powered data centers, and only digitize what truly needs digitizing.

Culture shock: how automation is rewriting office life
Automation rewires more than workflows—it reshapes job descriptions, skill requirements, and the meaning of “value-add” work. Data entry clerks retrain as automation analysts. Compliance teams pivot to auditing digital trails. IT becomes the linchpin between business logic and machine learning.
Job transformation is everywhere: document reviewers become workflow designers, while those who resist upskilling risk obsolescence. Yet, new opportunities abound—creative problem solving, data stewardship, and process design are now prized commodities in the age of automation.
Unconventional uses for document data extraction automation
- Automating extraction of market sentiment from earnings call transcripts
- Parsing historical archives for legal research
- Streamlining grant application reviews in academia
- Extracting maintenance data from scanned technical manuals
The future belongs to those who embrace reinvention—wielding automation as a tool, not a threat.
What’s next for document data extraction automation? The 2025-2030 outlook
From LLMs to AGI: what’s hype and what’s real
Every tech conference stage is filled with bold claims about Artificial General Intelligence (AGI) replacing entire departments. Reality check: today’s LLMs are massively powerful, but still bounded by their training data, prone to hallucination, and blind to real-world context unless carefully tuned.
Expert consensus from McKinsey Digital and Gartner: the limits of current AI are real. Models excel at pattern recognition and summarization, but struggle with ambiguous, context-dependent, or highly specialized documents. The smart money is on incremental improvement and tighter human-machine collaboration—not AGI miracles.

How to future-proof your organization—starting now
Automation isn’t a set-it-and-forget-it play. Sustainable success demands vigilance, adaptation, and a willingness to challenge assumptions.
Step-by-step guide to mastering document data extraction automation in 2025 and beyond
- Benchmark current workflows: Identify bottlenecks and quantify manual costs.
- Prioritize high-impact automation targets: Focus on complexity, volume, and compliance risk.
- Vet vendors and tools with ruthless transparency: Demand demos, test edge cases, and insist on auditability.
- Design resilient, hybrid workflows: Build escalation paths, audit trails, and continuous learning loops.
- Invest in people: Upskill teams, foster cross-functional expertise, and incentivize innovation.
- Monitor, measure, and adapt: Regularly review metrics, solicit feedback, and iterate.
- Engage with the broader community: Learn from peers, contribute to open-source, and stay on top of regulatory shifts.
The call to action: Rethink your priorities. Document data extraction automation isn’t just a tech upgrade—it’s a transformation of how organizations see, trust, and wield their most valuable resource: information. Resources like textwall.ai can help connect the dots, but ownership of the journey—and the culture—remains squarely with you.
The final word? Automation is as much about people as it is about code. The path forward is messy, but for those willing to confront the brutal truths, the breakthroughs are within reach.
Supplementary deep-dives: myths, mistakes, and must-knows
Debunked: the most persistent myths about document automation
Myth one: “Automation means no more human involvement.” In reality, every system that works at scale builds in human review. Myth two: “Data extraction = digitization.” Digitization is just converting analog to digital; true extraction means finding structured meaning in the chaos. Myth three: “All AI is the same.” From OCR to LLMs, the tools differ radically in capability and risk.
Similar terms, clarified for the real world
The broad process of collecting information—often via scanning or IoT sensors. Only the first step.
The process of pulling specific, structured data from unstructured sources like PDFs, images, or emails.
Turning analog content (paper, fax) into digital files—without necessarily structuring or interpreting the content.
Myths persist because vendors oversell, buyers under-research, and the distinction between “document scanned” and “data understood” remains muddy. The fix? Get curious—ask tough questions, demand evidence, and never settle for black-box promises.
Mistakes to avoid: learning from the pain of others
Mistake one: Scaling before piloting. A major telco tried to automate all invoices in one go—resulting in months of chaos and manual rework. Mistake two: Ignoring subject matter expertise. A legal firm relied solely on IT to configure extraction rules, missing critical legal caveats. Mistake three: Underestimating compliance. A healthcare provider failed to map GDPR requirements, leading to a costly data breach.
Alternative approaches: Start small, involve end-users early, and layer in compliance from day one.
Checklist for avoiding common document automation errors
- Map requirements and pain points before selecting tools.
- Involve business experts in workflow design and testing.
- Pilot with a small, high-impact use case before scaling.
- Build-in exception handling from the start.
- Audit for compliance, security, and bias at every stage.
Glossary: jargon decoded for the real world
For those swimming in acronym soup, here’s your lifeline.
Converts scanned images of text into machine-readable text—vital for digitizing hardcopy documents.
AI techniques for analyzing and extracting meaning from human language—key for email and contract analysis.
Deep-learning models trained on massive text corpora, powering the most advanced extraction and summarization.
Software bots that mimic repetitive human tasks—bridging legacy systems and new automation.
The convergence of OCR, NLP, LLM, and RPA into unified, end-to-end document workflows.
Conclusion
The hype, heartbreak, and hard-won lessons of document data extraction automation are rewriting the DNA of modern business. As the dust settles, one thing is clear: success isn’t just about deploying the latest AI buzzword. It’s about marrying technical rigor with relentless curiosity, building hybrid workflows that value human insight, and accepting that “automation” is never truly automatic. Armed with brutal truths, breakthrough strategies, and a sharper view of what’s possible, organizations can finally seize the promise hidden in their documents—and outmaneuver the chaos that stalks the status quo. Stay vigilant, challenge the myths, and transform information overload into competitive edge.
Ready to Master Your Documents?
Join professionals who've transformed document analysis with TextWall.ai
Frequently Asked Questions
What percentage of enterprise data remains unstructured according to the article?
According to the IDC, 80% of enterprise data remains unstructured as of 2023, hiding in emails, scanned documents, and PDFs that resist easy classification.
What are the cost differences between manual and automated document extraction?
Manual extraction costs $3-$10 per document and takes 10-30 minutes, while automated extraction costs $0.50-$2 per document and takes 1-5 minutes.
What is the error rate difference between manual and automated document extraction?
Manual extraction has an error rate of 2-8%, while automated extraction has an error rate of 0.5-2%.
Why do companies still rely on manual document data entry despite digital transformation efforts?
Even modern companies patch together brittle RPA bots, macro-laden Excel files, and manual processes because humans remain the glue holding fragmented systems together, making complete automation difficult to achieve.
Keep Reading
Explore more from Advanced document analysis

The Untold Realities of Data Extraction Automation (and Why You Can’t Ignore Them)
Data extraction automation is revolutionizing workflows—yet most guides miss the real risks, payoffs, and secrets. Uncover the truth and future-proof your next move.

Are Document Data Extraction Tools Making You Vulnerable?
Document data extraction tools aren’t what you think. Unmask the realities, avoid costly mistakes, and discover actionable breakthroughs. Read before you choose.

Is Document Extraction Technology Making Us Smarter or Just Faster?
Document extraction technology is rewriting the rules in 2026. Discover the hard truths, hidden pitfalls, and real breakthroughs—plus expert tips you won’t find elsewhere.

Document Content Extraction Solutions: Power, Risk and Reality
Discover insights about document content extraction solutions

Are Your Document Data Extraction Methods Lying to You?
Document data extraction methods get real in 2026—discover game-changing strategies, hidden pitfalls, and why most companies are still doing it wrong. Read before you automate.

Document Processing Automation in 2026: Wins, Traps, and What’s Real
Discover insights about document processing automation

The Dark Side of Document Content Extraction: What You’re Missing
If you think “document content extraction” is just a buzzword for automating boring paperwork, buckle up—because the truth is sharper, messier, and far more

Document Data Extraction Software: What You’re Not Being Told
Unmask the truth behind automation, accuracy, and hidden costs. Discover breakthroughs and avoid the mistakes others regret. Read now.

Are You Ready for the Real Cost of Automated Document Analysis?
Automated document insights extraction tools are disrupting business as usual. Uncover the real risks, hidden benefits, and how to choose wisely in 2026.